ResNet的TensorFlow实现
在实现网络之前,我们首先要对残差网络的实现方法有一定的了解,这里不再过多的赘述。要实现一个网络,最重要的当然是基本框架的搭建了,我们从这张图片来入手resnet的基本框架。

图1
(以101为例,如果没有特别说明,后面默认为Res101网络)不难看出,ResNet101的卷积计算共由5部分组成,其中第一部分很小,只有一个卷积层和一个池化层,主要的计算过程还是集中在其余的四个部分当中。
虽说这张图将网络描述的很清晰,但是以这种表格的形式确实是很难让人理解,在这,我们将它描述的再稍微立体一点。
我们从网络的最基本单元入手,

图2
相信这张图片并不会让人感到陌生,左侧是普通的残差连接的结构,右面的则是bottleneck 结构,我们在实现的时候选取右侧的结构 :
一个ResNet可能有不同的层数,但无论是多少层的残差网络在对输入数据第一次处理时,都需要进行卷积和池化操作来进行预处理(图1 中的conv1执行的就是这个操作)。 例如一个101层的网络就可以表示为2+99,其中2就是预处理,99是余下的卷积层的数目,bottleneck 结构的残差网络由三个卷积层组成,所以共有 99/3 = 33 组(个)残差网络。
看到这里,在翻回来看一下第一张图,貌似就可以理解的更加透彻,更加立体一些了。
那么我们继续:
为了使得数据更加有特征性且更容易分类,我们人为的将余下整个网络分为四部分,分别称之为block1~4; 并规定了第一个block模块和最后一个block模块都只能包含3个残差网络,即3x3 + 3x3 =18 层卷积网络;
余下的block2和block3的残差网络个数分别为4和23,具体为什么是这样,我也就不是很了解了。。。
我们做一下总结,4个block,每个block有3个卷积层,也就是(3+4+23+3)x3 = 99,在加上前面的预处理,正好是101.。。。好了,这下总算搞清楚Res101到底是怎么回事了,在翻回去看一下图1 ,也应该就能顺理成章的了解了。
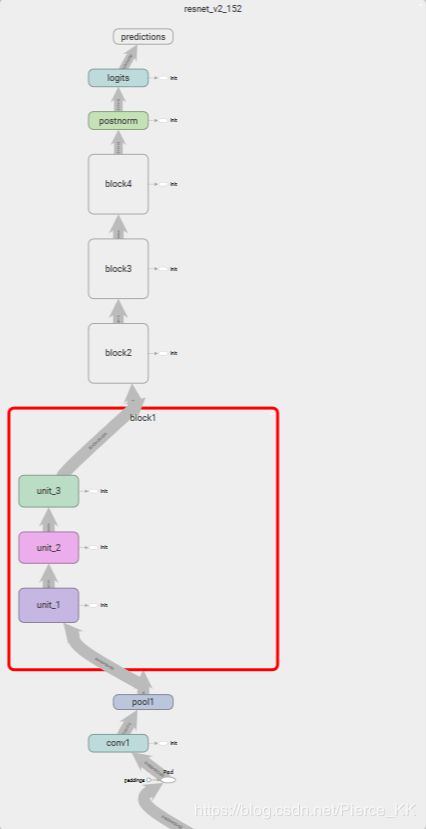 图3
图3
点开这张tensorboard图仔细看一下,你可能会对总体的框架有着进一步的理解。
(未完。。。。)
这里我简单的放一下代码的部分,以后再来进一步解释
# 定义ResNet基本模块组的数据结构
class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
'A named tuple describing a ResNet block'
# 降采样
def subsample(inputs, factor, scope=None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
# 卷积层
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride=1, padding='SAME', scope=scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride, padding='VALID', scope=scope)
# 堆叠Block
@slim.add_arg_scope
def stack_arg_dense(net, blocks, outputs_collections=None):
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net,
depth=unit_depth,
depth_bottleneck=unit_depth_bottleneck,
stride=unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
return net
# 定义ResNet通用的arg_scope
def resnet_arg_scope(is_training=True,
weight_decay=0.0001,
batch_norm_decay=0.997,
batch_norm_epsilon=1e-5,
batch_norm_scale=True):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_scale,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
with slim.arg_scope([slim.conv2d],
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
return arg_sc
# 核心的bottleneck残差学习单元
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride, outputs_collections=None, scope=None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None, scope='shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1, scope='conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride, scope='conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalizer_fn=None, activation_fn=None, scope='conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output)
# 生成ResNet的主函数
def resnet_v2(inputs, blocks, num_classes=None, global_pool=True, include_root_block=True, reuse=None, scope=None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
end_point_collections = sc.original_name_scope + 'end_points'
with slim.arg_scope([slim.conv2d, bottleneck, stack_arg_dense], outputs_collections=end_point_collections):
net = inputs
if include_root_block: # 是否添加最前面的7x7卷积和最大池化层
with slim.arg_scope([slim.conv2d], activation_fn=None, normalizer_fn=None):
net = conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = stack_arg_dense(net, blocks)
net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
if global_pool: # 是否使用最后一层全局平均池化
net = tf.reduce_mean(net, [1, 1], name='pool5', keep_dims=True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, normalizer_fn=None, scope='logits')
end_points = slim.utils.convert_collection_to_dict(end_point_collections)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope='predictions')
return net, end_points
# 152层的ResNet
def resnet_v2_152(inputs, num_classes=None, global_pool=None, reuse=None, scope='resnet_v2_152'):
blocks = [Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(1024, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block=True, reuse=reuse, scope=scope)