阿里、Uber都在用的Flink你了解多少?
实时流计算近几年由于数据被广泛重视,是通过实时推荐及计算来获取目标数据而兴起的技术。本文对分布式实时计算引擎Flink做了简要介绍。本文选自《智能运维:从0搭建大规模分布式AIOps系统》一书。
流式计算处理的业务特点是数据的价值随着时间的流逝而降低,所以提高数据的处理速度及实时性是极其重要的。例如,用户在浏览微博时插入了Feed广告,我们需要对所插入广告的曝光、互动、负反馈等信息进行及时的反馈,这时就需要流式计算。
Flink是一个针对流数据和批数据的分布式处理引擎,主要用Java代码实现。对于Flink ,其处理的数据主要是流数据,批数据只是流数据的一个极限特例而已。Flink的批处理方式采用的是流式计算原理,这一点跟Spark的设计思想正好相反(Spark Streaming本质上是批处理,只是将计算分成了很小的单元,近似成流计算),这也是Flink的最大特点。目前使用Flink的公司有阿里巴巴、Uber等。
基本概念
1.数据集
数据集(DataSet)分为有界数据集和无界数据集。无界数据集的数据会源源不断地流入,有界数据集的数据是不可变的。许多传统上被认为是有界或“批”数据的真实数据集实际上是无界数据集。无界数据集包括但不限于:与移动或Web应用程序交互的最终用户、提供测量的物理传感器、金融市场、机器的日志数据。
2.执行模型
实时处理是指当数据正在生成时连续执行的数据的处理过程。批处理是指在有限的时间内执行有限的数据的处理过程。不管采用哪种类型的执行模型来处理数据都是可以的,但却不一定是最优的。例如,批处理一直被应用于无界数据集的处理上,尽管它存在窗口、状态管理和次序错误等潜在问题。Flink采用实时处理的执行模型,在数据处理精度和计算性能方面都有更大的优势。
3.Flink程序模块
Flink程序包含的主要模块有:Data Source、Transformations和Data Sink。

Flink程序包含的主要模块
其中,Data Source(数据源)就是要进入Flink处理的数据,如HDFS、Kafka中的数据等。Transformations根据实际业务进行计算和转换。Data Sink是Flink处理完的数据,即输出数据。
Flink特点
Flink是一个开源的分布式实时计算框架。Flink是有状态的和容错的,可以在维护一次应用程序状态的同时无缝地从故障中恢复;它支持大规模计算能力,能够在数千个节点上并发运行;它具有很好的吞吐量和延迟特性。同时,Flink提供了多种灵活的窗口函数。
1.状态管理机制
Flink检查点机制能保持exactly-once语义的计算。状态保持意味着应用能够保存已经处理的数据集结果和状态。

Flink的状态管理机制示意图
2.事件机制
Flink支持流处理和窗口事件时间语义。事件时间可以很容易地通过事件到达的顺序和事件可能的到达延迟流中计算出准确的结果。

Flink的事件机制示意图
3.窗口机制
Flink支持基于时间、数目以及会话的非常灵活的窗口机制(window)。可以定制window的触发条件来支持更加复杂的流模式。

Flink的窗口机制示意图
4.容错机制
Flink高效的容错机制允许系统在高吞吐量的情况下支持exactly-once语义的计算。Flink可以准确、快速地做到从故障中以零数据丢失的效果进行恢复。
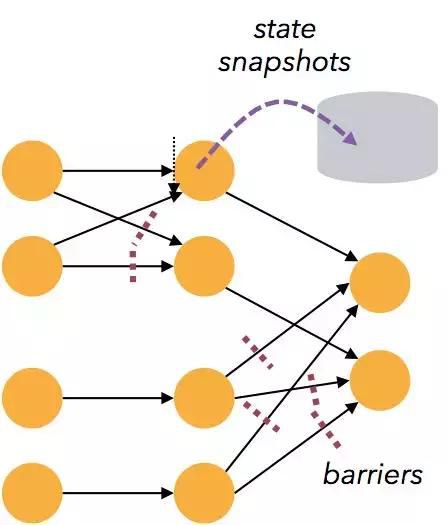
Flink的容错机制示意图
5.高吞吐量、低延迟
Flink具有高吞吐量和低延迟(能快速处理大量数据)特性。下图展示了Apache Flink和Apache Storm完成分布式项目计数任务的性能对比。

Flink与Storm性能对比
6.部署
可以通过Yarn和Mesos等资源管理软件来管理和部署Flink。
运行原理
1.链操作任务
分布式执行Flink的链操作任务,每个任务都由一个线程执行。将操作符链接到任务中是一个有用的优化,其减少了线程间切换和缓冲的开销,并且在降低延迟的同时提高了总体吞吐量。可以配置链接行为,如下图。
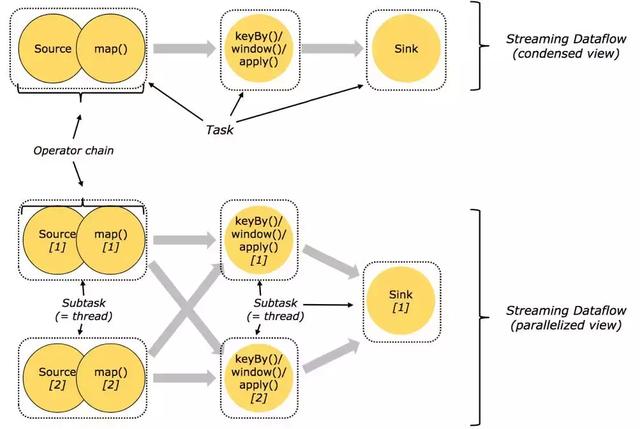
Flink的链操作示意图
2.任务提交
Job Tracker:协调分布式执行—安排任务、协调检查点、协调故障恢复等。为了具有高可用性,设置了多个JobManager,其中一个是领导者,其他的作为备用。
Task Tracker:执行任务(更具体地说,是一个数据流任务)、和缓冲区交换数据流。
Client:客户端用来进行任务调度前期的准备(数据、环境变量等),然后提交计算任务到JobManager。任务提交之后,客户端可以断开连接,也可以继续保持连接以接收进度报告。
3.运行
当Flink集群启动后,首先会启动一个JobManager和一个或多个TaskManager。由客户端提交任务给JobManager,JobManager再调度任务到各个TaskManager来执行,然后TaskManager将心跳和统计信息汇报给JobManager。TaskManager之间以流的形式进行数据传输。

Flink整体流程图(图片来源于Flink官网)
4.任务槽和资源
每个Worker(TaskManager)都是一个JVM进程,并且可以在单独的线程中执行一个或多个子任务。为了控制Worker可以接收多少个任务,Worker有所谓的任务槽(至少一个)。
每个任务槽都代表TaskManager的一个固定资源子集。例如,具有三个插槽的TaskManager将为每个插槽分配1/3隔离的内存资源,这意味着子任务不会与其他作业中的子任务来竞争内存。请注意,目前插槽仅分离托管的任务内存,不会进行CPU的隔离。。
通过调整任务槽的数量,用户可以定义子任务如何彼此隔离。每个TaskManager都拥有一个插槽,这意味着每个任务组都可以在单独的JVM中运行(例如,可以在单独的容器中启动);而拥有多个插槽,则意味着更多的子任务共享相同的JVM。同一个JVM中的任务共享TCP连接(通过多路复用)和心跳消息,它们也可能共享数据集和数据结构,从而减少每个任务的开销。

Flink的任务槽示意图
本文选自《智能运维:从0搭建大规模分布式AIOps系统》,彭冬,朱伟,刘俊等著,电子工业出版社2018年7月出版。

本书结合大企业的智能运维实践,全面完整地介绍智能运维的技术体系,让读者更加了解运维技术的现状和发展。同时,帮助运维工程师在一定程度上了解机器学习的常见算法模型,以及如何将它们应用到运维工作中。
了解本书详情:京东、当当、亚马逊