Apache Storm 编程入门基础(四):Storm 运行和编程架构
编程想要入门,必须知道入门基础所说的运行原理和基本概念,这里就从Storm 例子运行和编程架构说起。
一、Storm 运行
我刚开始学习 storm 也是带着疑问,Storm 程序怎么运行的?运行的结果在哪里显示?我看有人问。
1、Eclipse 的开发环境
我们写程序是在 Eclipse 下,写的 Maven工程文件,也就是要建立 Maven Project, 没有安装 Maven 插件的,需要在 Eclipse 里面,帮助(Help)菜单,安装新软件(Install new software)里安装,当然,你也得下载安装 Maven。
所以,要正确地配置 maven环境。
在 Eclipse 里面的,Preference 里进行配置,Mac OS/X里面就是“偏好设置了”
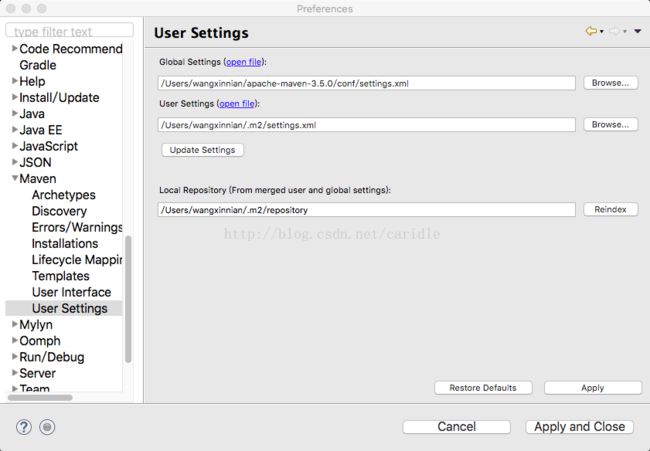
要配置两个全局设置和用户设置。
然后在创建工程的时候,要能找到Maven Project

2、Storm 的 APP JAR 运行
我们最终写的程序就是变成 Jar 程序, 前面(三)说过,Storm 运行有两种模式,一种是本地模式,一种是分布式模式或者是集群模式。
本地模式运行:$ storm jar mywordcount.jar wangxn.MyWordCountTopology.MyCountMain。 就是 storm jar 后面跟随你开发的 jar,然后是类。一般情况下,本地模式运行,类后面都不再加参数,当然,这个要跟你开发的程序有关。
分布式模式运行:$ storm jar mywordcount.jar wangxn.MyWordCountTopology.MyCountMain myCountMain。后面就多了一个参数,myCountMain。因为是在集群里运行,必须指定 Topology 的名字,所以后面跟一个 Topology 的名字,好在运行中观察和区别。
当然,我们一般在调试的时候使用本地模式运行,因为能在控制台上观察和输出你要的结果,但是在分布式模式因为没有控制台信息输出,所以无法观察输出,因为你写的 Topology 已经发送到集群,在后台运行了。
本地模式输出,有两种一种是直接在 Eclipse 安装独立运行模式运行,也就是 Run as (Java Application),控制台输出,一种就是 Export (Jar) 后,在命令行模式下运行。
1)Eclipse 中 Run as (Jave Application)

2)命令行模式下运行

如果在输出的一大堆信息中,你找不到你输出的结果,就需要检查程序了,输出信息一般使用: System.Out.Println 和 System.err.println, 当然,在开发环境中调试使用System.err.println输出,控制台输出字体是红色的,更容易辨别 !
二、程序的逻辑架构图
在(三)中,我们提到 Topology, Spout, Bolt。Storm 运行的就是一个 Topology, 构成 Topology 的就是 Spout 和 Bolt, 这里翻译成中文 就是逻辑拓扑图 ,喷口,螺钉。写程序的人不习惯使用这个中文,还是保留原有的英文词汇更好,毕竟程序猿是中国的,也是世界的!
先看一张图,
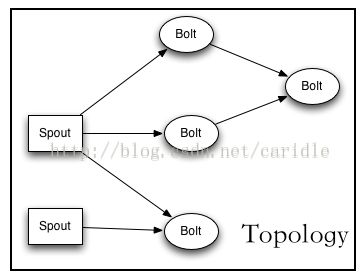
所以,Storm 的程序框架比较简单, 一个是定义 Topology,一个就是定义运行模式。在 Topology中,要定义 Spout,还有要定义 Bolt, 当然,Spout 和 Bolt的数量不只一个,看你 APP 的复杂度了。
1、定义 Topology
TopologyBuilder builder = new TopologyBuilder();
就一句话就搞定了。
2、 再定义 Spout
Spout 就理解开始取数据源,类似交通网络的始发站。在 Topology 中定义的 builder继续设置,使用 setSpout 方法。id 就是标识,第二个参数就是定义的 spout 接口,你必须要去实现,第三个就是并行度了,在(三) 中讲过。
TopologyBuilder.setSpout(String id, IRichSpout spout, Numberparallelism_hint) throws IllegalArgumentException
比如:builder.setSpout("word", new TestWordSpout(), 10);
注意: setSpout 方法会抛出错误,所以,我们在静态 main 方法中要加入 throw Exception。
public static void main(String[] args) throws Exception { }
3、再定义 Bolt
Bolt 就是对发送来的数据进行加工和处理,可以有多个 Bolt。调用方法为:
TopologyBuilder.setBolt(String id, IRichBolt bolt, Numberparallelism_hint) throws IllegalArgumentException
比如:
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
builder.setBolt("exclaim2", new ExclamationBolt(),2).shuffleGrouping("exclaim1");
后面的 shuffleGroup 在(三)中已经讲解过了,不在赘述。
4、定义运行模式
这个运行模式定义,大多数 APP 都是一样的。
直接贴代码:
如果后面有参数,则采用分布式模式,如果没有参数,就是本地运行模式。
Config conf = new Config();
conf.setDebug(false);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(20000);
cluster.killTopology("test");
cluster.shutdown();
}
}所以,这个逻辑流程是固定的。这个逻辑架构流程图大家可以自己画一画
三、Spout 的逻辑架构
在 Eclipse 中,直接新建一个 Class ,命名,然后选择 SuperClass ,点击 Browse,输入Base 搜索,选择 BaseRichSpout,不要选错了哦。

package wangxn.MyWordCountTopology;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
public class TestSpout extends BaseRichSpout {
public TestSpout() {
// TODO Auto-generated constructor stub
}
public void nextTuple() {
// TODO Auto-generated method stub
}
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector arg2) {
// TODO Auto-generated method stub
}
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// TODO Auto-generated method stub
}
}1、open 方法
open 要被先调用的。打开storm系统外的数据源。SpoutOutputCollector 就是 spout 数据源输出收集器,数据就是通过收集器 collector 进行发射。arg1就是topology 的上下文,就是在 topology 中任务存放位置的信息。arg0就是 Map 类型,是 storm 为此 spout 的参数配置,该配置可以和集群配置起作用来运行 Topology。
实现 open 接口很简单,只需要将参数传递给内部属性值即可。如:
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector arg2) {
// TODO Auto-generated method stub
this.conf=arg0;
this.context=arg1;
this.collector=arg2;
}nextTuple 是无参的。该方法被执行的时候,spout 就发射元组到输出收集器 outputCollector。
这是不断执行的,如果没有元组发射就会休眠,不会占用 CPU 等资源,并且是线程安全的操作。
3、declareOutputFields
声明输出字段的名称,只有在输出给Bolt 时才会调用。
例如: arg0.declare(new Fields("data"));
四、Bolt类的逻辑架构
在 Eclipse 中,直接新建一个 Class ,命名SetBolt,然后选择 SuperClass ,点击 Browse,输入Base 搜索,选择 BaseRichBolt,不要选错了哦。
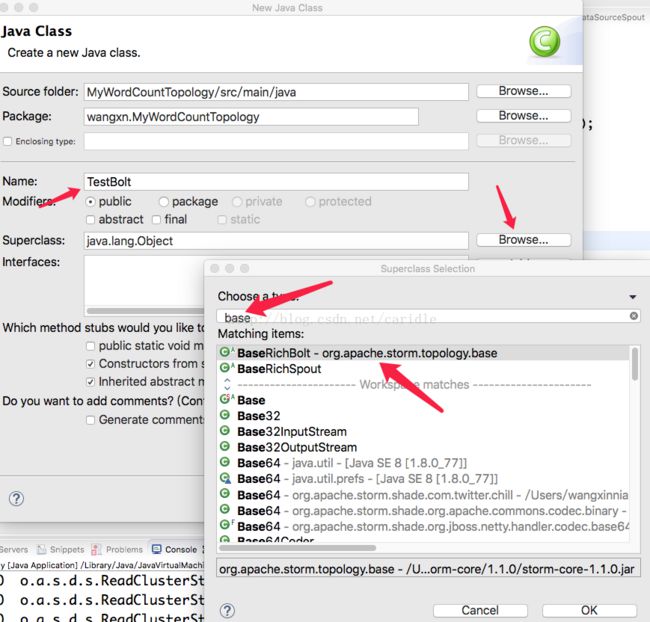
这样就会自动产生程序模板了。
package wangxn.MyWordCountTopology;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
public class TestBolt extends BaseRichBolt {
public TestBolt() {
// TODO Auto-generated constructor stub
}
public void execute(Tuple arg0) {
// TODO Auto-generated method stub
}
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
// TODO Auto-generated method stub
}
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// TODO Auto-generated method stub
}
}execute(Tuple arg0) 处理一个输入的元组的过程。这个元组主要来自其他组件、流和任务。元组的值使用 Turple.getValue 得到。元组处理完毕后,使用 outputCollector 再发射出去。
五、总结
主要是掌握构建拓扑逻辑架构,定义 spout 和 Bolt,最后是定义运行模式。 后面将举几个例子继续说明。