Java面试题数据库篇之mysql VS postgresql
目录
1.综述
2.索引方面
2.1 Postgresql: 单列,多列,唯一,表达式索引,部分索引
2.2 Mysql四大索引:主键,唯一,普通,全文
2.3 mysql索引注意事项
2.4 何时使用聚集索引或非聚集索引
3面向对象方面
3.1 自定义类型create domain,创建具有一定约束的数据类型
3.2 自定义类型create type,创建复合类型,作为函数的返回值
4 多纬数据方面
5 查询优化-大量join
5.1 Postgresql
5.2 Mysql查询优化策略
Nested-loop 算法(简单粗暴,开销太大)
Index nested-loop算法(内表加上索引进行优化,故而使用记录较少的作为外表)
Block Nested-Loop Join(无索引的情况下)
Batched Key Access Join
1.综述
- Postgresql借用了一些面向对象的思维,包括用户自定义对象。表的继承,适用于一些复杂的数据结构,mysql仅仅是纯关系型数据库
- Postgresql在sql合约方面优于mysql
- Postgresql在复杂查询方面进行了优化,在复杂读写操作时性能突出,只读场景不一定
- Postgresql不仅仅自定义了丰富的数据类型,而且支持自定义数据类型
- Postgresql数据库size没有上限,不考虑系统性能影响的前提下,单表尺寸上限32T,单个字段尺寸可以存储上G的数据
- Mysql默认隔离级别是可重复读,Postgresql的默认隔离级别是读已提交,sql,oracle也是读已提交
2.索引方面
2.1 Postgresql
- btree,适合任意单值类型,可用于
=, >, <, >=, <=以及排序。选择性越好(唯一值个数接近记录数)的列,越适合b-tree。当被索引列存储相关性越接近1或-1时,数据存储越有序,范围查询扫描的HEAP PAGE越少。 - hash,当字段超过单个索引页的1/4时,不适合b-tree索引。如果业务只有
=的查询需求,使用hash index效率更高。 - gin,倒排存储,(column value: row IDs tree|list)。适合多值列,也适合单值列。例如数组、全文检索、JSON、HSTORE等类型。多值列搜索:包含、相交、不包含。单值列搜索:等值。适合多列组合索引(col1,col2,coln),适合任意列组合搜索。目前gin索引仅支持bitmap scan(按heap page id顺序搜索)。
- gist,适合数据有交错的场景,例如 全文检索、range类型、空间类型(点、线、面、多维对象... ...)。
- sp-gist,空间分区索引类型,适合不平衡数据集(例如xxxyyyzzz??????组成的VALUE,xxx, yyy, zzz,每个值包含一些数据集,每个数据集的数据量不平衡可能导致TREE不平衡)。sp-gist索引结构,可以用于解决此类不平衡数据的倾斜问题。
- brin,块级索引,记录每个或每连续N个数据块的数据边界。BRIN适合单值类型,当被索引列存储相关性越接近1或-1时,数据存储越有序,块的边界越明显,BRIN索引的效果就越好。BRIN支持多列、单列。BRIN适合搜索一个范围的数据。目前只支持BITMAP扫描方式(按heap page id顺序搜索)。
- bloom,支持被索引字段的任意组合的等值搜索。
- rum,支持全文检索类型,支持单值列+全文检索列,支持近似文本搜索。
- zombodb,PG与ES搜索引擎结合的一种索引,在PG数据库中透明使用ES。
- bitmap,支持1000~10000个唯一值的列。适合多个值的 与或 条件搜索。
- varbitx,阿里云RDS PG提供的一种BIT类型管理插件,支持BIT的设置,搜索等操作。
- 部分索引,只检索部分列。在索引中过滤不需要被搜索,不适合建立索引的行。
- 表达式索引,对于不同的搜索条件,支持使用表达式索引提高查询速度。例如函数索引。
- 多索引bitmap合并扫描,多个索引可以使用BITMAP SCAN合并扫描。例如两个条件与搜索,使用BITMAP SCAN,可以跳过不需要扫描的数据块。
单列,多列,唯一,表达式索引,部分索引
GiST(通用搜索树), SP-GiST(空间分割-通用搜索树)(mysql不同) and GIN(通用倒排索引,实现全文检索)
Gist索引适用于多维数据类型和集合数据类型,和Btree索引类似,同样适用于其他的数据类型。和Btree索引相比,Gist多字段索引在查询条件中包含索引字段的任何子集都会使用索引扫描,而Btree索引只有查询条件包含第一个索引字段才会使用索引扫描。
包括九种索引,Btree索引,hash索引。hash索引经常用在value比较大大情况下进行等值查询。
而且支持表达式索引和部分索引,举例如下:
表达式索引:
select * from tbl_expression where upper(a) = 'TEST';
select * from tbl_expression where (a || ' ' ||b) = 'test you';
test=# create index idx_tbl_expression_a_b on tbl_expression ((a||' '||b));
CREATE INDEX
test=# create index idx_tbl_expression_a_b on tbl_expression upper(a)
部分索引:
test=# create index idx_tbl_partial_index1_level on tbl_partial_index1(level) where level = 'red';
CREATE INDEX
2.2 Mysql四大索引:主键,唯一,普通,全文
mysql大部分索引,主键,普通索引,唯一索引都是Btree结构,只有少部分空间数据用Rtree。mysql也支持hash索引,innodb引擎利用倒排列表实现全文索引
主键索引:
普通索引:
CREATE INDEX index_name ON table(column(length))
唯一索引:
CREATE UNIQUE INDEX indexName ON table(column(length))
全文索引:
MyISAM支持全文索引,InnoDB在mysql5.6之后支持了全文索引。全文索引不支持中文需要借sphinx(coreseek)或迅搜<、code>技术处理中文。
2.3 mysql索引注意事项
- MySQL只对一下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。
- 索引不会包含有NULL值的列
- 对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作
- MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
- 不要在列上进行运算
2.4 何时使用聚集索引或非聚集索引
索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
| 列经常被分组排序 | 使用 | 使用 |
| 返回某范围内的数据 | 使用 | 不使用 |
| 一个或极少不同值 | 不使用 | 不使用 |
| 小数目的不同值 | 使用 | 不使用 |
| 大数目的不同值 | 不使用 | 使用 |
| 频繁更新的列 | 不使用 | 使用 |
| 外键列 | 使用 | 使用 |
| 主键列 | 使用 | 使用 |
| 频繁修改索引列 | 不使用 | 使用 |
3面向对象方面
3.1 自定义类型create domain,创建具有一定约束的数据类型
CREATE TABLE mail_list (
ID SERIAL PRIMARY KEY,
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
email VARCHAR NOT NULL,
CHECK (
first_name !~ '\s'
AND last_name !~ '\s'
)
);
CREATE DOMAIN contact_name AS
VARCHAR NOT NULL CHECK (value !~ '\s');
CREATE TABLE mail_list (
id serial PRIMARY KEY,
first_name contact_name,
last_name contact_name,
email VARCHAR NOT NULL
);
创建数据类型contact name,含义是不许为空,且不包含空格
3.2 自定义类型create type,创建复合类型,作为函数的返回值
CREATE TYPE film_summary AS (
film_id INT,
title VARCHAR,
release_year YEAR
);
CREATE OR REPLACE FUNCTION get_film_summary (f_id INT)
RETURNS film_summary AS
$$
SELECT
film_id,
title,
release_year
FROM
film
WHERE
film_id = f_id ;
$$
LANGUAGE SQL;
SELECT
*
FROM
get_film_summary (40);
4 多纬数据方面
4.1 Mysql空间索引
CREATE TABLE tb_geo(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(128) NOT NULL,
pnt POINT NOT NULL,
SPATIAL INDEX `spatIdx` (`pnt`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
DESCRIBE tb_geo;
INSERT INTO `tb_geo` VALUES(
NULL,
'a test string',
POINTFROMTEXT('POINT(15 20)'));
SELECT id,NAME,ASTEXT(pnt) FROM tb_geo;
SELECT id,NAME,X(pnt),Y(pnt) FROM tb_geo;
SELECT ASTEXT(pnt) FROM tb_geo WHERE MBRWITHIN(pnt,GEOMFROMTEXT('Polygon((0 0,0 30,30 30,30 0,0 0))'));
DROP TABLE tb_geo;
SET @g1 = GEOMFROMTEXT('Polygon((0 0,0 3,3 3,3 0,0 0))');
SET @g2 = GEOMFROMTEXT('Point(1 1)');
SELECT MBRCONTAINS(@g1,@g2), MBRCONTAINS(@g2,@g1), MBRCONTAINS(@g1,@g1);
SELECT MBRWITHIN(@g2,@g1),MBRWITHIN(@g1,@g2);
SELECT MBRDISJOINT(@g1,@g2);
SELECT MBREQUAL(@g1,@g2);
SELECT MBRINTERSECTS(@g1,@g2);
SELECT MBROVERLAPS(@g1,@g2);
SELECT MBRTOUCHES(@g1,@g2);
在最新发布的MySQL 5.7.4实验室版本中,InnoDB存储引擎新增了对于几何数据空间索引的支持。
在此之前,InnoDB将几何数据存储为BLOB(二进制大对象)数据,在空间数据上只能创建前缀索引,当涉及空间搜索时非常低效,尤其是在涉及复杂的几何数据时。在大多数情况下,获得结果的唯一方式是扫描表。
新版本MySQL中,InnoDB支持空间索引,通过R树来实现,使得空间搜索变得高效。
InnoDB空间索引也支持MyISAM引擎现有的空间索引的语法,此外,InnoDB空间索引支持完整的事务特性以及隔离级别。
目前,InnoDB空间索引只支持两个维度的数据,MySQL开发团队表示有计划支持多维。此外,开发团队正在做更多关于性能方面的工作,以使其更加高效
5 查询优化-大量join
5.1 Postgresql
Postgresql使用的是动态规划和遗传算法这两种策略。
(1)动态规划算法
在postgresql里,默认的是使用动态规划算法来获得最优路径的。关于动态规划方法,网上的介绍很多,原理我就不介绍了。在postgresql里使用的步骤如下:
1)初始状态。在初始状态下,为每一个待连接的baserel生成基本关系访问路径,选出最优路径。这些关系成为第一层中间关系。把所有n个中间关系连接生成的的中间关系成为第n层关系;
2)归纳阶段。已知第1~n-1层关系,用下列方法生成第n层关系:
-
a.将第n-1层关系与每个第i层的关系连接,计算当前的最优连接方法(1 <= i <= n/2);
-
b.从以上结果中选择代价最小的连接顺序作为第n层的路径.
3)在生成的第n层关系里,选取最优的连接方法输出。
在计算时,由于连接的顺序和连接的方法都会直接或间接的影响查询执行时的磁盘I/O和CPU时间。因此在生成路径时需要同时考虑这两个因素,计算总代价。在postgresql中,代价的计算是自底向上的。因此在具体实现时保留当前的最优路径供上层节点使用。而最优路径无法精确判断,那么在每层节点中的RelOptInfo结构中都有cheapest_path、cheapest_total_path、cheapest_unique_path。分别代表启动代价最优路径、总代价最优路径和最优唯一路径。这些路径供上层比较选用。
(2)遗传算法
遗传算法是一种启发式的搜索算法,在解空间很大的情况下,能够在一个合理的时间里获得一个"较优"的解。关于遗传算法的具体实现这里就不多说了,网上大把的例子和教程。这里提到遗传算法是因为它是作为对动态规划算法的补充。动态规划算法很好,能总是获得最优解。但是其算法时间复杂度比较高。尤其在基本关系数比较多的情况下,计算量会非常大,无法在合理的时间里获取查询规划。这里说极端点,假如我为了使查询时间节省了1秒而在获取最优查询规划时多花了十几秒这显然是得不偿失的。因此,这里有一个效率和准确度上的权衡。一般在基本关系超过阈值(默认值12)时,系统就开始使用遗传算法来生成路径。在配置文件里有两个参数来控制。一个是enable_geqo,用来设置是否允许使用遗传算法;另一个是geqo_threshold,用来控制阈值的大小。
5.2 Mysql查询优化策略
-
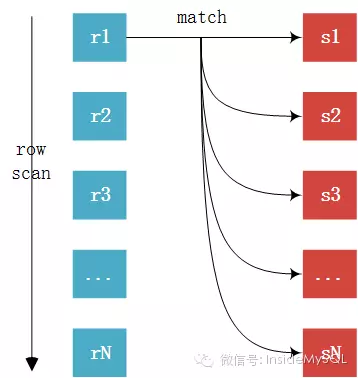
Nested-loop 算法(简单粗暴,开销太大)
For each row r in R do
Foreach row s in S do
If r and s satisfy the join condition
Then output the tuple
-
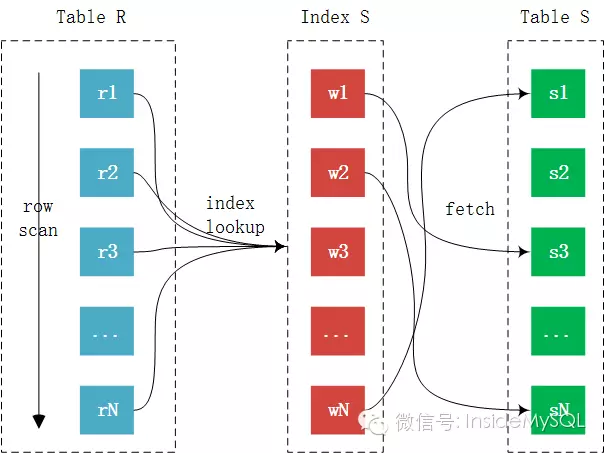
Index nested-loop算法(内表加上索引进行优化,故而使用记录较少的作为外表)
For each row r in R do
lookupr in S index
if found s == r
Then output the tuple

这样性能能够达到预期吗?如果内表访问的是主键索引,也就是聚集索引,性能能够满足,但是如果不是主键索引呢?
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大的弊端。所以说,INLJ最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上
-
Block Nested-Loop Join(无索引的情况下)
在有索引的情况下,MySQL会尝试去使用Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL的选择绝对不会是最先介绍的Simple Nested-Loop Join算法,因为那个算法太粗暴,不忍直视
For each tuple r in R do
store used columns as p from R in join buffer
For each tuple s in S do
If p and s satisfy the join condition
Then output the tuple
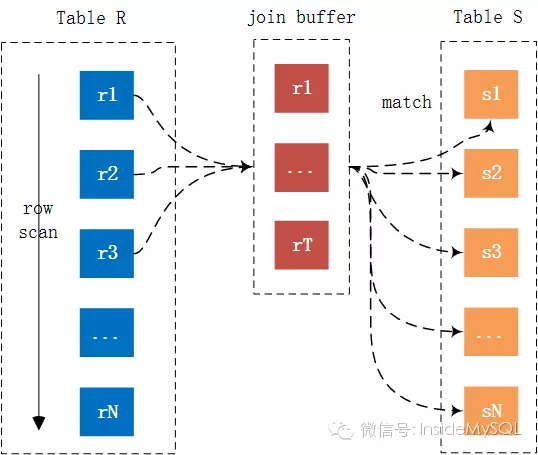
可以看到Join Buffer用以缓存链接需要的列,然后以Join Buffer批量的形式和内表中的数据进行链接比较。就上图来看,记录r1,r2 … rT的链接仅需扫内表一次,如果join buffer可以缓存所有的外表列,那么链接仅需扫描内外表各一次,从而大幅提升Join的性能。
“所有参与查询的列”都会保存到Join Buffer,而不是只有Join的列。最后,Inside君调试了MySQL,在sql_join_buffer.cc文件中验证了这个结果。
比如下面的SQL语句,假设没有索引,需要使用到Join Buffer进行链接:
| SELECT a.col3 FROM a,b WHERE a.col1 = b.col2 AND a.col2 > …. AND b.col2 = … |
假设上述SQL语句的外表是a,内表是b,那么存放在Join Buffer中的列是所有参与查询的列,在这里就是(a.col1,a.col2,a.col3)。
通过上面的介绍,我们现在可以得到内表的扫描次数为:
| Scaninner_table = (Rn * used_column_size) / join_buffer_size + 1 |
对于有经验的DBA就可以预估需要分配的Join Buffer大小,然后尽量使得内表的扫描次数尽可能的少,最优的情况是只扫描内表一次。
-
Batched Key Access Join
在说明Batched Key Access Join前,首先介绍下MySQL 5.6的新特性mrr——multi range read。这个特性根据rowid顺序地,批量地读取记录,从而提升数据库的整体性能。mrr的优化在于,并不是每次通过辅助索引读取到数据就回表去取记录,而是将其rowid给缓存起来,然后对rowid进行排序后,再去访问记录,这样就能将随机I/O转化为顺序I/O,从而大幅地提升性能。
然而,在MySQL当前版本中,基于成本的算法过于保守,导致大部分情况下优化器都不会选择mrr特性。
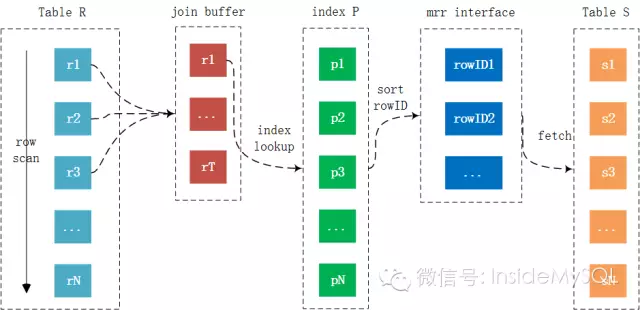
然而,这么好的特性,却是在MySQL中默认关闭的!!!这可能是导致用户认为MySQL Join性能比较差的一个原因。若要使用BKA Join,务必执行下列的SQL语句:
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
Query OK, 0 rows affected (0.00 sec)
mysql优化器算法摘自:
https://mp.weixin.qq.com/s?__biz=MjM5MjIxNDA4NA==&mid=205923864&idx=1&sn=63b97a02def11c3e4fceb67d25c79628&scene=21#wechat_redirect