架构师进阶之九Nginx架构分析
Nginx概述
简单复习一下什么是nginx,nginx是一个反向代理服务器,不同于我们平时为了访问某个网址设置对代理,那个是正向代理。反向代理,请求访问反向代理地址,反向代码寻址目的地址然后返回给请求方,但是请求方并不知道请求对处理方。这样设计的好处在于:
- 保护服务器隐私
- 实现负载均衡
- 集中控制请求
- 缓存资源,减少真是服务器的压力
- 节省ip资源
- 解决Ajax跨域问题
- 区分动态资源和静态资源
Nginx的几大特性:
- 模块化
- 多进程单线程
- 异步
- 非阻塞IO
- 事件驱动
Nginx配置文件
通过nginx配置文件,我们发现以下几点:
- nginx是多进程单线程模式,进程数可以设置,根据cpu核数计算
- 事件监听模式可以选择,linux是epoll,当然还有其他select,kqueue等。
- 每个worker进程的最大并发连接数可以通过worker_connections设置,总的并发数=worker数*worker_connections/4
- 静态文件过期时间设置
- 请求转发处理
#运行用户
user nobody;
#启动进程,通常设置成和cpu的数量相等
worker_processes 1;
#全局错误日志及PID文件
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
#工作模式及连接数上限
events {
#epoll是多路复用IO(I/O Multiplexing)中的一种方式,
#仅用于linux2.6以上内核,可以大大提高nginx的性能
use epoll;
#单个后台worker process进程的最大并发链接数
worker_connections 1024;
# 并发总数是 worker_processes 和 worker_connections 的乘积
# 即 max_clients = worker_processes * worker_connections
# 在设置了反向代理的情况下,max_clients = worker_processes * worker_connections / 4 为什么
# 为什么上面反向代理要除以4,应该说是一个经验值
# 根据以上条件,正常情况下的Nginx Server可以应付的最大连接数为:4 * 8000 = 32000
# worker_connections 值的设置跟物理内存大小有关
# 因为并发受IO约束,max_clients的值须小于系统可以打开的最大文件数
# 而系统可以打开的最大文件数和内存大小成正比,一般1GB内存的机器上可以打开的文件数大约是10万左右
# 我们来看看360M内存的VPS可以打开的文件句柄数是多少:
# $ cat /proc/sys/fs/file-max
# 输出 34336
# 32000 < 34336,即并发连接总数小于系统可以打开的文件句柄总数,这样就在操作系统可以承受的范围之内
# 所以,worker_connections 的值需根据 worker_processes 进程数目和系统可以打开的最大文件总数进行适当地进行设置
# 使得并发总数小于操作系统可以打开的最大文件数目
# 其实质也就是根据主机的物理CPU和内存进行配置
# 当然,理论上的并发总数可能会和实际有所偏差,因为主机还有其他的工作进程需要消耗系统资源。
# ulimit -SHn 65535
}
http {
#设定mime类型,类型由mime.type文件定义
include mime.types;
default_type application/octet-stream;
#设定日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;
#sendfile 指令指定 nginx 是否调用 sendfile 函数(zero copy 方式)来输出文件,
#对于普通应用,必须设为 on,
#如果用来进行下载等应用磁盘IO重负载应用,可设置为 off,
#以平衡磁盘与网络I/O处理速度,降低系统的uptime.
sendfile on;
#tcp_nopush on;
#连接超时时间
#keepalive_timeout 0;
keepalive_timeout 65;
tcp_nodelay on;
#开启gzip压缩
gzip on;
gzip_disable "MSIE [1-6].";
#设定请求缓冲
client_header_buffer_size 128k;
large_client_header_buffers 4 128k;
#设定虚拟主机配置
server {
#侦听80端口
listen 80;
#定义使用 www.nginx.cn访问
server_name www.nginx.cn;
#定义服务器的默认网站根目录位置
root html;
#设定本虚拟主机的访问日志
access_log logs/nginx.access.log main;
#默认请求
location / {
#定义首页索引文件的名称
index index.php index.html index.htm;
}
# 定义错误提示页面
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
#静态文件,nginx自己处理
location ~ ^/(images|javascript|js|css|flash|media|static)/ {
#过期30天,静态文件不怎么更新,过期可以设大一点,
#如果频繁更新,则可以设置得小一点。
expires 30d;
}
#PHP 脚本请求全部转发到 FastCGI处理. 使用FastCGI默认配置.
location ~ .php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
#禁止访问 .htxxx 文件
location ~ /.ht {
deny all;
}
}
}
}
Nginx架构分析

- Master进行负责解析配置文件,根据配置文件的worker设置启动worker进程处理请求,另外,负责热部署,热部署的时候master根据新的配置文件生成worker进行,原有的worker处理完后就kill掉
- Matser fork出worker进程,所以worker进程和mater进程需要相同的配置,监听相同的socket FD
- 当有一个请求过来时,所有的worker都监听这个端口,会产生“惊群现象”。所以nginx设置了一个进程之间的互斥锁,保证只有一个进程注册事件成功。一个请求其实只要心worker进程就可以处理完成。
- 进程模型优势:彼此独立不影响,不涉及并发锁操作。单独利用多进程模式,会导致并发连接数降低,因为每个进程都要占用一个socket,
- worker进行采用epoll方式处理请求,代码大致如下:
poll_create 创建一个epoll对象,一般epollfd = epoll_create()
epoll_ctl (epoll_add/epoll_del的合体),往epoll对象中增加/删除某一个流的某一个事件。比如
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);//注册缓冲区非空事件,即有数据流入
epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);//注册缓冲区非满事件,即流可以被写入
epoll_wait(epollfd,...)等待直到注册的事件发生
一个epoll模式的代码大概的样子是:
while true {
active_stream[] = epoll_wait(epollfd)
for i in active_stream[] {
read or write till
}
}
我来解释一下,请求过来,这个请求可能读数据,可能写数据,IO可能阻塞。所以IO请求来了以后,通过epoll_create创建一个epollfd对象,其实就是要监听的连接的文件描述符(FD),然后注册FD对象和需要监听的事件,epoll_wait函数,等有关心的事件发生,比如数据可以读取,或者数据可以写入的时候,epoll_wait能够返回可用事件的fd对象,这个是不需要循环遍历所有FD就可以得到的。epoll相比select和poll的改进是,由于I/O事件发生,内核将活跃的socket放入队列并交给mmap加速到用户空间,程序拿到的集合是处于活跃的socket集合,而不是所有socket集合
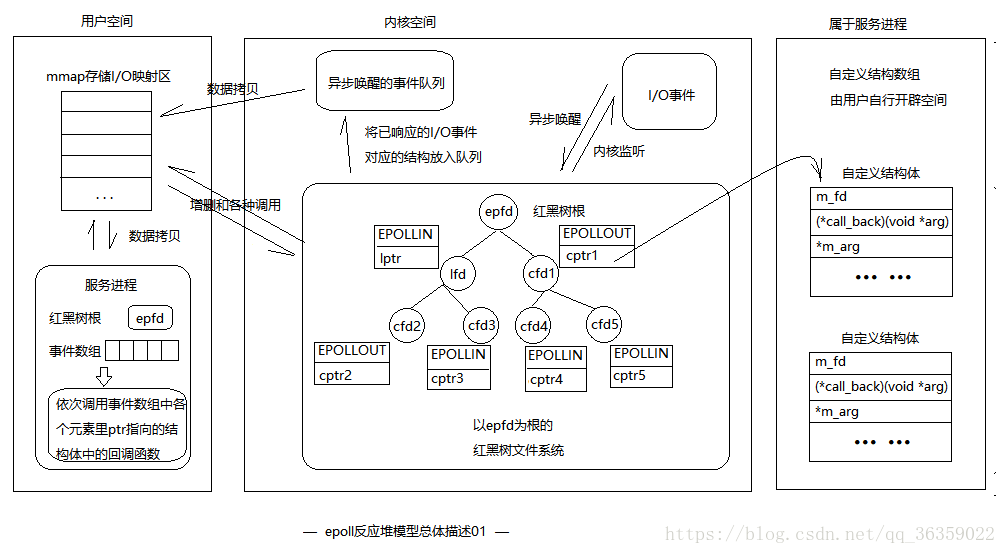
图片来自https://blog.csdn.net/qq_36359022/article/details/81355897
我的理解
根据上面的分析,我们梳理一下,大并发场景下,nginx究竟是如何利用多线程,异步IO,事件驱动达到处理大量连接的。先澄清一个很容易混淆的问题,socket连接和端口是上面关系?如果有一个socke连接连到80端口,还可以有其他socket连接到80端口码?当然可以。
一个连接的唯一标识是[server ip, server port, client ip, client port]也就是说。操作系统,接收到一个端口发来的数据时,会在该端口,产生的连接中,查找到符合这个唯一标识的并传递信息到对应缓冲区。
1.一个端口同一时间只能bind给一个SOCKET。就是同一时间一个端口只可能有一个监听线程(监听listen之前要bind)。
2.为什么一个端口能建立多个TCP连接,同一个端口也就是说 server ip和server port 是不变的。那么只要[client ip 和 client port]不相同就可以了。能保证接唯一标识[server ip, server port, client ip, client port]的唯一性。