预测&分类波士顿犯罪
Crime in Boston
kaggle上对波士顿的案件分析(作者很懒,只上传了一部分)
数据源:https://www.kaggle.com/ankkur13/boston-crime-data
一:基本信息查看
#导入数据模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#加载数据
df=pd.read_csv(r"C:\Users\willow\Desktop\boston-crime-data\crime.csv",encoding="gbk")
df.head()
df.describe()
#lat和long数据存在问题
df=df.loc[(df['Lat']>35)&(df['Long']<-55)]
#查看每列空值数量
df.isnull().sum()
#查看数据信息
df.info()
#将字符型转换为数值型
df['REPORTING_AREA']=pd.to_numeric(df['REPORTING_AREA'],errors='coerce')
#不重复分类计数
for i in df.columns:
print(i,len(df[i].unique()))
#每一特征类别
columns=['OFFENSE_CODE','OFFENSE_CODE_GROUP','DISTRICT','SHOOTING','YEAR', 'MONTH', 'DAY_OF_WEEK', 'HOUR', 'UCR_PART']
for j in columns:
print('----------------------------------')
print(j,df[j].unique())
print("----------------------------------")
二、数据预处理(略)
三、Cluster
loca= df[['Lat','Long']]
loca= loca.dropna()
loca.isnull().sum()
X=loca['Long']
Y=loca['Lat']
from sklearn.cluster import KMeans
loca=loca[~np.isnan(loca)]
KM=KMeans(6)
KM.fit(loca)
clus_pre=KM.predict(loca)
cent=KM.cluster_centers_
kmeans=pd.DataFrame(clus_pre)
loca.insert((loca.shape[1]),"kmeans",kmeans)
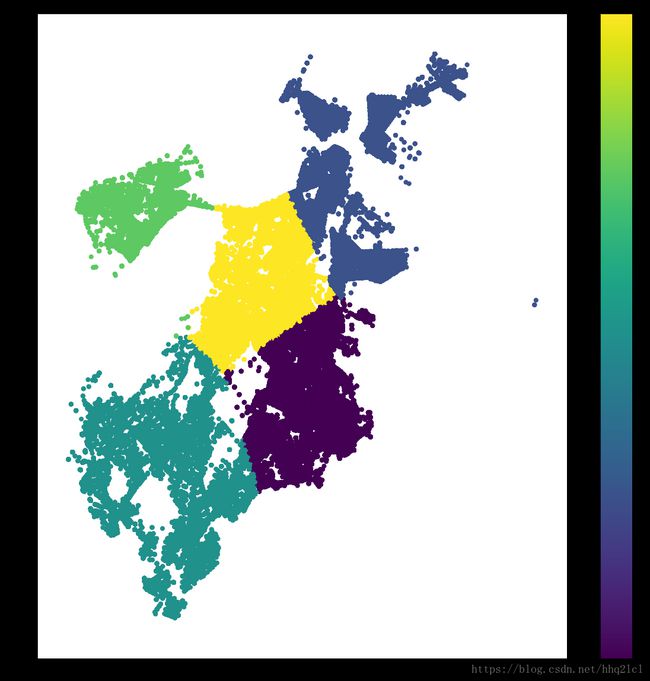
#分类图
fig=plt.figure(figsize=(20,20))
ax=fig.add_subplot(111)
scatter=ax.scatter(loca.Long,loca.Lat,c=kmeans[0],s=50)
ax.set_title('KMeans-CLUSTER')
ax.set_xlabel('Long')
ax.set_ylabel('Lat')
plt.colorbar(scatter)
四、Models
from sklearn import preprocessing
from sklearn.cross_validation import train_test_split
#特征处理
label=preprocessing.LabelEncoder()
df['DAY_OF_WEEK']=label.fit_transform(df.DAY_OF_WEEK)
df['DISTRICT']=label.fit_transform(df.DISTRICT)
df['OFFENSE_CODE_GROUP']=label.fit_transform(df['OFFENSE_CODE_GROUP'])
df['time_interval']=label.fit_transform(df['time_interval'])
#测试集和训练集
x=df[['DISTRICT','REPORTING_AREA','MONTH','DAY_OF_WEEK','HOUR','Lat','Long','time_interval']]
y=df['OFFENSE_CODE_GROUP']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.02,random_state=42)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import ExtraTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import f1_score
import time
#定义结果函数
def results(result):
print("mean:"+str(result.mean()))
print("min:"+str(result.min()))
print("max:"+str(result.max()))
return result
# DecisionTreeClassifier
DTC=DecisionTreeClassifier()
dtc_start=time.time()
DTC=DTC.fit(x_train,y_train)
dt_pre=DTC.predict(x_test)
dtc_score=f1_score(y_test,dt_pre,average=None)
costime=time.time()-dtc_star
print('cost time:%f s'%(costime))
print(results(dtc_score))
结果:
cost time:8.070462 s
mean:0.08694556228827025
min:0.0
max:0.43362831858407086
[0.08695652 0. 0. 0.2962963 0.06796117 0.05263158
0. 0. 0.17241379 0.06451613 0. 0.
0.06956522 0.43362832 0. 0. 0. 0.
0. 0. 0.03827751 0. 0.03636364 0.33333333
0. 0.12463768 0.16666667 0.06060606 0.23594267 0.10852713
0.19047619 0.16949153 0.27027027 0.11990408 0.07239819 0.01282051
0.25454545 0. 0. 0.09267564 0. 0.11764706
0. 0.13793103 0.07954545 0. 0.28571429 0.
0.08602151 0. 0.03278689 0.21052632 0. 0.05813953
0.24712644 0.06451613 0.0995671 0.12807882 0.05128205]
#KNeighborsClassifier
KNC=KNeighborsClassifier()
knc_start=time.time()
KNC=KNC.fit(x_train,y_train)
kn_pre=KNC.predict(x_test)
knc_score=f1_score(y_test,et_pre,average=None)
costime=time.time()-knc_start
print('cost time:%f s'%(costime))
print(results(knc_score))
结果:
cost time:3.835219 s
mean:0.08286325883924771
min:0.0
max:0.42058823529411765
[0.0867052 0. 0. 0.36363636 0.06030151 0.04347826
0. 0. 0.12244898 0.01388889 0. 0.
0.07476636 0.42058824 0. 0. 0. 0.
0. 0. 0.03703704 0. 0.0375 0.4
0. 0.12102874 0.15544041 0. 0.20824295 0.06842105
0.18181818 0.21052632 0.16216216 0.15312132 0.06837607 0.01257862
0.19982317 0. 0. 0.07142857 0. 0.
0.16470588 0. 0.1221374 0.06010929 0. 0.36363636
0. 0.05882353 0.03571429 0.03680982 0.23529412 0.
0.05555556 0.17313433 0.0552677 0.14767932 0.12682927 0.06278027]