MySQL实战-4
目录
误删除的恢复方案
kill不掉的语句
大批量数据查询
join原理
join优化
临时表
临时表的使用
误删除的恢复方案
误删行
通过flashback恢复,但binlog需要设置成row模式
对于单个事务做如下处理
- 对于insert,对应的binlog event类型是Write_row_event,改成Delete类型
- 对于delete语句,改成Write类型
- 对于update_rows语句,binlog里面记录了修改前和修改后的值,对调这两行的位置
对于多个事务
(A)delete ...
(B)insert ...
(C)update ...
恢复的时候按相反顺序恢复
(reverse C)update ...
(reverse B)delete ...
(reverse A)insert ...
以上操作要在从库上执行
误删表/库
需要用全量备份+实时备份binlog来恢复
流程如下
- 取最近一次全量备份,假设一天一次上次备份就是当天0点
- 用备份恢复出一个临时库
- 从日志备份里面,取出凌晨0点之后的日志
- 把这些日志,除了误删除的语句外,全部应用到临时库
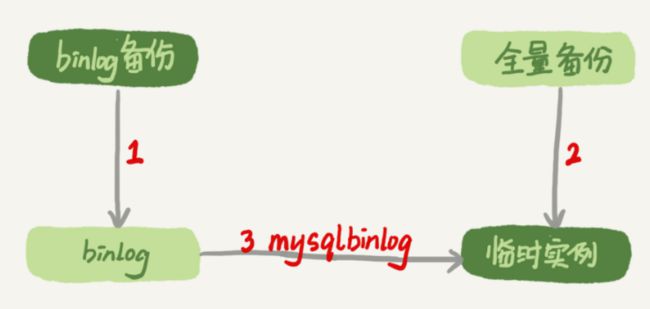
如果是一周备份一次,那恢复的时间会非常长
可以搞一个专门用于备份的从库
设置 change master to master_delay=N,这个N的单位是秒,设置成3600就表示跟主库有3600秒的延迟
如果主库有数据误删了,只需要再多追1小时数据就可以
rm 删除数据
除非是恶意删除整个集群,单独删除一个机器的数据并不怕,对于高可用的MySQL来说,随便从其他节点就可以把数据恢复出来了
预防措施
- 账号分离
- 定制操作规范,删除操作必须通过管理系统执行
- 加上sql_safe_updates,delete和update语句中没有where会报错
- 经常演练误删除恢复操作,把这个做成自动化
kill不掉的语句
mysql中有两个kill命令
kill query + 线程id,表示终止这个线程正在执行的语句
kill connection + 线程id,表示断开这个线程的连接,connection可以省略
通过下面命令可以查看正在运行的线程
show processlist
kill query 类似linux的信号,并不是直接kill,而且告诉进程将要终止了,后面还有一些收尾操作
kill操作会做下面事情
- 把运行的状态改成THD::KILL_QUERY
- 给执行的线程发送一个信号
这里有三层含义
- 一个语句执行过程中会有多个埋点,埋点的地方判断线程状态,如果发现线程状态是THD::KILL_QUERY,才开始终止逻辑
- 如果处于等待状态,必须是一个可以被唤醒的等待,否则根不会执行到“埋点”处
- 语句从开始进入终止逻辑,到终止逻辑完全完成,是有一个过程的
所以,不是说停就能停的
所以kill无效的一个情况是
- 线程没有到判断线程状态的逻辑
- 终止逻辑耗时很长
如:超大事务被kill需要做很多回滚操作
大查询回滚,如果中间生成了较大的临时文件,加上文件系统压力大,删除临时文件可能要等待IO资源导致耗时长
DDL命令执行到最后被kill,需要删除中间的临时文件,也可能受IO资源影响
另一个误解
如果数据库的表很多,连接过程就会很慢
连接过程包含了验证逻辑,跟表的数量无关,慢是因为客户端连接完后,会将所有的表在本地构建一个hash表,做自动补全用
所以并不是连接慢,是客户端慢,加上-A,将这个自动补全去掉即可
大批量数据查询
比如内存只有100G,但是数据有200G,如果全读到内存,整个机器内存都不够,进程会被直接OOM
比如下面这个语句,执行全表扫描
mysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file
mysql并不是全读到内存再发送到客户端的,而是边读边发
如下图所属

执行流程是
1.读取一行写入到 net_buffer中,这个大小由net_buffer_length定义,默认是16K
2.重复上述步骤,直到net_buffer写满,调用网络接口发出去
3.如果发送成功就清空net_buffer,继续读取下一行
4.如果失败就表示本地网络栈满了,进入等待状态
可以看到,一个查询在发送过程中,占用mysql内部最大值就是net_buffer_length,不会达到200G
socket send buffer也不会达到200G(默认定义 /proc/sys/net/core/wmen_default),如果网络的buffer被写满,就会暂停读取数据
通过
show processlist 查看
仅当一个线程处于【等待客户端接收结果】的状态,才显示【Sending to client】
如果显示成【Sending data】,他的意思是正在执行,比如可能卡在等待锁上了
InnoDB有 Buffer Pool,数据的读写都是在内存,一般好的系统,内存命中率在99%
如果数据放不下了,使用LRU算法淘汰旧的数据,但这种淘汰算法不是普通的LRU,是经过修改后的
修改后的LRU图,使用过程如下
InnoDB 按照5:3的比例把整个LRU链分成young区和old区
上图中
1.访问数据页P3,由于P3在young区,所以跟普通的LRU一样,将P3移动到链表头部
2.之后访问一个不存在的数据页,会淘汰掉最后的数据页Pm,但新插入的数据页Px,是放在LRU old区
3.处于old区的数据页,每次被访问都要做如下判断
若这个数据页在LRU链表中存在的时间超过了1秒,就把它移动到头部
如果这个这个数据页在LRU链表中的时间短于1秒,则保持不变,这个参数由
innodb_old_blocks_time控制
这个策略,就是为了类似全表扫描而量身定时的,改进后的LRU操作逻辑
- 扫描过程中,新插入的数据页放到old区
- 由于顺序扫描这个数据页第一次和最后一次被访问的时间间隔不会超过1秒,因此还保留在old区
- 继续扫描之后的数据,之前这个数据页再也不会被访问到,也没有机会移动到链表头部young区,很快就被淘汰出去
这个策略也用到了Buffer Pool,但对young区完全没影响,从而保证了Buffer Pool响应正常业务的查询命中率
join原理
Index Nested-Loop Join
使用普通的join,mysql会自动优化选一个表做驱动表,一个表做被驱动表,这里手动指定
select * from t1 straight_join t2 on (t1.a=t2.a);
join的执行过程如下图
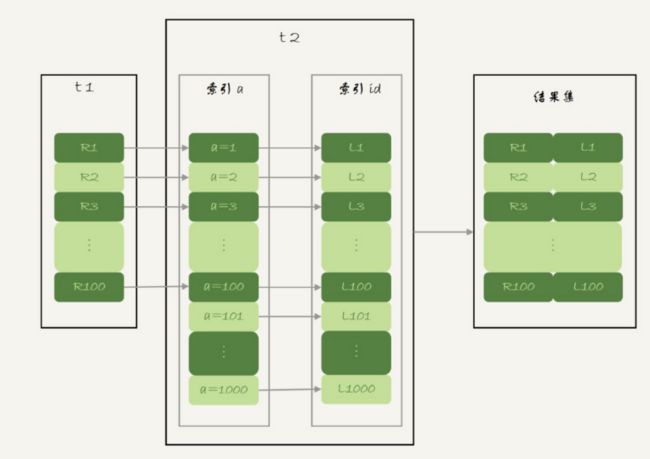
- 从表t1中读取一行数据R
- 从数据行R中,取出a字段到表t2中去查
- 取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分
- 重复执行步骤1-3,直到表t1的末尾循环结束
t1是驱动表,t2是被驱动表,整个过程中t2会使用到索引
对于t1是全表扫描,但t2走的是索引就会很快
所以t1应该是小表更合适,这样t2走索引效率就很高了
Block Nested-Loop Join
对于被驱动表,没有索引只能走全表扫描了
流程如下图

上图中的流程如下
1.把表t1的数据读入线程内存join_buffer中,由于我们这个语句中写的是select *,因此把整个t1表放入内存
2.扫描t2,把表t2中的每一行取出来,跟join_buffer 中的数据做对比,满足join条件的,作为结果集的一部分返回
默认情况下是放内存执行的,如果t1表是10W,t2表是10W
结果就是10W*10W,100亿次,因为是在内存执行的所以速度很酷开
如果内存中放不下t1的全表内容,则需要将t1表分段执行
执行如下图
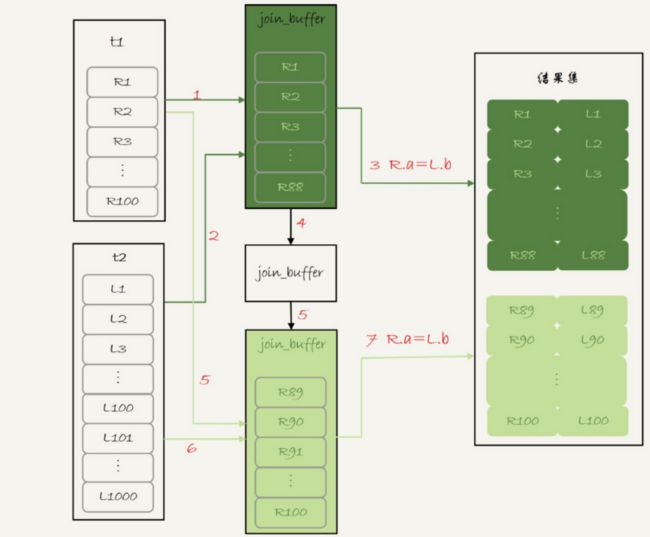
执行过程如下
- 扫描t1,顺序读取数据行放入join_buffer中,等join_buffer满了,继续第二步
- 扫描t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的作为结果的一部分返回
- 清空join_buffer
- 继续扫描t1,顺序读取到剩下的行放入到join_buffer中,继续执行第二步
对于join语句的使用
- 如果可以使用索引,那就是Index Nested-Loop Join算法,这是没问题的
- 如果没有索引,走的是Block Nested-Loop Join算法,这样被驱动的表会被扫描多次,占用大量系统资源,这种join不要使用
所以判断是否要用join,就看explain里面,Extra字段里面是否有【Block Nested-Loop Join】
对于大表小表的选择是,驱动表总应该是使用 小表做驱动
所谓的大表,小表不是说这个表数据量多大
应该是两个表按各种的过滤条件,过滤完之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是【小表】,应该作为驱动表
join优化
Multi-Range Read优化
这个优化的目的是尽量使用顺序读盘
比如这个语句会出现回表
select * from t1 where a>=1 and a<=100;
回表流程如下

如果随着a的值递增顺序查询的话,id的值就会变成随机的,那么就会出现随机访问
如果按照主键顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能
MMR优化后执行过程如下

执行过程如下
1.根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中
2.将read_rnd_buffer中的id进行递增排序
3.排序后的id数组,依次到主键id索引中查记录,并作为结果返回
如果explain中有MMR,说明使用了MRR优化

MRR的核心在于,这条查询语句在索引a上做的是一个范围查询,也就是一个多值查询,可以得到最够多的主键id,这样通过排序后,再去主键索引树上查数据,才能体现出顺序性的优势
Batched Key Access
这个优化方式是,一次性的多从t1里面拿一些数据出来,一起传给t2
先从t1里面取一些数据出来,放到一个临时表,这个临时内容就是join_buffer
执行如下图

在join_buffer中放入的数据是p1--p100,表示只会取查询需要的字段,如果join_buffer放不下所有数据,就会把这1--行数据分成多段执行上图流程
要使用BKA算法,需要执行下面sql
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
BAK算法优化需要依赖MRR
Block Nested-Loop Join算法,即被驱动的表没有索引,join的时候要全表扫描
InnoDB的 LRU算法是经过改进的,专门为了扫全表做了处理,分为young区和old区,但如果频繁的join,会多次扫描到被驱动表,某个数据页会在1秒后继续被访问到,于是移动到young区
导致这段时间内的young区的数据页没有被合理的淘汰
大表join虽然对IO有影响,但在语句执行后,对IO的影响也就结束了,但对于Buffer Pool的影响是持续的,需要靠后续的查询慢慢恢复内存命中率
对此的解法办法是,增加join_buffer_size的值
Block Nested-Loop Join对系统的影响包括三个方面
1.可能会扫次扫描被驱动的表,占磁盘IO
2.判断join条件需要执行M*N次对比,如果是大表会占用非常多的CPU资源
3.可能会导致Buffer Pool的热数据被淘汰,影响内存命中率
另一个优化方案是增加一个临时表,步骤如下
1.把被驱动表满足的数据放在临时表tmp_t中
2.位了让join使用Batched Key Access算法,给临时表增加索引
3.让表t1和tmp_t做join操作
改写的sql如下
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
hash join
没有索引的被驱动表t2是做全表扫描的
首先把t1表的内容取出来放到join_buffer中,如果join_buffer执行hash join那每次就不用全表扫描了
可以在客户端做优化
1.select * from t1,然后将数据放到业务端的一个hash结构中,
2.select * from t2 where b>=1 and b<=2000 获取表t2中满足条件的2000行数据
3.把这2000行数据一行一行的取到业务端,跟hash结构表中寻找匹配的数据,满足匹配条件的这行数据,就作为结果集的一行
临时表
内存表,是用memory引擎的表,建表语句是 create table 。。。 engin=memory,这种表的数据都保存在内存里,系统重启时被清空,但表结构还在
临时表,可以使用各种引擎类表,包括MyISAM引起,和InnoDB,以及memory
临时表的特点
- 建表语句是 create ttemporay table...
- 一个临时表只能被创建它的sesion访问,对其他线程不可见
- 临时表可以与普通表同名
- session A内有同名的临时表和普通表,show create语句,可以增删改查语句访问的是临时表
- show tables命令不现实临时表
临时表特别适合join优化这种场景
等这个session结束了,就会自动清空临时表
临时表的应用
一般分库分表,把一个逻辑上的大表分散到不同的数据库实例上,如一个大表ht,按照字段f拆分成1024个分表,然后分布到32个数据库实例上,如下图所示
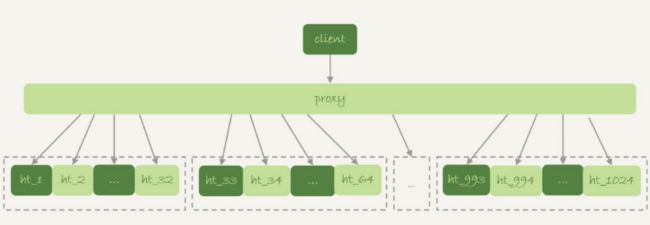
下面这个sql就需要查询所有的分区再做合并
select v from ht where k >= M order by t_modified desc limit 100;第一种方案是在proxy上做合并,但工作量但而且实现复杂
第二种是在汇总库上创建一个临时表,执行流入如下
在各个分库上执行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;
把分库执行的结果放入到tmp_ht表中
select v from temp_ht order by t_modified desc limit 100;
整个流程如下
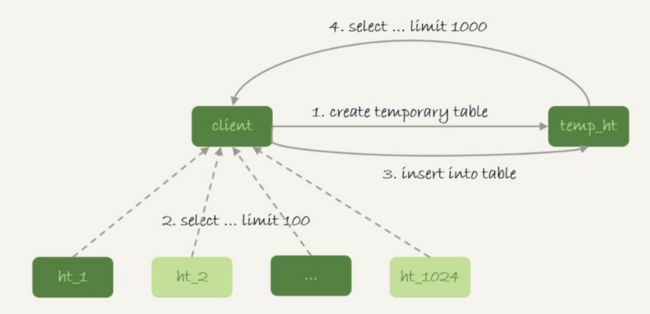
一般情况下,每个分库计算量都不饱和,所以会直接把临时表tmp_ht放到32个分库的某个上执行
为了维护表名的不同,每个表都对应一个table_def_key
- 普通表的table_def_key的值是 库名+表名
- 临时表的table_def_key是 库名+表名+server_id+thread_id
临时表的主备复制
下面这个语句如果临时表不记录到binlog,那么应用到从库的表就没数据了
create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/
create temporary table temp_t like t_normal;/*Q2*/
insert into temp_t values(1,1);/*Q3*/
insert into t_normal select * from temp_t;/*Q4*/
如果是row模式就没关系,但statement和mix就不行了
所以binlog会记录临时表操作,但用完了也得把临时表删了,所以要在主库上增加一个
DROP TEMPORYARY TABLE传给备库执行
临时表的使用
使用union
(select 1000 as f) union (select id from t1 order by id desc limit 2);
explain如下图

执行过程如下
1.创建一个内存临时表,临时表有个字段f,并且f是主键字段
2.执行第一个子查询得到1000这个值,并存入临时表
3.执行第二个字查询
拿到第一行id=1000,试图插入临时表,但数据已经有了插入失败,继续
取第二行id=999,插入成功
4.从临时表按行取出数据,返回结果,并删除临时表,结果中包含两行数据1000和999
执行结果图如下

group by执行
一个sql如下
select id%10 as m, count(*) as c from t1 group by m;
语句是把表t1的数据,按照id%10分组,并按照m的结果排序后输出
explain如下
explain的Extra字段里,看到三个信息
1.Using index,表示使用了覆盖索引,选择了索引a,不需要回表
2.Using temporary,使用了临时表
3.Using filesort,需要排序
执行流程
1.创建内存临时表,两个字段m和c,m是主键
2.扫描表t1的索引a,依次取出叶子节点上的id只,计算id%10的结果,记为x
如果临时表中没有主键为x的行,就插入一个记录(x,1)
如果表中有主键x的行,就将x这一行的c值加1
3.遍历完成后,再根据字段m做排序,得到结果集返回给客户端
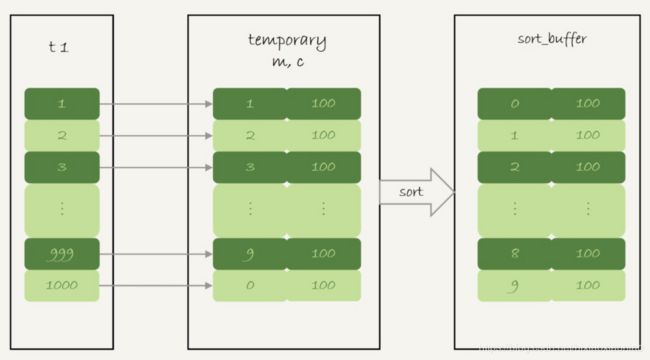
如果不需要对结果进行排序,那SQL语句末尾增加order by null,如下
select id%10 as m, count(*) as c from t1 group by m order by null;
如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累计就可以了
按照这个逻辑执行的话,扫描整个输入密码的数据结束,就可以拿到group by的结果,不需要临时表,也不需要额外排序
mysql5.7引入generated column机制,来实现数列数据的关联更新,可以增加一个列z来实现
alter table t1 add column z int generated always as(id % 100), add index(z);
上述的sql也可以改成
select z, count(*) as c from t1 group by z;
优化后的group by的explain如下
正常的group by需要将数据 先放入内存,如果发现内存临时表不够用了,就转成磁盘临时表
加入一个提示,可以让mysql直接走磁盘临时表
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
总结
- 如果对group by语句的结果没有排序要求,可以在最后加上 oorder by null
- 尽量让group by过程用上表的索引,通过explain结果里没有Using temporay和Using filesort
- 如果group by需要统计的数据量不大,尽量只使用临时表,也可以调大tmp_table_size
- 如果数据量实在太大,使用SQL_BIG_RESULT 提示优化前直接使用磁盘临时表排序
