Centos7中用Ambari快速搭建大数据平台攻略(三)
前边两边文章已经介绍了,环境准备与ambari的成功安装,下面我们开始使用Ambari界面安装Hadoop、spark、Hbase、Log Search等等服务。
前两篇传送门:环境准备快速搭建大数据平台(一) ambari安装快速搭建大数据(二)
本片详细介绍使用Ambari界面安装Hadoop、spark、Hbase、Log Search等服务及高可用设置教程
目 录
一、使用Ambari界面安装Hadoop、Hbase、Log Search服务
二、Hadooop开启高可用(现在安装好Hadoop是不支高可用的,下面准备开启Hadoop高可用)
一、使用Ambari界面安装Hadoop、Hbase、Log Search服务
1、出现登录界面,默认管理员账户登录, 账户:admin 密码:admin
2、登录成功后出现下面的界面,至此Ambari的安装成功

3、安装安装HDP 2.5.3 配置集群(点击上面登录成功页面的Launch Install Wizard 按钮进行集群配置)
设置集群名称

4、置HDP安装源(选择HDP2.5 ,并且设置Advanced Repository Options 的信息,本次使用本地源,所以修改对用系统的安装源为本地源地址)

5、设置集群机器(下载ambari01.hadoop机器上的id_rsa私钥到本地)

6、Host确认(确认前面配置集群中hosts列表 中的机器是否都可用,也可以移除相关机器,集群中机器Success后进行下一步操作)

7、选择要安装的服务

8、各个服务Master配置

9、服务的Slaves 和 Clients节配置

10、服务的客制化配置

11、显示配置信息
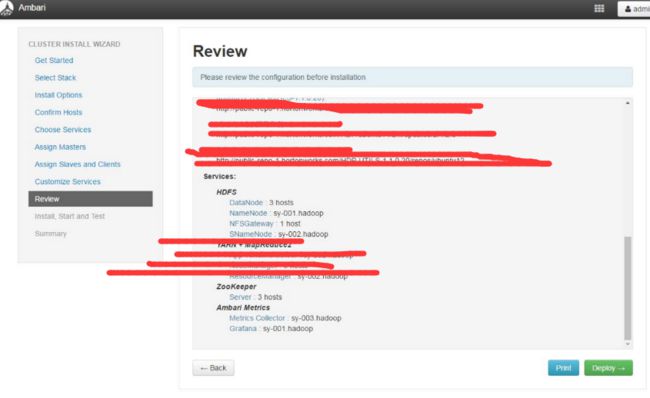
12、开始安装(安装各个服务,并且完成安装后会启动相关服务,安装过程比较长,如果中途出现错误,请根据具体提示或者log进行操作)

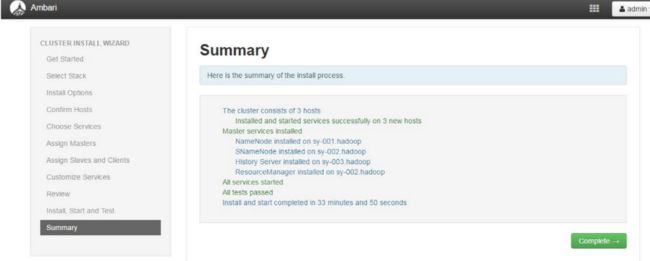
13、全部安装成功界面如下

14、安装完成

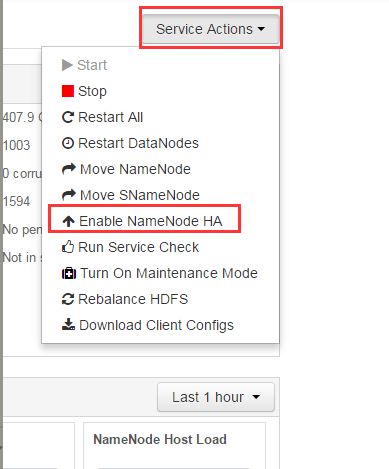
二、Hadooop开启高可用(现在安装好Hadoop是不支高可用的,下面准备开启Hadoop高可用)
1、开启高可用开关
2、设置高可用名称(如果hbase是启动的话请关闭在开启HA高可用)

3、选择服务安装在那台主机上


4、按照提示操作,最后显示如下表示HA安装成功

5、Hbase高可用会显示如下图

三、验证集群
(1)、Ambari上给Root用户增加HDFS写权限
Ambari WebUI
Dashboard/HDFS/Configs/Advanced/Advanced
hdfs-site/设置dfs.permissions.enabled=false,
然后重启受到影响的服务。
(2)、验证集群
A、HDFS Namenode:http://192.168.9.61:50070/dfshealth.html#tab-overview
B、YARN:http://192.168.9.61:8088/cluster
C、测试MapReduce
[[email protected] ~]# hdfs dfs -mkdir /data/
[[email protected] ~]# cat mr_test_data.txt
hadoop
hadoop
spark
hbase
hbase
hbase
[[email protected] ~]# hdfs dfs -put mr_test_data.txt /data/
[[email protected] hadoop-mapreduce]# hadoop jar /usr/hdp/2.6.4.0-91/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.6.4.0-91.jar wordcount /data/mr_test_data.txt /result/
D、测试Spark yarn-client
[[email protected] ~]# cd /usr/hdp/2.6.4.0-91/spark2/ && bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 540M --num-executors 1 examples/jars/spark-examples_2.11-2.2.0.2.6.4.0-91.jar 100
E、测试Spark yarn-cluster
[[email protected] ~]# cd /usr/hdp/2.6.4.0-91/spark2/ && bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster
--executor-memory 750M --num-executors 1 examples/jars/spark-examples_2.11-2.2.0.2.6.4.0-91.jar 10