梯度下降法快速教程 | 第三章:学习率衰减因子(decay)的原理与Python实现
12月23-24日

正文共3017个字、11张图、预计阅读时间:8分钟
梯度下降法(Gradient Descent)是机器学习中最常用的优化方法之一,常用来求解目标函数的极值。
其基本原理非常简单:沿着目标函数梯度下降的方向搜索极小值(也可以沿着梯度上升的方向搜索极大值)。
但是如何调整搜索的步长(也叫学习率,Learning Rate)、如何加快收敛速度以及如何防止搜索时发生震荡却是一门值得深究的学问。
上两篇文章《梯度下降法快速教程 | 第一章:Python简易实现以及对学习率的探讨》与《梯度下降法快速教程 | 第二章:冲量(momentum)的原理与Python实现》分别介绍了学习率大小对搜索过程的影响以及“冲量”的原理以及如何用“冲量”来解决收敛速度慢与收敛时发生震荡的问题。接下来本篇文章将介绍梯度下降法中的第三个超参数:decay。
PS:本系列文章全部源代码可在本人的GitHub:monitor1379中下载。
首先先回顾一下不同学习率下梯度下降法的收敛过程(示例代码在GitHub上可下载):
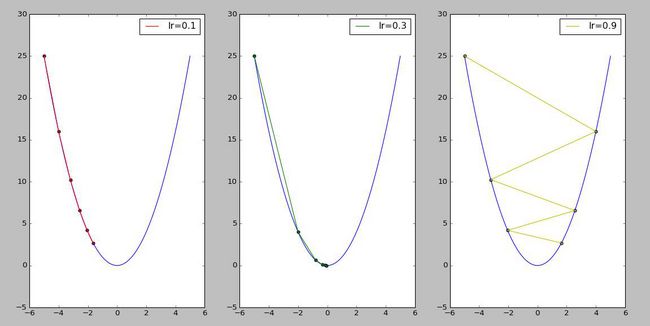
demo1_GD_lr运行结果
从上图可看出,学习率较大时,容易在搜索过程中发生震荡,而发生震荡的根本原因无非就是搜索的步长迈的太大了。
回顾一下问题本身,在使用梯度下降法求解目标函数func(x) = x * x的极小值时,更新公式为x += v,其中每次x的更新量v为v = - dx * lr,dx为目标函数func(x)对x的一阶导数。可以想到,如果能够让lr随着迭代周期不断衰减变小,那么搜索时迈的步长就能不断减少以减缓震荡。学习率衰减因子由此诞生:
lr_i = lr_start * 1.0 / (1.0 + decay * i)
上面的公式即为学习率衰减公式,其中lr_i为第i次迭代时的学习率,lr_start为原始学习率,decay为一个介于[0.0, 1.0]的小数。
从公式上可看出:
-
decay越小,学习率衰减地越慢,当decay = 0时,学习率保持不变。
-
decay越大,学习率衰减地越快,当decay = 1时,学习率衰减最快。
使用decay的梯度下降法Python实现代码如下:
import numpy as npimport matplotlib.pyplot as plt# 目标函数:y=x^2def func(x): return np.square(x)# 目标函数一阶导数:dy/dx=2*xdef dfunc(x): return 2 * xdef GD_decay(x_start, df, epochs, lr, decay): """ 带有学习率衰减因子的梯度下降法。 :param x_start: x的起始点 :param df: 目标函数的一阶导函数 :param epochs: 迭代周期 :param lr: 学习率 :param decay: 学习率衰减因子 :return: x在每次迭代后的位置(包括起始点),长度为epochs+1 """ xs = np.zeros(epochs+1) x = x_start xs[0] = x v = 0 for i in range(epochs): dx = df(x) # 学习率衰减 lr_i = lr * 1.0 / (1.0 + decay * i) # v表示x要改变的幅度 v = - dx * lr_i x += v xs[i+1] = x return xs
使用以下测试与绘图代码demo3_GD_decay来看一下当学习率依次为lr = [0.1, 0.3, 0.9, 0.99]与decay = [0.0, 0.01, 0.5, 0.9]时的效果如何:
def demo3_GD_decay():
line_x = np.linspace(-5, 5, 100)
line_y = func(line_x)
plt.figure('Gradient Desent: Decay')
x_start = -5
epochs = 10
lr = [0.1, 0.3, 0.9, 0.99]
decay = [0.0, 0.01, 0.5, 0.9]
color = ['k', 'r', 'g', 'y']
row = len(lr)
col = len(decay)
size = np.ones(epochs + 1) * 10
size[-1] = 70
for i in range(row):
for j in range(col):
x = GD_decay(x_start, dfunc, epochs, lr=lr[i], decay=decay[j])
plt.subplot(row, col, i * col + j + 1)
plt.plot(line_x, line_y, c='b')
plt.plot(x, func(x), c=color[i], label='lr={}, de={}'.format(lr[i], decay[j]))
plt.scatter(x, func(x), c=color[i], s=size)
plt.legend(loc=0)
plt.show()
运行结果如下图所示,其中每行图片的学习率一样、decay依次增加,每列图片decay一样,学习率依次增加:
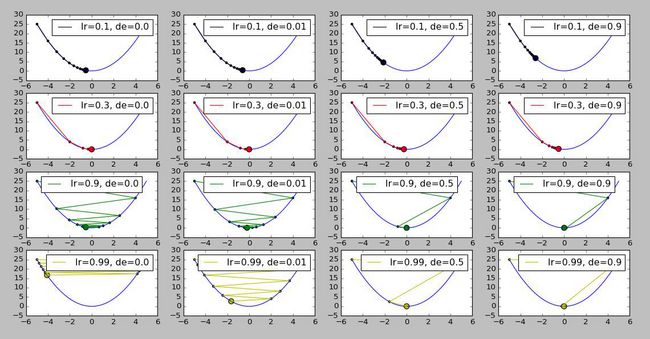
demo3_GD_decay运行结果
简单分析一下结果:
-
在所有行中均可以看出,decay越大,学习率衰减地越快。
-
在第三行与第四行可看到,decay确实能够对震荡起到减缓的作用。
那么,不同decay下学习率的衰减速度到底有多大的区别呢?接下来设置起始学习率为1.0,decay依次为[0.0, 0.001, 0.1, 0.5, 0.9, 0.99],迭代周期为300时学习率衰减的情况,测试与绘图代码如下:
def demo4_how_to_chose_decay(): lr = 1.0 iterations = np.arange(300) decay = [0.0, 0.001, 0.1, 0.5, 0.9, 0.99] for i in range(len(decay)): decay_lr = lr * (1.0 / (1.0 + decay[i] * iterations)) plt.plot(iterations, decay_lr, label='decay={}'.format(decay[i])) plt.ylim([0, 1.1]) plt.legend(loc='best') plt.show()
运行结果如下图所示。可以看到,当decay为0.1时,50次迭代后学习率已从1.0急剧降低到了0.2。如果decay设置得太大,则可能会收敛到一个不是极值的地方呢。看来调参真是任重而道远:

demo4_how_to_chose_decay运行结果
关于“梯度下降法”的三个超参数的原理、实现以及优缺点已经介绍完毕。对机器学习、深度学习与计算机视觉感兴趣的童鞋可以关注本博主的简书博客以及GitHub:monitor1379哦~后续将继续上更多的硬干货,谢谢大家的支持。
原文链接:http://www.jianshu.com/p/d8222a84613c
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
![]()

点击“阅读原文”直接打开报名链接