机器学习教程 之 参数搜索:GridSearchCV 与 RandomizedSearchCV || 以阿里IJCAI广告推荐数据集与XGBoostClassifier分类器为例
在使用一些比较基础的分类器时,需要人为调整的参数是比较少的,比如说K-Neighbor的K和SVM的C,通常而言直接使用sklearn里的默认值就能取得比较好的效果了。
但是,当使用一些大规模集成的算法时,参数的问题就出来了,比如说 XGBoost的参数大概在20个左右,GBDT的参数个数也在同一个级别,这种时候,会调参和不会调参在同样的数据集上效果可能就是两码事了。这里借着做阿里天池大赛的机会和大家分享一些使用sklearn里封装好的函数 GridSearchCV 与 RandomizedSearchCV 进行调参的方法和技巧,分类器就以常用的XGBoostClassifier为例
这里主要介绍一下这两个函数的应用
网格搜索:GridSearchCV
随机搜索:RandomizedSearchCV
GridSearchCV
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。
这两个概念都比较好理解,网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个循环和比较的过程。
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,它要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。这也是我通常不会使用GridSearchCV的原因,一般会采用后一种RandomizedSearchCV随机参数搜索的方法。
交叉验证的概念也很简单
· 将训练数据集划分为K份,K一般为10(我个人取3到5比较多)
· 依次取其中一份为验证集,其余为训练集训练分类器,测试分类器在验证集上的精度
· 取K次实验的平均精度为该分类器的平均精度
网格搜索就是利用交叉验证的形式比较每一个参数下训练器的精度的,但是交叉验证也要求大量的计算资源,加重了网格搜索的搜索时间
接下来以阿里IJCAI广告推荐数据集与XGBoostClassifier分类器为例,用代码的形式说明sklearn中GridSearchCV的使用方法
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.grid_search import GridSearchCV
#导入训练数据
traindata = pd.read_csv("/home/pmqc01/LiangjunFeng/traindata_4_3_2.txt",sep = ',')
traindata = traindata.set_index('instance_id')
trainlabel = traindata['is_trade']
del traindata['is_trade']
print(traindata.shape,trainlabel.shape)
#分类器使用 xgboost
clf1 = xgb.XGBClassifier()
#设定网格搜索的xgboost参数搜索范围,值搜索XGBoost的主要6个参数
param_dist = {
'n_estimators':range(80,200,4),
'max_depth':range(2,15,1),
'learning_rate':np.linspace(0.01,2,20),
'subsample':np.linspace(0.7,0.9,20),
'colsample_bytree':np.linspace(0.5,0.98,10),
'min_child_weight':range(1,9,1)
}
#GridSearchCV参数说明,clf1设置训练的学习器
#param_dist字典类型,放入参数搜索范围
#scoring = 'neg_log_loss',精度评价方式设定为“neg_log_loss“
#n_iter=300,训练300次,数值越大,获得的参数精度越大,但是搜索时间越长
#n_jobs = -1,使用所有的CPU进行训练,默认为1,使用1个CPU
grid = GridSearchCV(clf1,param_dist,cv = 3,scoring = 'neg_log_loss',n_iter=300,n_jobs = -1)
#在训练集上训练
grid.fit(traindata.values,np.ravel(trainlabel.values))
#返回最优的训练器
best_estimator = grid.best_estimator_
print(best_estimator)
#输出最优训练器的精度
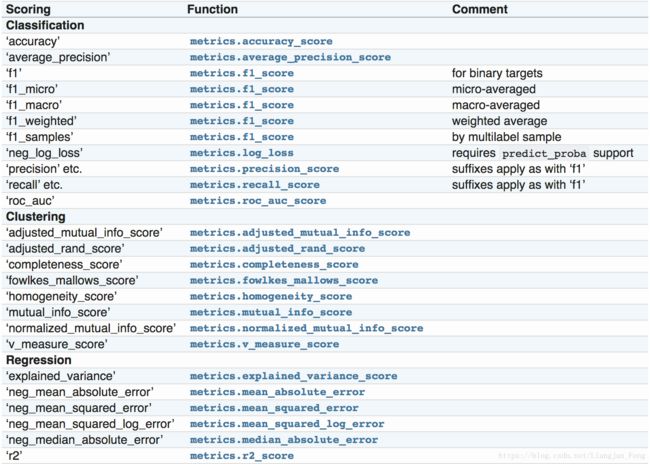
print(grid.best_score_)这里关于网格搜索的几个参数再说明一下,评分参数“scoring“,需要根据实际的评价标准设定,阿里的IJCAI的标准是’neg_log_loss’,所以这里设定的是’neg_log_loss’,sklearn中备选的评价标准有一下:
在一些情况下,sklearn中没有现成的评价函数,sklearn是允许我们自己的定义的,但需要注意格式,接下来给个例子
import numpy as np
from sklearn.metrics import make_scorer
def my_custom_loss_func(ground_truth, predictions):
diff = np.abs(ground_truth - predictions).max()
return np.log(1 + diff)
#这里的greater_is_better参数决定了自定义的评价指标是越大越好还是越小越好
loss = make_scorer(my_custom_loss_func, greater_is_better=False)
score = make_scorer(my_custom_loss_func, greater_is_better=True)定义好以后,再将其代入GridSearchCV函数就好
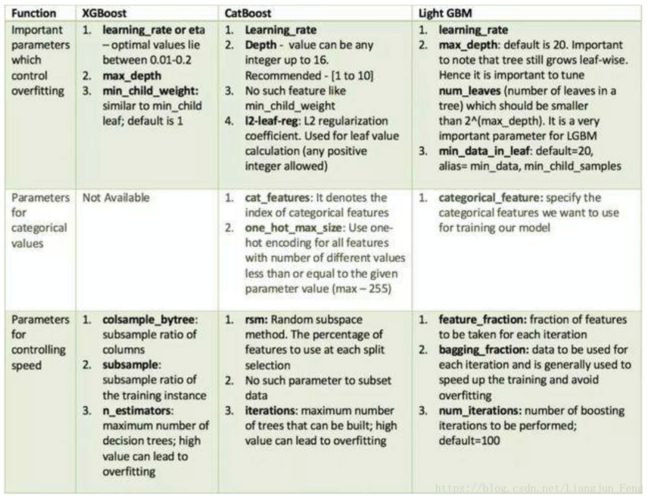
这里再贴一下常用的集成学习算法比较重要的需要调参的参数,供大家参考
RandomizedSearchCV
RandomizedSearchCV的使用方法其实是和GridSearchCV一致的,但它以随机在参数空间中采样的方式代替了GridSearchCV对于参数的网格搜索,在对于有连续变量的参数时,RandomizedSearchCV会将其当作一个分布进行采样这是网格搜索做不到的,它的搜索能力取决于设定的n_iter参数,同样的给出代码
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.grid_search import RandomizedSearchCV
#导入训练数据
traindata = pd.read_csv("/home/pmqc01/LiangjunFeng/traindata_4_3_2.txt",sep = ',')
traindata = traindata.set_index('instance_id')
trainlabel = traindata['is_trade']
del traindata['is_trade']
print(traindata.shape,trainlabel.shape)
#分类器使用 xgboost
clf1 = xgb.XGBClassifier()
#设定搜索的xgboost参数搜索范围,值搜索XGBoost的主要6个参数
param_dist = {
'n_estimators':range(80,200,4),
'max_depth':range(2,15,1),
'learning_rate':np.linspace(0.01,2,20),
'subsample':np.linspace(0.7,0.9,20),
'colsample_bytree':np.linspace(0.5,0.98,10),
'min_child_weight':range(1,9,1)
}
#RandomizedSearchCV参数说明,clf1设置训练的学习器
#param_dist字典类型,放入参数搜索范围
#scoring = 'neg_log_loss',精度评价方式设定为“neg_log_loss“
#n_iter=300,训练300次,数值越大,获得的参数精度越大,但是搜索时间越长
#n_jobs = -1,使用所有的CPU进行训练,默认为1,使用1个CPU
grid = RandomizedSearchCV(clf1,param_dist,cv = 3,scoring = 'neg_log_loss',n_iter=300,n_jobs = -1)
#在训练集上训练
grid.fit(traindata.values,np.ravel(trainlabel.values))
#返回最优的训练器
best_estimator = grid.best_estimator_
print(best_estimator)
#输出最优训练器的精度
print(grid.best_score_)这里要注意,虽然GridSearchCV 与 RandomizedSearchCV同样都有参数n_iter,但其实质是不一样的,官方文档对于这里的解释是
In contrast to GridSearchCV, not all parameter values are tried out, but rather a fixed number of parameter settings is sampled from the specified distributions. The number of parameter settings that are tried is given by n_iter.
If all parameters are presented as a list, sampling without replacement is performed. If at least one parameter is given as a distribution, sampling with replacement is used. It is highly recommended to use continuous distributions for continuous parameters.
即RandomizedSearchCV的主要特点还是参数的选取是随机的,不保证每一个参数都能够遍历,还有对于连续参数是当作一个分布来处理的