原来2-SAT是这么一回事
What is 2-SAT you may ask
有很多集合,每个集合里有k个元素,要从中选择一个。除此以外,还有若干“选了A元素就必须选B”的限制,求一种可行的选择方案。
例题引入:poj3648
有一对新郎新娘准备婚礼,邀请了(n-1)对夫妇参加( n ≤ 30 n \leq 30 n≤30),其中有m个人有通奸关系(???),而且新郎新娘和别人,同性或异性都可能发生通奸关系(贵圈真乱…)。现在有一张长桌,有两边,一边坐着新娘一边坐着新郎,新娘不希望她对面有一对夫妇或者有通奸关系的人坐在一起,求一种排座位方案,输出坐新娘这边的人。
考虑先解决坐新郎这一边的人。假设存在通奸关系 ( A 1 , B 1 ) (A_1,B_1) (A1,B1), A 1 A_1 A1的伴侣是 A 2 A_2 A2, B 1 B_1 B1的伴侣是 B 2 B_2 B2,那么显然选了 A 1 A_1 A1就必须选 B 2 B_2 B2,选了 B 1 B_1 B1就必须选 A 2 A_2 A2。
How to deal with 2-SAT problem?
建图!边(x,y)表示选择x就必须选择y。
呃,对于这一题要解释一点,就是因为我们选择的是新郎这一边的人,所以我们要从新娘向新郎连一条边。这是由于2-SAT的建图特殊性质导致一个集合里的两个元素不会同时被选,也不会都不选(就无解啦),所以这样连边就保证了新郎要被选。
暴力法
暴力搜。每次选择了一个后,就暴力搜接下来必须选择的,然后把他们都选择,其伴侣都标记为不选择。如果不合法就换一种方式搜。
该方法实际应用的时候也不是很慢,而且如果求字典序最小方案就只能这么做了。
#include乱搞法
方法原理会在“说明”里讲。
- 使用tarjan缩点,那么一个强连通分量里的点选一则必须选全部
- 做一次检查,如果有一对夫妇在同一个强连通分量里,输出无解信息。
- 用缩后的点建立新图,并把边反过来。这个新图称为图2,下列操作都在图2中进行。
- 假如一对夫妇,丈夫在图2中的点A,妻子在点B,则标记B为A的对立节点,A为B的对立节点。
- 拓扑排序。每次找到一个点,如果它上面没有打标记,打上选择标记,并把其对立点打上不选标记
好,那么这么做是否讲究了基本法呢?
首先,为什么要把边都反过来?
因为你是要去选点,而你选了一个点后,把这个“选择”的状态向下传递是非常麻烦的。
但是反边之后,选择标记就没必要传递了,不选标记变成了要传递的东西,这个又怎么传递呢?
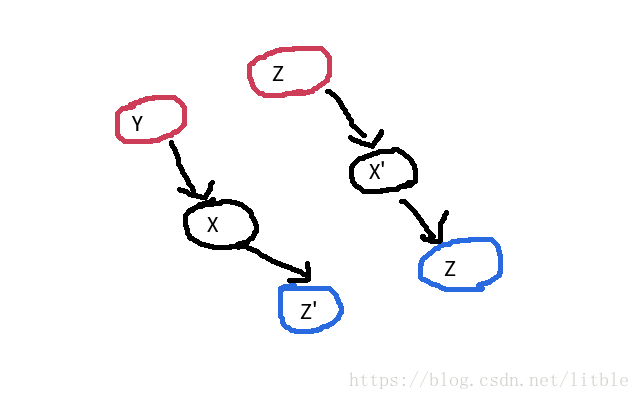
我们是按照拓扑序在处理问题,也就是说,在图2中,如果一个不选的节点 x x x会走到一个没有打标记的节点 y y y,既然 y y y没打标记那么 y ′ y' y′也不会打标记,既然 x x x是不选标记那么在此之前已经处理了 x ′ x' x′。又由对称性, y y y的对立节点 y ′ y' y′会走到 x x x的对立节点 x ′ x' x′,那么 y ′ y' y′的拓扑序在 x x x之前,也就是 y y y这一对会被先打标记,然后再轮到 x x x这一对打标记,这就出现了矛盾。综上,没必要故意去传递标记,没打标记的节点就直接选就是。

然后,这样做凭什么保证一对夫妻不会同时不选?
其实这有很多情况,我就以一种情况为例说一说,其他的也差不多我懒就不说了。
假设这对可怜地被同时不选的夫妻为 ( x , x ′ ) (x,x') (x,x′),假设 y y y和 z z z都打上了不选标记,那么 y ′ y' y′和 z ′ z' z′应该被打上了选择标记,并已经被处理过。假设有 y − > x y -> x y−>x, z − > x ′ z -> x' z−>x′,这两条边,这样 x x x这对夫妻都不能被选了。由对称性, x ′ − > y ′ x' -> y' x′−>y′, x ′ − > z ′ x' -> z' x′−>z′,这两条边也存在,如图,显然 x x x和 x ′ x' x′没处理过之前,拓扑序处理是不会搞到 y ′ y' y′和 z ′ z' z′的。综上,这种情况不存在。
(下图中蓝色的点 Z Z Z应该为 Y ′ Y' Y′,手滑打错了抱歉)
那么这种算法就是讲究基本法的,代码实现如下:
#include哦,原来2-SAT是这么一回事!
update
xzy跟我说其实没必要再做一遍toposort的……
因为tarjan完了后你缩出来的点的顺序就是缩点后图的拓扑序的反序……
以下是洛谷P4782的代码:
#include