线性模型——机器学习(周志华)
C++实现线性回归
线性模型
f ( x ) = ω 1 x 1 + ω 2 x 2 + ω 3 x 3 + . . . + ω d x d + b f(\bm{x}) = \omega_1x_1 + \omega_2x_2 + \omega_3x_3 + ... + \omega_dx_d + b f(x)=ω1x1+ω2x2+ω3x3+...+ωdxd+b
f ( x ) = ω T x + b f(\bm{x}) = \bm{\omega^Tx} + b f(x)=ωTx+b
其中 ω = ( ω 1 ; ω 2 ; ω 3 ; . . . . ; ω d ) , x = ( x 1 ; x 2 ; . . . ; x d ) T \bm{\omega} = (\omega_1;\omega_2;\omega_3;....;\omega_d), \bm{x} = (x_1;x_2;...;x_d)^T ω=(ω1;ω2;ω3;....;ωd),x=(x1;x2;...;xd)T
线性回归
线性回归试图学得
f ( x i ) = ω x i + b f(\bm{x_i}) = \bm{\omega x_i} + b f(xi)=ωxi+b
使得
f ( x i ) ≃ y i f(\bm{x_i}) \simeq y_i f(xi)≃yi
如何求得 ω \omega ω和 b b b,关键在于衡量 f ( x i ) ≃ y i f(\bm{x_i}) \simeq y_i f(xi)≃yi,他们之间相差越小,结果越好,于是有
( ω ∗ , b ∗ ) = arg ω , b m i n ∑ i = 1 m ( f ( x i ) − y i ) 2 = arg ω , b m i n ∑ i = 1 m ( y i − ω x i − b ) 2 (\omega^*,b^*) = \arg \limits_{\bm{\omega}, b} min \sum \limits_{i = 1} ^m (f(\bm{x_i}) - y_i) ^ 2 = \arg \limits_{\bm{\omega}, b} min \sum \limits_{i = 1} ^m (y_i - \bm{\omega x_i} - b) ^ 2 (ω∗,b∗)=ω,bargmini=1∑m(f(xi)−yi)2=ω,bargmini=1∑m(yi−ωxi−b)2
化为一般式:
ω ^ ∗ = arg ω m i n ( y − X ω ^ ) T ( y − X ω ^ ) \widehat{\bm{\omega}}^* = \arg \limits_{\bm{\omega}} min (\bm{y - X\widehat{\omega}})^T(\bm{y - X\widehat{\omega}}) ω ∗=ωargmin(y−Xω )T(y−Xω )
对上式的 ω \bm{\omega} ω和 b b b求导,当 X T X \bm{X^TX} XTX为满秩矩阵或者正定矩阵式,令其等于零得到
ω ^ ∗ = ( X T X ) − 1 X T y \widehat{\bm{\omega}}^* = (\bm{X^TX})^{-1}\bm{X^Ty} ω ∗=(XTX)−1XTy
最后求的线性回归模型为:
f ( x ^ i ) = x ^ i ( X T X ) − 1 X T y f(\widehat{\bm{x}}_i) =\widehat{\bm{x}}_i (\bm{X^TX})^{-1}\bm{X^Ty} f(x i)=x i(XTX)−1XTy
m为数据集个数,d为属性个数,其中 X \bm{X} X为 ( m ∗ d ) (m*d) (m∗d), y \bm{y} y为 ( m ∗ 1 ) (m*1) (m∗1)
现实中 X T X \bm{X^TX} XTX往往不是满秩矩阵,会出现列数对于行数, X T X \bm{X^TX} XTX显然不满秩,此时可解出多个 ω ^ \bm{\widehat{\omega}} ω , 他们都能使均方误差最小化,选择哪一个解作为输出,将有学习算法的归纳偏好决定,常见的做法是引入正则化项。
也可模型预测值逼近y的衍生物,比如示例所对应的输出标记是在指数尺度上的变化,那么可以将输出标记的对数作为线性模型逼近的目标:
l n y = ω T x + b ln y = \bm{\omega^Tx} + b lny=ωTx+b
这就是“对数线性回归”。
更一般的,考虑单调可微函数。令
y = g − 1 ( ω T x + b ) y = g^{-1}(\bm{\omega^Tx} + b) y=g−1(ωTx+b)
这样得到的模型成为“广义线性模型”。
对数几率回归(逻辑回归)
上面讨论了使用线性模型进行回归学习,但如果要做的时分类任务该如何?我们现在讨论二分类。
这时候就用到逻辑回归,与线性回归不一样的是,再线性回归( z = ω T x + b z = \bm{\omega^Tx} + b z=ωTx+b)的基础上,外面包装了一个“sigmod”函数 y = 1 1 + e − z y = \frac{1}{ 1 + e ^ {-z}} y=1+e−z1,函数图像如下。
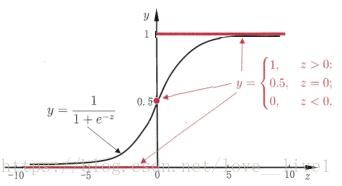
若预测值z大于零判为正例,小于零判为负例,预测值为临界值则可任意判别。
- 将z带入sigmod函数,得 y = 1 1 + e − ( ω T x + b ) y = \frac{1}{ 1 + e ^ {-(\bm{\omega^Tx} + b)}} y=1+e−(ωTx+b)1
- 然后化为 l n y 1 − y = ω T x + b ln \frac{y}{1-y} = \bm{\omega^Tx} + b ln1−yy=ωTx+b
- 若将 y y y视为 x x x作为正例的可能性,则 1 − y 1-y 1−y是其反例的可能性,两者的比值成为“几率”。
接下去的看逻辑回归
线性判别分析(LDA)
LDA的思想:给定训练集,设法将样例投影到一条直线上,是的同样类例的投影点尽可能接近、异类投影点尽可能远离;再对新样本进行分类时,将其同样投到这条直线上,再根据投影点的位置确定新样本的类别。
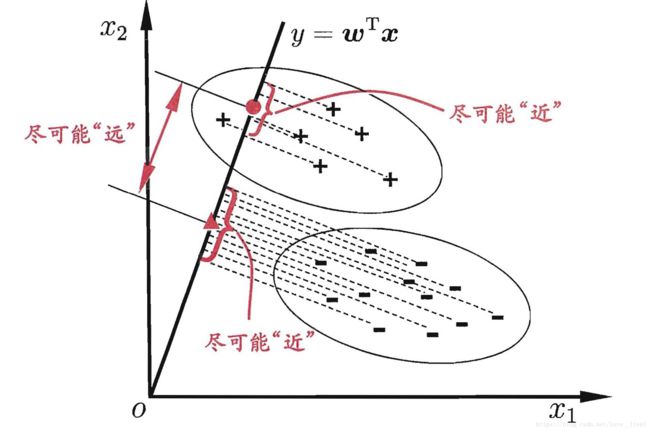
令 X i 、 μ i 、 ∑ i X_i、\mu_i、\sum_i Xi、μi、∑i分别代表第 i ∈ { 0 , 1 } i \in {\{0,1\}} i∈{0,1}类示例的集合、均值向量、协方差矩阵
- 两类样本的中心在直线上的投影分别为 ω T μ 0 \omega^T\mu_0 ωTμ0和 ω T μ 1 \omega^T \mu_1 ωTμ1;
- 若将所有样本点都投影到直线上,则两类样本的协方差分别为 ω T ∑ 0 ω \omega^T\sum_0\omega ωT∑0ω和 ω T ∑ 1 ω \omega^T\sum_1\omega ωT∑1ω;
- 我们的目的是 ω T ∑ 0 ω + ω T ∑ 1 ω \omega^T\sum_0\omega + \omega^T\sum_1\omega ωT∑0ω+ωT∑1ω尽可能小,使 ∣ ∣ ω T μ 0 − ω T μ 1 ∣ ∣ 2 2 ||\omega^T\mu_0-\omega^T \mu_1||_2^2 ∣∣ωTμ0−ωTμ1∣∣22尽可能大;
J = ∣ ∣ ω T μ 0 − ω T μ 1 ∣ ∣ 2 2 ω T ∑ 0 ω + ω T ∑ 1 ω = ω T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T ω ω T ( ∑ 0 + ∑ 1 ) ω \bm{J = \frac{||\omega^T\mu_0-\omega^T \mu_1||_2^2}{\omega^T\sum_0\omega + \omega^T\sum_1\omega} = \frac{\omega^T(\mu_0-\mu_1)(\mu_0-\mu_1)^T\omega}{\omega^T(\sum_0+\sum_1)\omega}} J=ωT∑0ω+ωT∑1ω∣∣ωTμ0−ωTμ1∣∣22=ωT(∑0+∑1)ωωT(μ0−μ1)(μ0−μ1)Tω
- 定义类内散度矩阵
S w = ∑ 0 + ∑ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 0 ( x − μ 1 ) ( x − μ 1 ) T \bm{S_w = \sum_0+\sum_1 = \sum_{x\in X_0} (x-\mu_0)(x-\mu_0)^T + \sum_{x\in X_0} (x-\mu_1)(x-\mu_1)^T} Sw=0∑+1∑=x∈X0∑(x−μ0)(x−μ0)T+x∈X0∑(x−μ1)(x−μ1)T - 定义类间散度矩阵
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T \bm{S_b = (\mu_0-\mu_1)(\mu_0-\mu_1)^T} Sb=(μ0−μ1)(μ0−μ1)T
J = ω T S b ω ω T S w ω \bm{J = \frac{\omega^TS_b\omega}{\omega^TS_w\omega}} J=ωTSwωωTSbω - 确定 ω \bm{\omega} ω
m i n ω − ω T S b ω s . t . ω T S w ω = 1 \bm{min_\omega \quad -\omega^TS_b\omega} \\ s.t. \quad\bm{\omega^TS_w\omega = 1} minω−ωTSbωs.t.ωTSwω=1 - 由拉格朗日乘子法,得
S b ω = λ S ω ω \bm{S_b\omega = \lambda S_{\omega}\omega} Sbω=λSωω - S b ω \bm{S_b\omega} Sbω的方向恒为 μ 0 − μ 1 \bm{\mu_0 - \mu_1} μ0−μ1,令
S b ω = λ ( μ 0 − μ 1 ) \bm{S_b\omega = \lambda(\mu_0 - \mu_1)} Sbω=λ(μ0−μ1) - 于是带入得
ω = S ω − 1 ( μ 0 − μ 1 ) \bm{\omega = S_{\omega}^{-1}(\mu_0 - \mu_1)} ω=Sω−1(μ0−μ1)
多分类学习
不失一般性,考虑N 个类别C1 , C2 ,… , CN , 多分类学习的基本思路是"拆解法飞即将多分类任务拆为若干个二分类任务求解.具体来说,先对问题进行拆分,然后为拆出的每个二分类任务训练一个分类器;在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。这里的关键是如何对多分类任务进行拆分,以及如何对多个分类器进行集成。
最经典的拆分策略有三种. “一对一” (One vs. One,简称OvO) 、“一对多” (One vs. Rest ,简称OvR)和"多对多" (Many vs. Many,简称MvM).
类别不平衡
加入有998个反例,2个正例,那么学习方法只需要放回一个永远将新样本预测为反例的学习器,就能达到99.8%的精度。
解决办法:
- 对数据过多的一方进行欠采样
- 对数据过少的一方进行过采样
- 基于原始数据集进行学习,但是在用训练好的分类器进行预测时,加入一个策略到其决策过程,成为“阈值移动”。
y ′ 1 − y ′ = y 1 − y ∗ m − m + \frac{y^{'}}{1-y^{'}} = \frac{y}{1-y} * \frac{m^-}{m^+} 1−y′y′=1−yy∗m+m−
m − 、 m + m^-、m^+ m−、m+分别为正反例数目