Recsys2018 总结 (推荐系统最新技术、应用和方向)32篇论文解读
本文对10月2-7号在加拿大渥太华举办的Recsys的32篇论文做了整理和归纳,总结出了目前推荐系统最新技术应用和方向。并对每一篇文章做了粗略的讲解。

我打算从以下四个方面来讲述这32篇论文。
-
首先呢,我会概述一下大会论文反映的一些情况。
-
然后分析一下这些论文中用到的技术、应用的场景以及数据集。
-
再将这32篇论文分类并详细的讲述一下。
-
最后对着32篇论文如何去解决推荐中的经典问题,做一个总结。
把对我们有用的论文总结出来,供大家后续研究。

首先我来概述一下这次会议录用论文的情况。
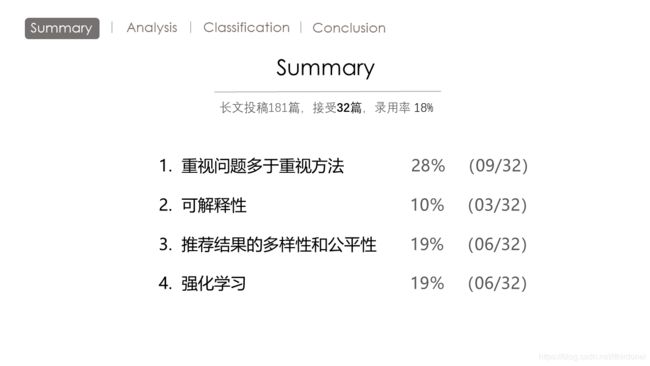
这一次长文投稿181篇,接受了32篇,录用率18%。
看完这些论文,最最重要的一个感觉是,这个会议更在乎研究的问题是什么?是否有意义,是否新颖有趣.
我感觉这个会议没有那么注重算法上的创新。而更多的是讨论某个具体的推荐场景下问题如何解决。
很多的工作都是将一些已有的方法进行变形之后,应用到新的更具体的问题上。 所以我感觉对于推荐系统大会来说,好的问题是文章成功的一半。
下面这三点是这次大会论文录用比较多的三个点。
- 首先说一下可解释性。可解释性无非就是让用户知道推荐系统为什么给给我推这个。
最近几年越来越多的推荐算法开始注重推荐结果的可解释性,希望能与用户产生沟通交流,直接增强用户体验,用户体验好了之后,用户爱用了就间接的增强了推荐效果。 - 另外一个呢就是推荐结果的公平性和多样性。
如果我们在推荐中呢,只考虑推荐的准确性,那么方法很容易就陷入一个单一类别的局部最优解。会议上的有很多有趣的工作,就是说用bandit等算法引入多样性。
公平性呢,是一个暂时没有具体的衡量标准问题。如果只用均衡来作为标准的话,多样性和公平性其实是一致的。 也就是说多样了,也就意味着我公平了。 - 最后呢,还要说一下强化学习。最大会有六篇文章,用了强化学习的方法。
下面呢,我要从这三个方面分析一下这次大会将推荐系统应用的场景以及最新用到的一些技术,还有数据集。

这次推荐大会呢,录用的新问题很多,所以应用场景很多,尤其是新的场景特别多。 比较新的像是英雄推荐游戏里的英雄推荐,然后电信移动服务商里的电信绑定套餐业务推荐。以及像百度地图中的交通路线推荐还有就是问答系统中回答问题的专家推荐。还有互补商品推荐。互惠推荐,多角色推荐。

再说一下出现的技术。
因为解决的问题多种多样,用到的技术也很多,这里并没有把所有的技术放在这儿,具体的哪篇论文用到了哪个技术还要在后面具体的说。
给我印象比较深的呢,就是强化学习用到的比较多。
最后说一下数据集的情况。
数据集依场景的不同和方法而不同。这里总结了这么几个。

这一部分呢,将会对32篇论文概括的讲述一下。
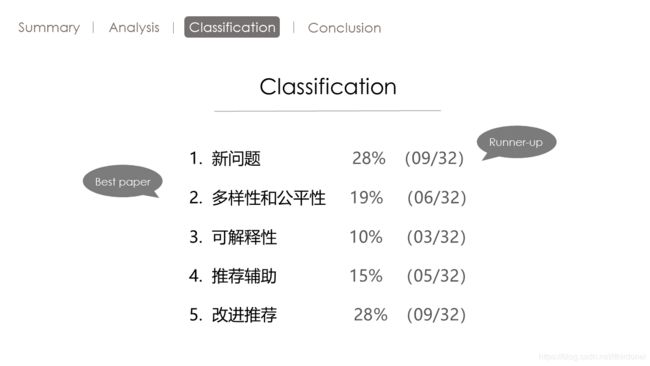
我主要将这32篇论文分为五个方面。
-
第一个部分呢,就是先讲述一下这次大会提出的新的应用场景。 总共有九篇论文,占了大会全部论文的28%。
-
第二部分呢,再讲一下关于多样性和公平性的论文, 总共有六篇论文占了全部大会,全部论文到19%。
-
第三部分呢,要讲述一下推荐系统中可解释性的论文, 总共有三篇论文,占了全部大会论文的10%。
-
第四部分的,讲述一下推荐辅助相关的论文。
推荐辅助是啥意思呢?就是说这些论文不是直接的提出新的推荐算法,而是对已有的推荐算法进行了研究,发现其中的一些问题。
-
最后呢讲述一下,提出的新算法来改进已有的推荐场景的论文。
总共有九篇文章,占了大会全部论文的28%。
这一部分呢,是新问题的一些论文。
第一篇我要讲述的论文是这篇。
作者的问题很新。
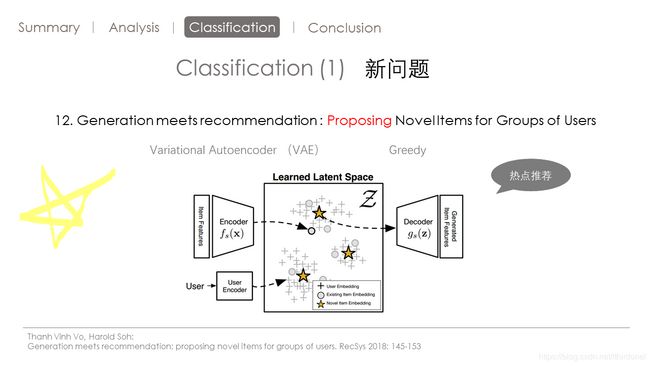
作者希望用系统生成新的物品。生成的物品呢,能够让用户都喜欢。
作者举了一个真实场景的例子。比如说呢,设计团队想要设计一款手机,让所有的人都喜欢。像iPhone样,就是做一个大家都喜欢的手机。无论卖菜的老大妈,是文艺青年还是学生啊这些群体都喜欢。
作者要解决的问题呢,就是要覆盖所有用户群体的兴趣。
这篇文章基本的想法呢,就是使用变分自动编码器vae,首先将用户和物品的特征放入这个隐因子的空间里。然后使用贪婪算法,在隐因子空间中选点,然后覆盖所有的用户,最后通过decoder产生新的item。
这一页呢是另外的三个新问题。
第五篇呢是交通推荐的问题。啥是交通推荐的问题呢?就是像百度地图呀,谷歌地图呀,给用户推荐出行的路线。
这篇文章的作者同样是推荐路线。但他不同的是,它不像百度地图,谷歌地图这样推荐哪些路线最快。哪些路线收费最低。
他推荐的是哪些路线更舒服。作者总结了几个影响路线舒适度的因子。设计了一个推荐算法。进行推荐。评价标准呢,是找了50个人。调查了一下。这50个人说你这个APP比谷歌地图1批推荐的路线更舒适。并且舒适30%。
这个第六篇。是京东投稿的。
他的新场景主要是一个页面推荐。
需要用一个页面覆盖住用户最感兴趣的不同分类的东西。
然后要做到实时的反馈。就是用户跑出去购物回来再看这个页面就变了。作者用强化学习解决了这个问题。
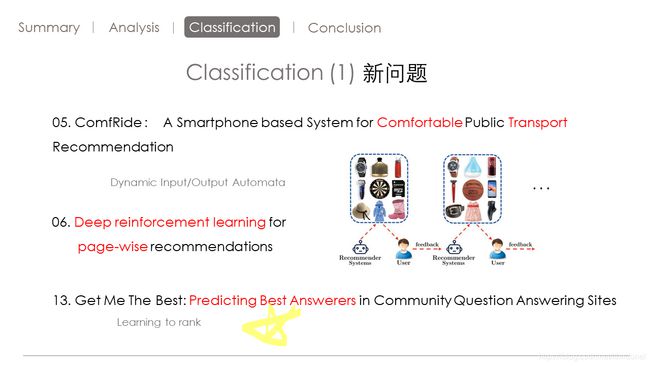
第13篇,是问答系统中预测最佳回答者。
这个场景,就像知乎问答似的。知乎里有很多人提问题。但是很多问题得不到解决。需要一种推荐回答的算法。
作者用了learn to rank结合各种推荐算法(包括文本的标签的用户行为的)来找问题的最佳的回答者。
第19篇。
给用户推荐使得用户喜欢,并且使得店家能够收益,然后降低平台的损失风险。
第21篇呢,是一个电信服务套餐绑定的场景。
像我们移动联通电信这些运营商会有一些特殊的套餐推荐给用户。比如这个用户常用爱奇艺可以给他推荐一个爱奇艺,免流量的这么一个套餐。
这篇文章就是解决了一个这样的问题。
第29篇。这是一个游戏中英雄阵容推荐的。
moba就是多人在线对抗的游戏。lol王者荣耀这种游戏。
这种游戏一般分成两个队伍。每个队伍有五个人。当每个队伍中都有一个人选择了英雄的时候。这个推荐系统就会推荐下面的人选择什么英雄胜率比较高。

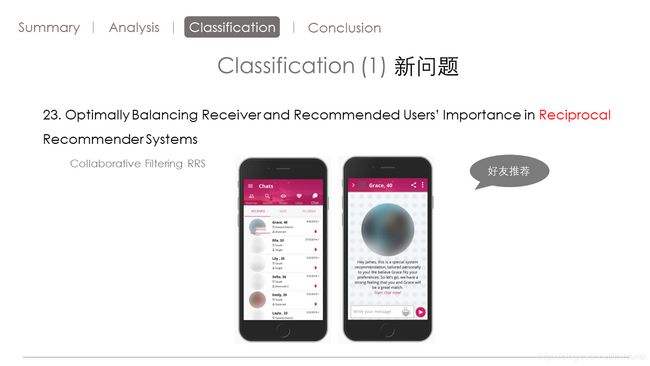
第23篇,它是一个互惠推荐系统。
像我们日常生活中用的探探boss直聘,这些软件中有两两方面的用户。像探探这种在线约会的软件,男的是一方,女的是一方。要给男的推荐女的,又要给女的推荐男的。这样给双方推荐的就是一个互惠的推荐。
像boss直聘也是一样,就要给老板推荐员工,也要给员工推荐老板提供的职位。
第26篇呢,是一个物品互补的推荐。
向我们购买商品时。买了一个相机。这个时候呢,像相机套呀,镜头呀,自拍控制杆呀,镜头套呀,这些东西就可以被推荐了。
互补推荐系统会在这里面给我们推荐一些我们最可能买的。

到这里呢,全部的九个新问题就说完了,
下面开始讲推荐系统中的多样性和公平性的问题。
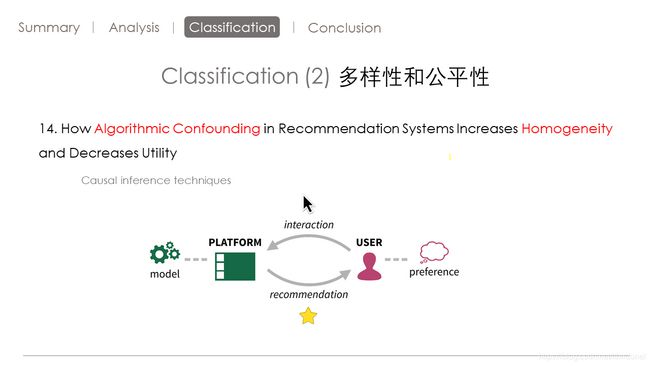
第14篇文章讲了一个算法混淆的概念。
什么是算法混淆呢。
我在日常生活中就遇到过。就是我在bilibili上看了几个学习的视频。然后呢,我下一次再去这个应用程序。他就一直给我推的视频。我就没法再看其他的视频了。我就一直看学习的视频。然后他还一直推学习的视频,竟然陷入了一个恶性循环中。
这样呢,推荐系统就增加了同质性,丧失了多样性。降低他的推荐效果。
作者在这篇文章中详细的说明了这个算法混淆是如何危害我们的。
后面的几篇文章就是解决这个算法混淆带来同质性的问题。
第二篇文章呢提出了一个calibrated的概念。
calibrated的是什么呢?
它是按比例推荐。也就是说用户看了99%的学习的。看了1%的娱乐的。
如果是一般的推荐系统,就只给用户推荐他主要的兴趣。
而这里按比例推荐的,就是遵从以前的用户看的这个比例。也给用户推99%学习的和1%娱乐的。这样做到了多样性。
第四篇文章
作者讲述了一个这样的问题。
就是很多推荐系统呢,为了某些商业的目的,如何增加点击率和下载量,试图改变用户本身的自然行为,所以我们看到用户点击或者是下载的时候,其实是已经受了推荐算法影响的。这个问题其实就是一个算法混淆的问题。
在这里呢,作者利用因果推理的这么一个技术,在这里也用到了强化学习,然后消除了算法带来的误差。
下面是第九篇文章。
第九篇文章呢是社交网络中链接的推荐。
作者通过一个弱关系的推荐还增强了推荐的多样性。
这篇文章的能对我们的好友推荐,有借鉴意义。

第11篇文章是
作者发现图书推荐中对图书作者性别推荐呈现出歧视女性的现象,本文讲述了这些推荐系统是如何的歧视女性。
第31篇论文的是改进了一个 AOA的评估器。
使推荐系统免受流行度偏差的影响。

这些呢,就是对所有的多样性和公平性文章的一个讲解。
下这一部分是推荐系统的可解释性。
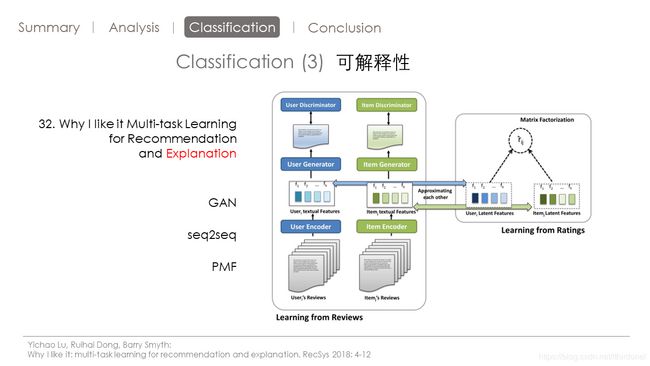
第32篇论文
这篇论文作可解释性的主要思路是从评论中生成对用户行为的解释。
模型下面呢,是输入用户的评论和物品的评论。我的评论就是这个用户对所有的物品的评论物品的评论呢就是这个物品被所有的用户的评论。
然后这个模型引入了上下文感知扩展的概率矩阵分解
又结合从评论文当中学习的文本特征,
最后预测的评级以及对评级的解释。
第十篇论文呢
主要思想是利用bandit对推荐的解释。
强化学习里的两个概念探索和利用。探索呢就是把不确定用户喜不喜欢的商品推荐给用户。来探索用户到底喜欢啥。利用呢就是说从用户已知的用户喜欢的东西里找到用户最喜欢的。
第25篇论文呢,是对互惠推荐系统做解释。
右图中呢,作者对互惠推荐系统的解释,做了一个展现。
给这个用户推荐这个女的是因为喜欢西班牙语艺术,然后学识还高,所以给这个男的推荐这个女的。是这样作出的解释。

这篇论文和前面讲到第23篇论文是同一批人做的
师兄跟我们说,让我们好好努力,然后一块儿把咱们的APP放上去(学术头条https://www.acheadline.com),发一批论文,起到一个广告效应。
到这里呢,可解释向他推荐就说完了,下面呢要说一下辅助推荐的一些方法。
第八篇文章
作者对推荐系统中什么时候用成对的偏好做了一个调查。
得到的结论是在主动搜索的时候,也就是说目标明确的时候,用成对的偏好数据效果更好。
第七篇文章呢,
讲了一个用户控制对推荐的影响。
用户控制呢,就是说让用户在界面上可以选择,我不喜欢这篇文章这种。
作者在文中找到了一个这样用户用的开心又能推荐的好的一个平衡点。
第17篇文章
我们在使用推荐系统时,经常关注的是用户的反馈,就像用户的点击用户的打分呀。而作者呢,是从用户没有操作的角度来分析。浙江用户的不作为分为了七类,然后将推荐问题转化成一个分类问题。
第18篇论文主要研究了物品相似度算法与推荐质量的关系。
得到了一个结论,基于内容的推荐算法,在相似度和推荐质量方面要优于基于用户行为的。
第22篇论文呢是对Top推荐中应用的信息检索6个评价的指标进行了一个鲁棒性和辨别力能力的一个调查。
结果显示precision 鲁棒性最好。NDCG有最好的辨别力。

辅助推荐的论文就讲完了,下面讲述改进推荐算法的论文。
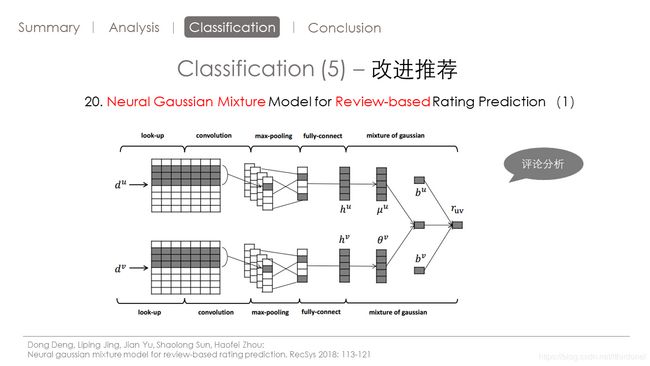
第20篇论文呢,
主要思想呢就是利用评论评论来进行评分预测。
创新点 高斯混合模型代替了矩阵分解来进行评分的预测。
模型的输入是一个用户对物品的所有评论。以及一个物品被所有用户的评论。最后得到这个用户对这个物品的评分。
我觉得前部分是对评论进行embeding 后面的部分呢是输入到高斯混合模型中,得到结果。
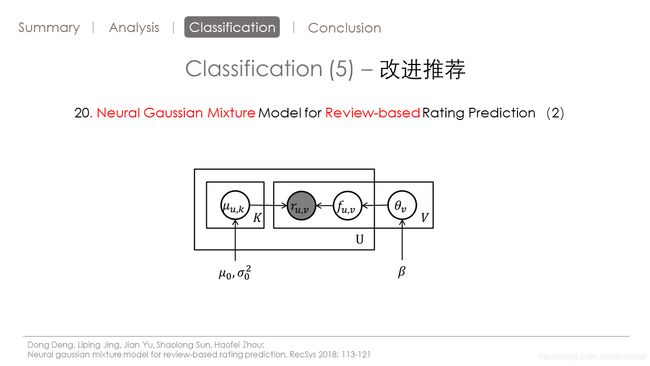
第二张图呢,就是高斯混合模型。
第一篇文章呢,
讲述了一个实时的推荐。
在这个推荐中呢,还解决了冷启动问题。
作者利用了一个滑动窗口的机制检测新数据的到来。
然后利用增量的矩阵分解和主题模型,实时对新数据进行推荐,生成评分。
第三篇文章呢,是讲如何将分类信息用于推荐
第15篇文章
这篇文章提出了一个单调行为链的概念。
作者发现评论行为暗含着购买行为,进一步暗含着点击行为。
作者开发了一种利用这种依赖关系的新算法来进行推荐。

第16篇文章呢,
讲了利用bandit来解决用户行为稀疏的问题。
设计了一种新的深度神经记忆增强机制,通过用户历史行为来建模用户的历史状态,从而在少量的交互中快速的学习用户对新项目的偏好。
第24篇文章主要解决冷启动问题。
通过一个静态偏好问卷,然后获得用户的相对偏好,从而产生推荐。

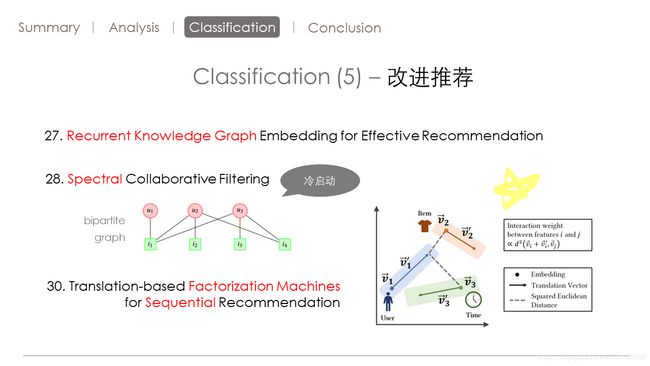
第27篇文章适用知识图谱来解决推荐问题
第28篇文章适用二分图来解决推荐问题。
作者将用户和商品之间的关系构成了二部图,然后提出了谱域的普卷积算子不仅可以揭示图中临近的信息,而且可以揭示隐藏在图中的连接信息。
然后作者构建了深层的推荐模型,谱协同过滤。
这样就可以发现用户和商品之间的深层连接进而缓解能启动问题。
第30篇文章
讲述了一个用于序列推荐的算法。
这个算法将转移和度量的方法与因子分解及模型结合起来。
利用平方欧式距离来计算特征之间交互的强度。不用内积
还将内容的特征融入进去,提升了推荐的效果。
总结。
给他推荐系统中存在的问题三个主要问题
冷启动问题,多样性性和公平性问题,可解释性问题。
解决这些问题的方法有这些。

这里总结了一些其他分类论文的编号
APP(学术头条https://www.acheadline.com)

