机器学习算法-逻辑回归(LR)
给定多元输入 x=(x1,x2,...,xn)T ,让预测其可能的输出 y 。遇到此类问题,稍微学习过高等数学或统计分析的人,大脑中首先闪现的方法肯定是线性回归!找到如下的关系式:
那么任何时候给定任何值,都可以轻而易举地得到对应的输出。虽说线性回归分析简单直观、易于理解,但是如何确定参数 w 和 w0 却是让人头疼的问题。常用的方法就是提前观察到一组输入-输出值: (x1,y1) 、 (x2,y2) 、… 、 (xn,yn) ,再利用优化问题
确定参数 w 和 w0 ( 监督学习)。知道 w 和 w0 后就可以用得到的回归关系式愉快的玩耍了。
可回归与分类又有什么关系呢?其实分类问题也是预测问题:给定样本对象值,预测其可能属于的类别。既然同样是预测问题,那便可以用回归的思想来进行建模。不过稍微深入的思考一下便会发现,直接利用线性回归关系进行分类预测是不可取的。因为一般分类问题的可能输出都是离散有限的,而线性回归的输出域却是 (−∞,∞) 。在知道了输入对象的值后,明显无法清晰直观的通过回归关系进行类别判定。那是不是回归分析就不能用于预测分类,答案明显是否定的。
虽说线性回归无法直接用于分类预测,但可以对其加层映射:将连续无穷输出映射到指定的有限输出。逻辑回归(Logistic Regression, LR)便是基于此思想在线性回归的结果上加上一个逻辑函数,将连续输出映射到 [0,1] 输出。逻辑回归是统计学习中的经典分类方法,通过历史数据的表现对未来结果发生的概率进行预测分类,概率大于一定阈值,输出为1,否则输出为0。
一、逻辑函数
在展开描述逻辑回归之前,先隆重介绍一下逻辑函数。设 x 是连续随机变量,则其对应的逻辑函数的数学形式是:
g(x) 的图形是一条S形曲线,该曲线以点 (0,12) 为中心对称,即满足:
曲线在中心 (0,12) 附近增长速度较快,在两端增长速度较慢。具体的形状如下图所示:
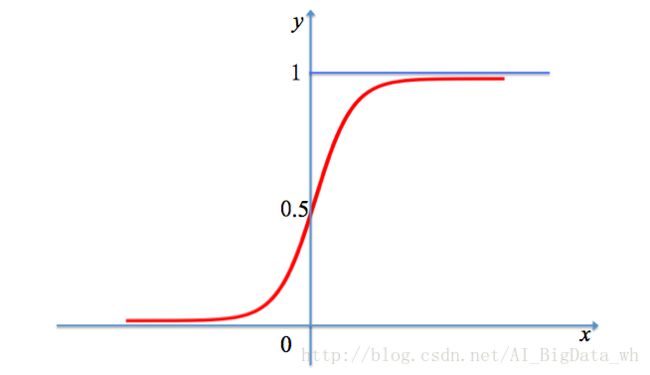
二、逻辑回归
利用逻辑函数映射的逻辑回归主要被用于二分类问题(多分类问题会在另外一篇博客中介绍),由条件概率分布 P(x|y) 表示。其中 x 为 m 维的取值为实数的随机变量,而随机变量 y 的取值被限定为0或1。具体的表达形式是:
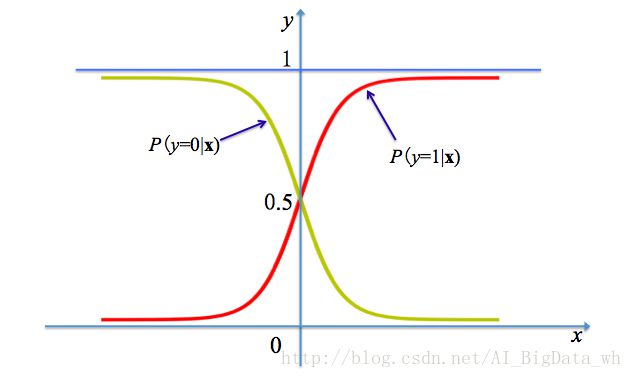
假定现在给出新的样本 x ,按照上面两个等式可以分别计算出 P(y=1|x) 和 P(y=0|x) ,如果 P(y=1|x)≥P(y=0|x) ,则样本 x 被分到 y=1 类,如果 P(y=1|x)<P(y=0|x) ,则样本 x 被分到 y=0 类。
三、模型参数估计
如同线性回归一样,要想利用逻辑进行分类预测,需要先获得参数 w 和 w0 的值,此时便需要先定义一个评判指标,接下来通过不断地优化此指标以得到参数 w 和 w0 。
对于逻辑回归分类问题,可以利用常见的损失函数(Loss function)来构建成本函数(Cost function)作为优化目标。不过0-1损失函数或平方损失函数虽说可以很好地表征其效果,不过二者的结果均是离散的,无法通过有效的优化方法求得结果。
考虑一下逻辑回归的输出定义,可以看到其是以条件概率作为类别的评判准则,那么可以利用极大似然估计法估计模型参数。极大似然原理的直观想法是,一个随机试验如有若干个可能的结果 A , B , C , … ,若在一次试验中,结果 A 出现了,那么可以认为实验条件对 A 的出现有利,也即出现的概率 P(A) 较大。
为简化后续的描述,对于单个样本对象 (xi,yi) 先做如下设定:
将上面两个等式进行合并,可表述为:
因此对于给定的训练集 T={(x1,y1),(x2,y2),…,(xn,yn)} ,似然函数为:
通过求解如下优化问题,便可挑选参数 w 和 w0 的极大似然估计值 w¯ 和 w¯0 :
问题是如何求解上面的优化问题才能把参数 w 和 w0 的极大似然估计 w¯ 和 w¯0 求出。更多场合是利用 lnL(w,w0) 是 L(w,w0) 的增函数,故 lnL(w,w0) 与 L(w,w0) 在同一点处达到最大值,于是对似然函数 L(w,w0) 取对数对数似然函数为:
这样问题就变成以对数似然函数为目标函数的最优化问题,解如下方程求得极大值,对应的解便是 w 和 w0 的估计值:
假设已经求得 w 和 w0 的极大似然估计值为 w¯ 和 w¯0 ,那么学习到的逻辑回归模型为:
四、逻辑回归优缺点
1. 优点:预测结果是界于0和1之间的概率,训练简单、容易使用和解释;可以适用于连续性和类别性自变量。对于类别形自变量,只需要进行数值转换即可,如收入、中、低 → 0、1、2,性别男、女 → 0、1;分类时计算量非常小,速度很快,存储资源低;对多重共线性问题,可以结合正则化来解决。
2. 缺点:当特征空间很大时,逻辑回归的性能不是很好,容易欠拟合;只能处理两分类问题(在此基础上衍生出来的Softmax可以用于多分类),且必须线性可分;对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性。
五、逻辑回归R实战
基于IRIS数据集进行测试,不过逻辑回归只支持二分类,因此训练时选取1-100的样本,其中1-50条样本属于setosa类,剩下的50条样本属于versicolor类。
data_sample <- iris[1:100,];
m <- dim(data_sample)[1] #获取数据集记录条数
val <- sample(m, size =round(m/3), replace = FALSE, prob= rep(1/m, m)) #抽样,选取三分之二的数据作为训练集。
iris.learn <- data_sample[-val,] #选取训练集
iris.valid <- data_sample[val,] #选取验证集
logit.fit <- glm(Species~.,
family = binomial(link = 'logit'),
data = iris.learn);
real_sort <- iris.valid$Species; #测试数据集实际类别
prdict_res <- predict(logit.fit, type="response", newdata=iris.valid); #预测数据产生概率
res1 <- data.frame(predict=prdict_res, real=real_sort); #查看数据产生概率和实际分类的关系
res2 <- data.frame(predict=ifelse(prdict_res>0.5, "virginica", "versicolor"), real=real_sort); #根据数据产生概率生成预测分类
res3 <- table(data.frame(predict=ifelse(prdict_res>0.5, "virginica", "versicolor"), real=real_sort)); 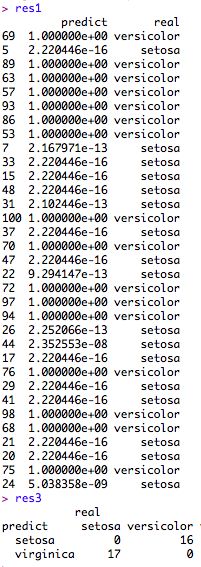
参考资料
- http://blog.sina.com.cn/s/blog_5dd0aaa50102vjq3.html 逻辑回归优缺点
- https://item.jd.com/10975302.html 统计学习方法 李航
- http://blog.csdn.net/comaple/article/details/45062489 R语言数据分析系列之九 - 逻辑回归