100 Days Of ML Code 学习笔记-Day 1
100Days的学习用的都是PyCharm工具
数据预处理
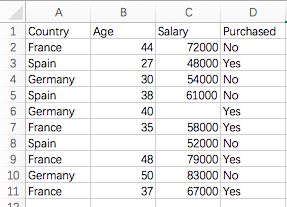
我们先看下数据:Data.csv, 相应的数据可以在:https://github.com/Avik-Jain/100-Days-Of-ML-Code/blob/master/datasets/Data.csv 中下载(右击“Raw”然后另存为即可)
1.导入需要的库:NumPy和Pandas,前者里边包含了很多数学中的计算函数,后者是用来导入和管理数据集的;
import numpy
import pandas2.导入数据集:通常都是.csv格式的,可以用Pandas的read_csv方法进行读取,每一个metrics都会包括两个部分,独立变量(independent-variables)和依赖变量(dependent-variables), 即自变量和因变量;
#文件我给的是存储在我的电脑里的路径,默认就是带有header的,如果表中无header,那么加一个:header= None即可
dataset = pandas.read_csv('/Users/agnes/Downloads/100Days/Data.csv')
#自变量X取的是表中A2:C11的数据
X = dataset.iloc[ : , :-1].values
#因变量Y是取的是表中D2:D11的数据
Y = dataset.iloc[ : , 3].values3.处理丢失的数据:用整列的平均值或者是中间值去替换丢失的数据,可以用sklearn.preprocessing库中的Imputer完成该任务;
from sklearn.preprocessing import Imputer
#缺失的值我们用NaN代替,用平均值填充,axis是int类型,初始值的默认值为0
#axis用来计算means 和standard deviations时如果是0,则单独的标准化每个特征(列),如果是1,则标准化每个观测样本(行)
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
#对表中B2:C11进行fit
imputer = imputer.fit(X[ : , 1:3])
#将fit后的数据应用到表中
X[ : , 1:3] = imputer.transform(X[ : , 1:3])4.解析分类的数据:分类数据是指含有标签值而不是数字值的变量,取值范围通常是固定的,例如Yes和No,不能用于模型的数学计算,所以需要解析成数字,我们用sklearn.preprocessing库中的LabelEncoder完成该任务;
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
labelencoder_X =LabelEncoder()
#fit_transform 和transform的区别在http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html中有讲解
X[:,0] = labelencoder_X.fit_transform(X[:,0])
#对第一列特征进行编码
onehotencoder = OneHotEncoder(categorical_features=[0])
#创建虚拟变量,用完labelencoder之后还要用onehotencoder对表示分类的数据进行扩维
X = onehotencoder.fit_transform(X).toarry()
#这里没有对Y进行onehotencoder是因为最后一列只有两种分类
labelencoder_Y = LabelEncoder()
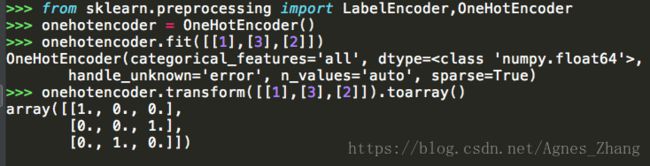
Y = labelencoder_Y.fit_transform(Y)关于onehotencoder扩维,这里举个例子说明一下, one hot encoding它的值只有0和1,从图中可以看到数组用onehotencoder扩维之后,[1., 0., 0.]是对[1]进行编码,[0., 0., 1]是对[3]进行编码,[0., 1., 0.]是对[2]进行编码:
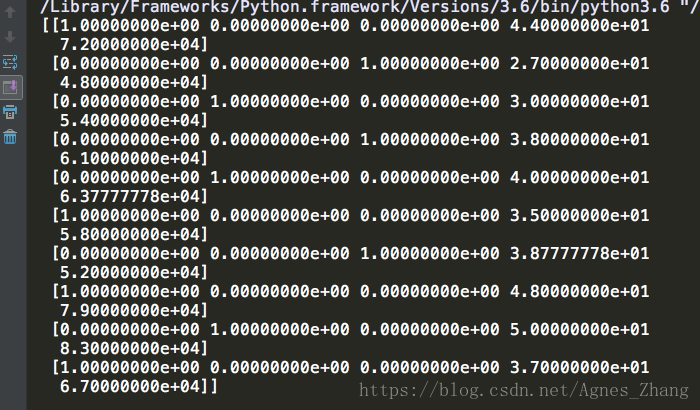
那么表中的X数据集经过以上的处理就会变成这样,其中数组的每一条中的前三个数是用来编码‘County’的,然后’Age’和’Salary’没变:
5.拆分数据集为训练集合和测试集合:把数据集拆分为两个,一个是用来训练模型的训练集合,另一个是用来验证模型的测试集合,两者比例为80:20,即4:1,那么test_size即为0.2,可以用sklearn.cross_validation库中的train_test_split()完成该任务;
from sklearn.cross_validation import train_test_split
#random_state为随机数种子,用于产生随机序列
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2,random_state=0)在我的电脑里面,cross_validation模块写上去的时候被自动画上了一条横线,说明该模块被弃用了,我们可以改为model_selection这个模块,如下:
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2,random_state=0)这里补充一下:train_test_split的参数X即train_data表示所要划分的样本特征集;Y即train_target表示所要划分的样本结果;test_size表示样本占比,若是整数则表示样本数量;random_state:随机数种子。
6.特征量化:大多数机器学习算法使用两点间的欧几里德度量来表示,因为每个变量的范围不同,若两个变量之间差距过大,则会导致距离对结果产生影响,因此要对数据进行标准化改变,将数据缩放至较小的数, 可用特征标准化或Z-score标准化方法解决。这里我们用sklearn.preprocessing库中的StandardScalar类完成该任务。
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)Day 1 到此结束