爬虫+数据探索01-贝壳找房北京二手房信息数据
目录
项目简介
数据获取
1.爬虫
2.数据处理
3.数据探索
-
项目简介
爬取贝壳找房北京二手房信息数据,并整理成可分析数据
-
数据获取
(修正后数据链接:链接:https://pan.baidu.com/s/1C3_eseM-wjW3mo-WUvgCGw 提取码:73iw )
1.爬虫
从贝壳找房爬取北京二手房最新数据,代码如下:
import re
import requests
import pandas as pd
import numpy as np
#北京区域
def get_region(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer": "https://bj.ke.com/ershoufang/"}
proxies = {"HTTP": "113.108.242.36:47713"}
r = requests.get(url, headers=headers, proxies=proxies)
region_re = re.compile(r'''''')
region = re.findall(region_re, r.content.decode('utf-8'))
return region
#北京区域小区价格详情
def get_data(region):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer": "https://bj.ke.com/ershoufang/"}
proxies = {"HTTP": "113.108.242.36:47713"}
for i in region:
urll = url + i + '/'
position = []
house = []
price = []
unitprice = []
for j in range(1, 51):
urlll = urll + 'pg' + str(j) + '/'
rr = requests.get(urlll, headers=headers, proxies=proxies)
position_re = re.compile(r'''.*?(.+?)''', re.S)
house_re = re.compile(r'''.*?\n\s(.*?)''', re.S)
price_re = re.compile(r'''(.*?)''', re.S)
u_re = re.compile(r'''''', re.S)
p = re.findall(position_re, rr.content.decode("utf-8"))
h = re.findall(house_re, rr.content.decode("utf-8"))
pr = re.findall(price_re, rr.content.decode("utf-8"))
u = re.findall(u_re, rr.content.decode("utf-8"))
position.extend(p)
house.extend(h)
price.extend(pr)
unitprice.extend(u)
data = pd.DataFrame()
data['position'] = position
data['house'] = house
data['price'] = price
data['unitprice'] = unitprice
df = data.to_csv("{}_data.csv".format(i), index=False)
#制作函数
def func():
url = "https://bj.ke.com/ershoufang/"
region=get_region(url)
data=get_data(region)
if __name__=='__main__':
func()
2.数据处理
根据爬虫下来的数据,需要拆分字段house 里的信息,变成【'floor','build_year','house_type','house_Size','house_orientation'】,同时需要判断是否含电梯(判断依据>6曾为电梯小区),具体代码如下:
#导入第三方库
import pandas as pd
import numpy as np
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
#Read and Combine
region=['dongcheng', 'xicheng', 'chaoyang', 'haidian', 'fengtai', 'shijingshan', 'tongzhou', 'changping', 'daxing',
'yizhuangkaifaqu', 'shunyi', 'fangshan', 'mentougou', 'pinggu', 'huairou', 'miyun', 'yanqing']
data_dongcheng=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\dongcheng_data.csv",encoding='utf-8'))
data_xicheng=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\xicheng_data.csv",encoding='utf-8'))
data_chaoyang=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\chaoyang_data.csv",encoding='utf-8'))
data_haidian=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\haidian_data.csv",encoding='utf-8'))
data_fengtai=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\fengtai_data.csv",encoding='utf-8'))
data_shijingshan=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\shijingshan_data.csv",encoding='utf-8'))
data_tongzhou=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\tongzhou_data.csv",encoding='utf-8'))
data_changping=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\changping_data.csv",encoding='utf-8'))
data_daxing=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\daxing_data.csv",encoding='utf-8'))
data_yizhuangkaifaqu=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\yizhuangkaifaqu_data.csv",encoding='utf-8'))
data_shunyi=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\shunyi_data.csv",encoding='utf-8'))
data_fangshan=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\fangshan_data.csv",encoding='utf-8'))
data_mentougou=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\mentougou_data.csv",encoding='utf-8'))
data_pinggu=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\pinggu_data.csv",encoding='utf-8'))
data_huairou=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\huairou_data.csv",encoding='utf-8'))
data_miyun=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\miyun_data.csv",encoding='utf-8'))
data_yanqing=pd.read_csv(open(r"C:\Users\angella.li\PycharmProjects\untitled\angella_1\yanqing_data.csv",encoding='utf-8'))
data_dongcheng['region']=['dongcheng']*len(data_dongcheng)
data_xicheng['region']=['xicheng']*len(data_xicheng)
data_chaoyang['region']=['chaoyang']*len(data_chaoyang)
data_haidian['region']=['haidian']*len(data_haidian)
data_fengtai['region']=['fengtai']*len(data_fengtai)
data_shijingshan['region']=['shijingshan']*len(data_shijingshan)
data_tongzhou['region']=['tongzhou']*len(data_tongzhou)
data_changping['region']=['changping']*len(data_changping)
data_daxing['region']=['daxing']*len(data_daxing)
data_yizhuangkaifaqu['region']=['yizhuangkaifaqu']*len(data_yizhuangkaifaqu)
data_shunyi['region']=['shunyi']*len(data_shunyi)
data_fangshan['region']=['fangshan']*len(data_fangshan)
data_mentougou['region']=['mentougou']*len(data_mentougou)
data_pinggu['region']=['pinggu']*len(data_pinggu)
data_huairou['region']=['huairou']*len(data_huairou)
data_miyun['region']=['miyun']*len(data_miyun)
data_yanqing['region']=['yanqing']*len(data_yanqing)
df=pd.concat([data_dongcheng,data_xicheng,data_chaoyang,data_haidian,data_fengtai,data_shijingshan,
data_tongzhou,data_changping,data_daxing,data_yizhuangkaifaqu,data_shunyi,data_fangshan,
data_mentougou,data_pinggu,data_huairou,data_miyun,data_yanqing])
拆分floor里房屋信息,重置index,并且删掉floor里包含‘共层’字段,为判断是否有电梯准备并添加电梯
#删掉空格和回车
def WS(x):
x=x.replace(' ','')#替换空格
x=x.replace('\n','')#替换换行
return x
df.house=df.house.apply(lambda x:WS(x))
#拆分数据
x=df.iloc[:,1]
def splitt(x):
x=x.split(r'|',4)
return x
x=x.apply(lambda x:pd.Series(splitt(x)))
x.rename(columns={0:'floor',1:'build_year',2:'house_type',3:'house_Size',4:'house_orientation'},inplace=True)
df=pd.concat([df,x],axis=1)
df=df.drop('house',axis=1)
#电梯判断
df=df[~df['floor'].str.contains('共层')]
df=df[~df['build_year'].str.contains('米')]
df.index=range(len(df))
elevator=[]
floor=[]
import re
for i in range(len(df)):
aa=re.search((r'[0-9]{1,}'),df.floor[i])
bb=int(aa.group())
floor.append(bb)
if (bb>6):elevator.append(1)
else:elevator.append(0)
df['elevator']=elevator
df.head()
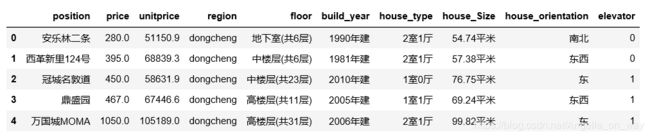
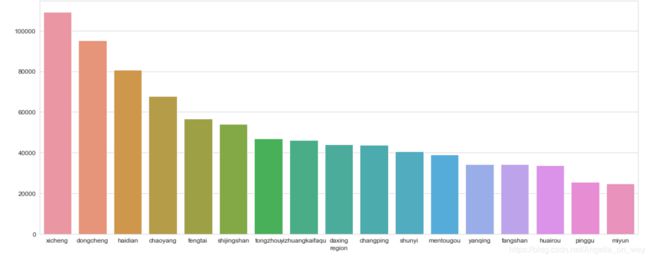
3.数据探索
1. 查看不同区域房屋平均单价(单位:元),西城区的平均单价已经超10万一平,东城均价超9万一平,海淀区均价在8万左右。
#导入第三方库
import matplotlib
from matplotlib import pyplot as plt
import seaborn as sns
data_1=df.groupby('region').unitprice.mean().sort_values(ascending=False)
matplotlib.rcParams['figure.figsize']=(20,8)
matplotlib.rcParams['font.size']=12
sns.set_style('whitegrid')
sns.barplot(x=data_1.index,y=data_1.values)
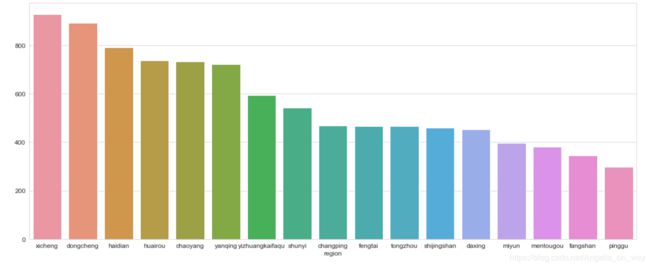
2.查看不同区域房屋总价情况(单位:万元),西城/东城/海淀为总价最高三个区域,延庆和顺义靠前,说明出售的房屋面积比较大。
data_2=df.groupby('region').price.mean().sort_values(ascending=False)
matplotlib.rcParams['figure.figsize']=(20,8)
matplotlib.rcParams['font.size']=12
sns.set_style('whitegrid')
sns.barplot(x=data_2.index,y=data_2.values)
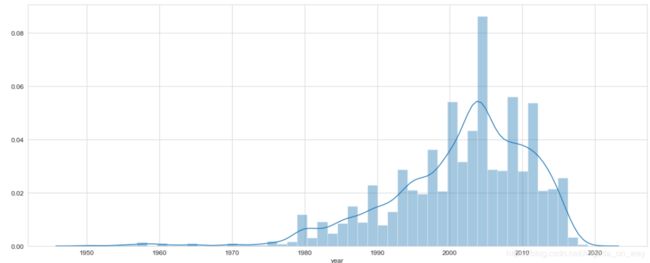
3.出售房屋的建造时间,由于爬虫下来的数据会存在缺失值或者数据为其他非时间内容,会有删除一些行的操作。2000-2010年之间建造的房子是出售的主力军
#房屋建造时间
bb=[]
for i in range(len(df.build_year)):
aa=re.search(r'[0-9]{4}',df.build_year[i])
bb.append(aa.group())
data_3=pd.concat([df.build_year,pd.Series(bb)],axis=1)
data_3=data_3.rename(columns={'build_year':'build_year',0:'year'})
data_3.year=data_3.year.map(int)
data_3.info()
matplotlib.rcParams['figure.figsize']=(20,8)
matplotlib.rcParams['font.size']=12
sns.set_style('whitegrid')
sns.distplot(data_3.year,hist=True)
4.房屋大小影响
#房屋大小角度
def SS(x):
x=x.replace('平米','')
return x
data_4=df.house_Size.map(lambda x:SS(x))
data_4=data_4.map(float)
matplotlib.rcParams['figure.figsize']=(20,8)
matplotlib.rcParams['font.size']=12
sns.set_style('whitegrid')
sns.distplot(data_4[data_4<500],hist=True)
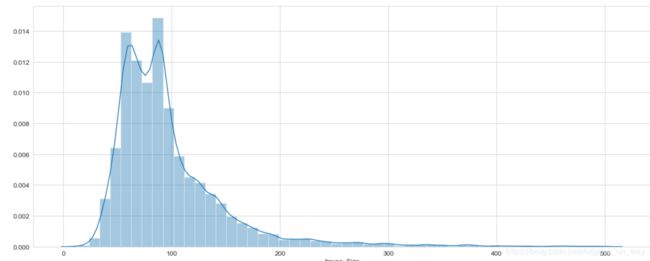
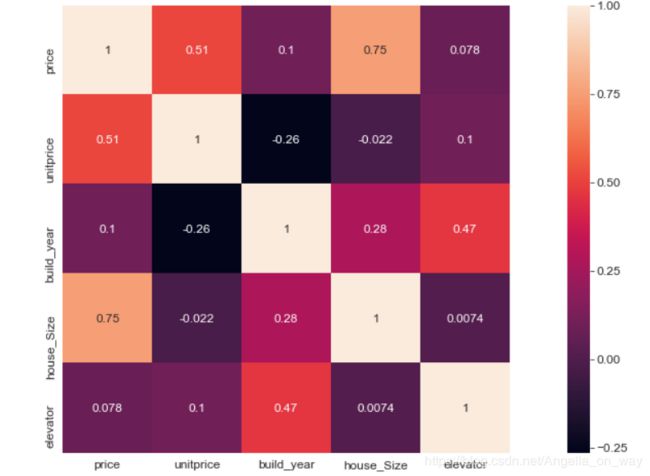
5.各个因素的相关性:
是否有电梯跟建造时间有关系,房屋单价和房屋总价之间有关系
#相关矩阵
df.house_Size=list(data_4)
df.build_year=data_3.year
df.head()
data_5=df.corr()
sns.heatmap(data_5,annot=True,vmax=1, square=True)
-