从零开始prometheus
第一部分:先上一波实战,用prometheus-oprator监控你的k8s集群
一:为什么需要prometheus-operator
在Kubernetes中我们使用Deployment、DamenSet、StatefulSet来管理应用Workload,使用Service、Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
而除了这些原生的Resource资源以外,Kubernetes还允许用户添加自己的自定义资源(Custom Resource)。并且通过实现自定义Controller来实现对Kubernetes的扩展,不需要用户去二开k8s也能达到给k8s添加功能和对象。
Prometheus-operator的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator这个controller有BRAC权限下去负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。
二:Prometheus-oprator的工作架构:

三:Prometheus Operator引入的自定义资源包括
- Prometheus
- ServiceMonitor
- Alertmanager
四:部署Prometheus Operator:
git clone https://github.com/coreos/prometheus-operator.git
cd prometheus-operator/contrib/
rm -rf kube-prometheus/
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus/manifests
#####分批处理一下方便管理:
mkdir -p operator node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter
mv *-serviceMonitor* serviceMonitor/
mv 0prometheus-operator* operator/
mv grafana-* grafana/
mv kube-state-metrics-* kube-state-metrics/
mv alertmanager-* alertmanager/
mv node-exporter-* node-exporter/
mv prometheus-adapter* adapter/
mv prometheus-* prometheus/
######开始部署:
pro1k8s apply -f bundle.yaml
######
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
五:里面的坑:
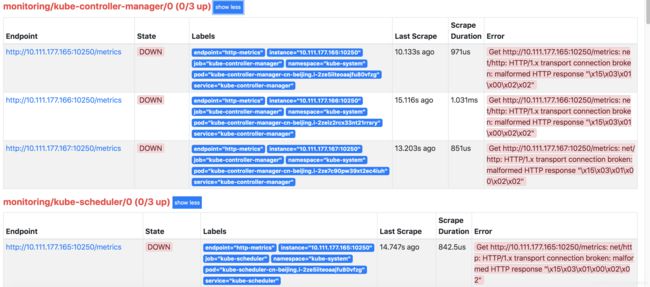
打开页面发现:

这是因为serviceMonitor是根据label去选取svc的,我们可以看到对应的serviceMonitor是选取的ns范围是kube-system,然而里面没有这两个组件对应的service,不知道k8s搞什么鬼。
创建一个service即可:
cat 01kube-prom-service.yml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10250
targetPort: 10250
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10250
targetPort: 10250
protocol: TCP
然而:
cat /etc/kubernetes/manifests/kube-scheduler.yaml|grep address
- --address=127.0.0.1
cat /etc/kubernetes/manifests/kube-controller-manager.yaml|grep address
- --address=127.0.0.1
sed -ri '/--address/s#=.+#=0.0.0.0#' /etc/kubernetes/manifests/kube-controller-manager.yaml
sed -ri '/--address/s#=.+#=0.0.0.0#' /etc/kubernetes/manifests/kube-scheduler.yaml

第二部分:prometheus详解:
一:什么是TSDB?
时间序列数据库的特点
- 大部分时间都是写入操作。
- 写入操作几乎是顺序添加,大多数时候数据到达后都以时间排序。
- 写操作很少写入很久之前的数据,也很少更新数据。大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库。
- 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据。
- 基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用。
- 读操作是十分典型的升序或者降序的顺序读。
- 高并发的读操作十分常见。
二:什么是Prometheus?
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
三:Prometheus都有哪些组件?
- Prometheus Server:主要负责数据采集和存储,提供PromQL查询语言的支持。
- 客户端SDK:官方提供的客户端类库有go、java、scala、python、ruby,其他还有很多第三方开发的类库,支持nodejs、php、erlang等。
- Push Gateway:支持临时性Job主动推送指标的中间网关。
- PromDash:使用Rails开发可视化的Dashboard,用于可视化指标数据。
- Exporter:Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。
Prometheus提供多种类型的Exporter用于采集各种不同服务的运行状态。目前支持的有数据库、硬件、消息中间件、存储系统、HTTP服务器、JMX等。
- alertmanager:警告管理器,用来进行报警。
- 其他辅助性工具: promtool
四:prometheus的架构:

五:prometheus的基本原理:
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。mysql、kafka、redis、等许多组件都有exporter
六:Prometheus工作过程:
- Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
- Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
- PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
第三部分:prometheus的分布式思路详解:
一:prometheus-server的分布式思路:
- 只需要部署多套Prometheus,采集相同的Targets即可实现基本的HA:下面的prometheus写相同的targets

- server的数据支持写入其他分布式的时序数据库:remote_storage_adapter,
./remote_storage_adapter -influxdb-url=http://localhost:8086/ -influxdb.database=prometheus -influxdb.retention-policy=autoge
prometheus的配置文件:
remote_write:
- url: "http://localhost:9201/write"
remote_read:
- url: "http://localhost:9201/read"
- prometheus本身的联邦机制:不同的prometheus可以通过联邦机制实现数据聚合:
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true ##(to not overwrite any labels exposed by the source server)
metrics_path: '/federate'
params:
'match[]':
- '{job=~"kubernetes.*"}'
- '{__name__=~"job:.*"}'
#- '{job="mysql"}'
#- '{job="pgsql"}'
static_configs:
- targets:
- '10.111.178.30:30373'

可以解决什么问题呢?
- 单数据中心 + 大量的采集任务,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
- 多数据中心,当Promthues Server无法直接与数据中心中的Exporter进行通讯时,在每一个数据中部署一个单独的Promthues Server负责当前数据中心的采集任务是一个不错的方式。这样可以避免用户进行大量的网络配置,只需要确保主Promthues Server实例能够与当前数据中心的Prometheus Server通讯即可。 中心Promthues Server负责实现对多数据中心数据的聚合。
二:alertmanager的分布式思路:
- 因为是分开的,多个server可以公用一个alertmanager
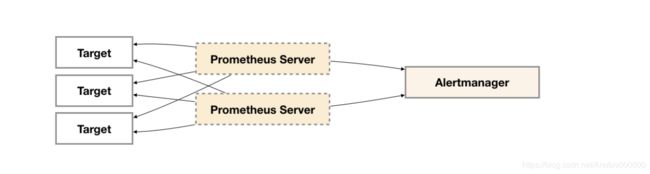

- 虽然Alertmanager能够同时处理多个相同的Prometheus Server所产生的告警。但是由于单个Alertmanager的存在,当前的部署结构存在明显的单点故障风险,当Alertmanager单点失效后,告警的后续所有业务全部失效。

but,但是由于Alertmanager之间不存在并不了解彼此的存在,因此则会出现告警通知被不同的Alertmanager重复发送多次的问题。
- 为了解决这一问题,如下所示。Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。

- Gossip 协议:

Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP系统,即可用性和分区容错性。同时对于Prometheus Server而言保持了配置了简单性,Promthues Server之间不需要任何的状态同步。
nohup ./alertmanager --web.listen-address=":9093" --cluster.listen-address="127.0.0.1:8001" --config.file="alertmanager.yml" 2>&1 > alert1.log &
nohup ./alertmanager --web.listen-address=":9094" --cluster.listen-address="127.0.0.1:8002" --cluster.peer=127.0.0.1:8001 --config.file="alertmanager.yml" 2>&1 > alert2.log &
nohup ./alertmanager --web.listen-address=":9095" --cluster.listen-address="127.0.0.1:8003" --cluster.peer=127.0.0.1:8001 --config.file="alertmanager.yml" 2>&1 > alert3.log &
模拟代码测试:
alerts1='[
{
"labels": {
"alertname": "DiskRunningFull",
"dev": "sda1",
"instance": "example1"
},
"annotations": {
"info": "The disk sda1 is running full",
"summary": "please check the instance example1"
}
}
]'
curl -XPOST -d"$alerts1" http://localhost:9093/api/v1/alerts
curl -XPOST -d"$alerts1" http://localhost:9094/api/v1/alerts
curl -XPOST -d"$alerts1" http://localhost:9095/api/v1/alerts
所以这套可以作为prometheus-server的通用报警集群,每套server里面添加配置保证像每个alertmanager都发送报警消息即可:
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
- targets: ["localhost:9094"]
- targets: ["localhost:9095"]
执行脚本sh sent_alert.sh
{"status":"success"}{"status":"success"}{"status":"success"}
查看钉钉消息只收到一条:

第四部分:promsql详解:
一:数据库格式:
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
http_request_total{status="200", method="GET"}@1434417561287 => 94334
http_request_total{status="404", method="GET"}@1434417560938 => 38473
http_request_total{status="404", method="GET"}@1434417561287 => 38544
http_request_total{status="200", method="POST"}@1434417560938 => 4748
http_request_total{status="200", method="POST"}@1434417561287 => 4785
二:什么是metrics:

| grpc_cache_total{app="smpre-svc-ads-go",enable="true",instance="172.24.4.172:2112",job="kubernetes-pods",kubernetes_namespace="staging",kubernetes_pod_name="smpro-svc-ads-go-58d6d44cb5-xthqz",pod_template_hash="1482800761",rpc="Execute",service="svc-rule",status="hit",version="pre"} | 327 |
- 为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4中不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。直接curl能看到每个metrics的type,如下所示
# HELP mysql_up Whether the MySQL server is up.
# TYPE mysql_up gauge
mysql_up 1
# HELP mysql_version_info MySQL version and distribution.
# TYPE mysql_version_info gauge
mysql_version_info{innodb_version="5.7.25",version="5.7.25-log",version_comment="Source distribution"} 1
# HELP mysqld_exporter_build_info A metric with a constant '1' value labeled by version, revision, branch, and goversion from which mysqld_exporter was built.
# TYPE mysqld_exporter_build_info gauge
mysqld_exporter_build_info{branch="HEAD",goversion="go1.10.3",revision="5d7179615695a61ecc3b5bf90a2a7c76a9592cdd",version="0.11.0"} 1
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 2871.09
- Counter:只增不减的计数器:

五分钟的增长率:rate(http_requests_total[5m])

前五的请求:topk(5, http_requests_total)

- Gauge:可增可减的仪表盘
mysql_global_status_memory_used

对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况:
delta(mysql_global_status_memory_used{instance="pro-ab-test"}[1h])

还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测:
predict_linear(mysql_global_status_memory_used{instance="pro-ab-test"}[1h], 4 * 3600)

- Histogram &Summary
例如nginx_ingress_controller_ingress_upstream_latency_seconds这个metric为Summary:

其中0.5比例、0.9比例和0.99比例的延时秒分别为0.001 、0.001和 0.002
grpc_server_handling_seconds_bucket这个参数是咱们线上的一个histogram类型数据
histogram_quantile(0.90, sum(rate(grpc_server_handling_seconds_bucket{grpc_service="shimo.svc.comment.CommentService"}[1m])) by (grpc_method,le))

线上某时段的90请求的平均延时

与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择。
三:promsql:
- 直接输入metric的值:
promhttp_metric_handler_requests_total

{}里面的参数都可以用来过滤查询支持=、!=、正则
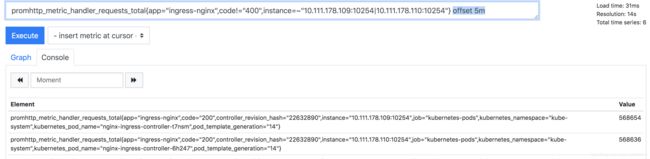
promhttp_metric_handler_requests_total{app="ingress-nginx",code!="400",instance=~"10.111.178.109:10254|10.111.178.110:10254"}

加入一个5m就能查到最近五分钟内的所有数值:

加offset 5m 可以查五分钟前的瞬时样本:
那么我想求上一个五分的所有数值怎么办:
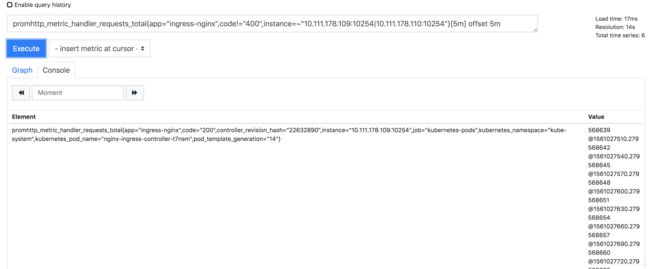
总结:offset函数是一个相对的时间函数,可以用来时间位移
- 使用聚合操作:
sum:

avg:

increase:函数获取区间向量中的第一个后最后一个样本并返回其增长量

rate:rate函数可以直接计算区间向量v在时间窗口内平均增长速率。因此,通过以下表达式可以得到与increase函数相同的结果:

需要注意的是使用rate或者increase函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。 例如,对于主机而言在2分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致CPU占用100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL提供了另外一个灵敏度更高的函数irate(v range-vector)。irate同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。irate函数是通过区间向量中最后两个两本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
举个例子:我们查最近十分钟的cpu利用率sum(irate(process_cpu_seconds_total[10m])) * 100 这个是最好的因为能够比较清晰的反映出十分钟内cpu利用率的变化
但是我们要查大约一个月的cpu利用率,用这个比较好
sum(rate(process_cpu_seconds_total[10m])) * 100
类似的可以直接使用sum,min,max,avg,stddev,stdvar,count,count_values,bottomk,topk,quantile
第五部分:alertmanager详解:
一:alertmanager特点:
- 分组,太多的报警信息来到时,可以分组发送
- 抑制,如果一个报警规则触发以后,后面相同的触发就会被抑制
- 静音,直接将个别报警进行屏蔽
- 高可用,可以组成Alertmanager集群
二:Prometheus对接
Prometheus需要加入两个配置项
- 配置文件引入Alertmanager实例
- 定义出报警规则alerting rules
alerting:
alertmanagers:
#一组配置项目就是一个列表
- scheme: https
static_configs:
- targets:
- "1.2.3.4:9093"
- "1.2.3.5:9093"
- "1.2.3.6:9093"
- scheme: http
static_configs:
- targets:
- "1.2.3.7:9093"
- "1.2.3.8:9093"
- "1.2.3.9:9093"
或者k8s自动发现:
alerting:
alertmanagers:
- kubernetes_sd_configs:
- role: pod
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: default
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
regex: prometheus
action: keep
- source_labels: [__meta_kubernetes_pod_label_component]
regex: alertmanager
action: keep
- source_labels: [__meta_kubernetes_pod_container_port_number]
regex:
action: drop
三:引入报警规则
rule_files:
- "/etc/prometheus_rule/rule_*.yml"
具体规则如下:
# 定义alert类型并加上名称
alert:
# PromQL 表达式
#expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
expr:
# 报警间隔,含义就是 当一个报警信息触发以后延迟多少时间再去fire
[ for: | default = 0s ]
# 报警标签
labels:
[ : ]
# 报警中的注释
annotations:
[ : ]
#建议写上summary describipton
#summary: "High request latency on {{ $labels.instance }}"
#description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
#####label和annotations的值是以模板console templates来渲染的,用到go模板语言,报警注释和标签中常用的是变量$labels和$value,分别表示一个监控实例和expr字段上表达式所拉取的值
项目地址:https://git.shimo.im/shimo/prometheus_rule/tree/master
四:route
route定义了报警信息的分发策略,receivers定义了发送媒介,两者合在一起就是什么样的报警信息以什么样的形式发送。主要流程
- 报警信息从Prometheus过来后就依据label(在Prometheus中alerting rules来定义)来分配属于哪一个route中的哪一个group中的哪一个alert
- 新的Group等待group_wait指定的时间(等待时可能收到同一Group的Alert),根据resolve_timeout判断Alert是否解决,然后发送通知
- 已有的Group等待group_interval指定的时间,判断Alert是否解决,当上次发送通知到现在的间隔大于repeat_interval或者Group有更新时会发送通知
总路由:
#总路由,下面的配置都是各个子路由所继承的配置,如果子路由中没有配置就是使用总路由的配置,子路由中可以覆盖总路由的配置
route:
#定义全路由默认的接受者
receiver: 'default-receiver'
#报警是否需要继续向兄弟(同级)节点匹配
[ continue: | default = false ]
#等待还有可能到达的同组报警信息,初次发送一条警报包含多个信息
[ group_wait: | default = 30s ]
#已经存在的group等待group_interval这个时间段看报警问题是否解决
[ group_interval: | default = 5m ]
#当上次发送完报警信息之后再次发送的间隔,用来重复发送报警信息
[ repeat_interval: | default = 4h ]
#根据不同的标签来分组,这个主要用来筛选报警信息
group_by: [cluster, alertname]
#使用标签值精确匹配
match:
[ : , ... ]
#使用正则表达进行范围匹配
match_re:
[ : , ... ]
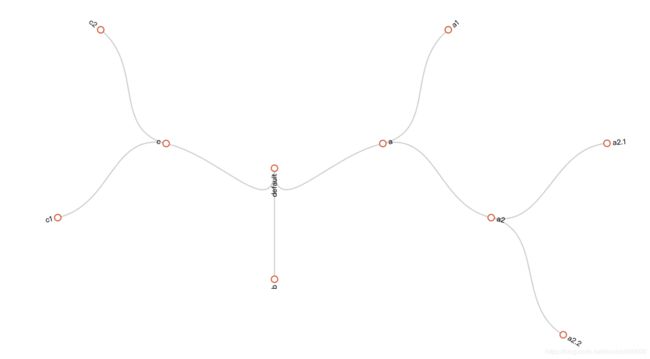
子路由构成的路由树:
route:
receiver: default
routes:
- match:
service: database
receiver: a
routes:
- match:
owner: team-X
receiver: a1
- match:
owner: team-Y
receiver: a2
routes:
- match:
owner: ll
receiver: a2.1
- match:
owner: rr
receiver: a2.2
- match:
receiver: b
- match:
receiver: c
routes:
- match:
receiver: c1
- match:
receiver: c2
五:报警抑制:
拿线上举个例子:
groups:
- name: dingtalk
rules:
- alert: dingtalk api 调用过多
expr: sum(irate(dingtalk_api_call{}[1m])) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "钉钉 API 调用过多, 当前 {{ $value }} qps"
如果定义超过100 级别为critical 也发出告警:
groups:
- name: dingtalk
rules:
- alert: dingtalk api 调用过多
expr: sum(irate(dingtalk_api_call{}[1m])) > 60
for: 1m
labels:
severity: critical
annotations:
summary: "钉钉 API 调用过多, 当前 {{ $value }} qps"
可以设定抑制规则:
inhibit_rules:
- source_match:
altername: 'dingtalk api 调用过多'
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
equal: ['alertname', 'instance']
六:支持的发送方式:
这个不展开说了,咱们内部用钉钉,可以直接发到群里 prometheus机器里面:
./prometheus-webhook-dingtalk --web.listen-address=:8060 --ding.profile=ops_dingding=https://oapi.dingtalk.com/robot/send?access_token=xxxxxxx
第六部分:pushgateway
一:安装:
docker pull prom/pushgateway
docker run ‐d ‐p 9091:9091 prom/pushgateway
二:简单使用:
echo "some_metric 3.14" | curl ‐‐data‐binary @‐ http://127.0.0.1:9091/metrics/job/some_job

因为 Prometheus 配置 pushgateway 的时候,也会指定 job 和 instance, 但是它只表示 pushgateway 实例,不能真正表达收集数据的含义。所以在prometheus 中配置 pushgateway 的时候,需要添加 honor_labels: true 参数,从而避免收集数据本身的 job 和 instance 被覆盖。
三:持久化
注意,为了防止 pushgateway 重启或意外挂掉,导致数据丢失,我们可以通过 -persistence.file 和 -persistence.interval 参数将数据持久化下来。
四:注意事项:
由于以上原因,不得不使用 pushgateway,但在使用之前,有必要了解一下它的一些弊端:
- 将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。
- Prometheus 拉取状态 up 只针对 pushgateway, 无法做到对每个节点有效。
- Pushgateway 可以持久化推送给它的所有监控数据。
因此,即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。