系统学习机器学习之总结(三)--多标签分类问题
前沿
本篇记录一下自己项目中用到的keras相关的部分。由于本项目既有涉及multi-class(多类分类),也有涉及multi-label(多标记分类)的部分,multi-class分类网上已经很多相关的文章了。这里就说一说multi-label的搭建网络的部分。之后如果有时间的时候,再说一说cross validation(交叉验证)和在epoch的callback函数中处理一些多标签度量metric的问题。
multi-label多标记监督学习
其实我个人比较喜欢把label翻译为标签。那可能学术上翻译multi-label多翻译为多标记。其实和多标签一个意思。
multi-class 和 multi-label的区别
multi-class是相对于binary二分类来说的,意思是需要分类的东西不止有两个类别,可能是3个类别取一个(如iris分类),或者是10个类别取一个(如手写数字识别mnist)。
而multi-label是更加general的一种情况了,它说为什么一个sample的标签只能有1个呢。为什么一张图片不是猫就是狗呢?难道我不能训练一个人工智能,它能告诉我这张图片既有猫又有狗呢?
其实关于多标签学习的研究,已经有很多成果了。
主要解法是
* 不扩展基础分类器的本来算法,只通过转换原始问题来解决多标签问题。如BR, LP等。
* 扩展基础分类器的本来算法来适配多标签问题。如ML-kNN, BP-MLL等。
这里不展开了。有兴趣的同学可以自己去研究一下。
keras的multi-label
废话不多说,直接上代码。这里假设大家是有keras的基础知识的,所以关键代码之外的代码请大家自行脑补。
-
def __create_model(self):
-
from keras.models
import Sequential
-
from keras.layers
import Dense
-
model = Sequential()
-
print(
“create model. feature_dim = %s, label_dim = %s” % (self.feature_dim, self.label_dim))
-
model.add(Dense(
500, activation=
‘relu’, input_dim=self.feature_dim))
-
model.add(Dense(
100, activation=
‘relu’))
-
model.add(Dense(self.label_dim, activation=
‘sigmoid’))
-
model.compile(optimizer=
‘adam’, loss=
‘binary_crossentropy’, metrics=[
‘accuracy’])
-
return model
稍微解说一下:
* 整个网络是fully connected全连接网络。
* 网络结构是输入层=你的特征的维度
* 隐藏层是500100,激励函数都是relu。隐藏层的节点数量和深度请根据自己的数量来自行调整,这里只是举例。
输出层是你的label的维度。使用sigmoid作为激励,使输出值介于0-1之间。
* 训练数据的label请用0和1的向量来表示。0代表这条数据没有这个位的label,1代表这条数据有这个位的label。假设3个label的向量[天空,人,大海]的向量值是[1,1,0]的编码的意思是这张图片有天空,有人,但是没有大海。
* 使用binary_crossentropy来进行损失函数的评价,从而在训练过程中不断降低交叉商。实际变相的使1的label的节点的输出值更靠近1,0的label的节点的输出值更靠近0。
结语
有了这个结构,就可以run起来一个multi label的神经网络了。这个只是基础中的基础,关于multi-label的度量代码才是我们研究一个机器学习问题的核心。
4、解决多标签分类问题(包括案例研究)
由于某些原因,回归和分类问题总会引起机器学习领域的大部分关注。多标签分类在数据科学中是一个比较令人头疼的问题。在这篇文章中,我将给你一个直观的解释,说明什么是多标签分类,以及如何解决这个问题。
1.多标签分类是什么?
让我们来看看下面的图片。

如果我问你这幅图中有一栋房子,你会怎样回答? 选项为“Yes”或“No”。
或者这样问,所有的东西(或标签)与这幅图有什么关系?

在这些类型的问题中,我们有一组目标变量,被称为多标签分类问题。那么,这两种情况有什么不同吗? 很明显,有很大的不同,因为在第二种情况下,任何图像都可能包含不同图像的多个不同的标签。
但在深入讲解多标签之前,我想解释一下它与多分类问题有何不同,让我们试着去理解这两组问题的不同之处。
2.多标签vs多分类
用一个例子来理解这两者之间的区别。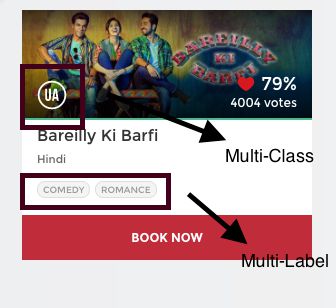
对于任何一部电影,电影的中央委员会会根据电影的内容颁发证书。例如,如果你看上面的图片,这部电影被评为“UA”(意思是“12岁以下儿童需在父母陪同下观看”)。还有其他类型的证书类,如“A”(仅限于成人)或“U”(不受限制的公开放映),但可以肯定的是,每部电影只能在这三种类型的证书中进行分类。简而言之,有多个类别,但每个实例只分配一个,因此这些问题被称为多类分类问题。
同时,你回顾一下这张图片,这部电影被归类为喜剧和浪漫类型。但不同的是,这一次,每部电影都有可能被分成一个或多个不同的类别。
所以每个实例都可以使用多个类别进行分配。因此,这些类型的问题被称为多标签分类问题。
现在你应该可以区分多标签和多分类问题了。那么,让我们开始处理多标签这种类型的问题。
3.加载和生成多标签数据集
Scikit-learn提供了一个独立的库scikit-multilearn,用于多种标签分类。为了更好的理解,让我们开始在一个多标签的数据集上进行练习。scikit-multilearn库地址:http://scikit.ml/api/datasets.html
你可以从MULAN package提供的存储库中找到实际的数据集。这些数据集以ARFF格式呈现。存储库地址:http://mulan.sourceforge.net/datasets-mlc.html
因此,为了开始使用这些数据集,请查看下面的Python代码,将其加载到你的计算机上。在这里,我已经从存储库中下载了酵母(yeast)数据集。
import scipy
from scipy.io import arff
data, meta = scipy.io.arff.loadarff(’/Users/shubhamjain/Documents/yeast/yeast-train.arff’)
df = pd.DataFrame(data)
这就是数据集的样子。
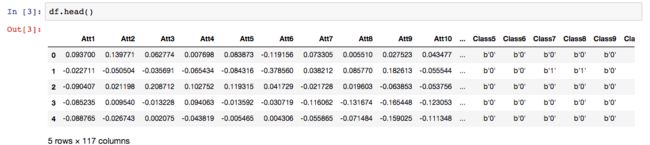
在这里,Att表示属性或独立变量,class表示目标变量。
出于实践目的,我们有另一个选项来生成一个人工的多标签数据集。
from sklearn.datasets import make_multilabel_classification
this will generate a random multi-label dataset
X, y = make_multilabel_classification(sparse = True, n_labels = 20,
return_indicator = ‘sparse’, allow_unlabeled = False)
让我们了解一下上面所使用的参数。
sparse(稀疏):如果是True,返回一个稀疏矩阵,稀疏矩阵表示一个有大量零元素的矩阵。
n_labels:每个实例的标签的平均数量。
return_indicator:“sparse”在稀疏的二进制指示器格式中返回Y。
allow_unlabeled:如果是True,有些实例可能不属于任何类。
你一定会注意到,我们到处都使用了稀疏矩阵,而scikit-multilearn也建议使用稀疏格式的数据,因为在实际数据集中非常罕见。一般来说,分配给每个实例的标签的数量要少得多。
好了,现在我们已经准备好了数据集,让我们快速学习解决多标签问题的技术。
4.解决多标签分类问题的技术
基本上,有三种方法来解决一个多标签分类问题,即:
- 问题转换
- 改编算法
- 集成方法
4.1问题转换
在这个方法中,我们将尝试把多标签问题转换为单标签问题。这种方法可以用三种不同的方式进行:
- 二元关联(Binary Relevance)
- 分类器链(Classifier Chains)
- 标签Powerset(Label Powerset)
4.4.1二元关联(Binary Relevance)
这是最简单的技术,它基本上把每个标签当作单独的一个类分类问题。例如,让我们考虑如下所示的一个案例。我们有这样的数据集,X是独立的特征,Y是目标变量。
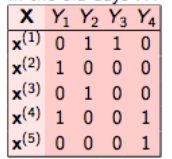
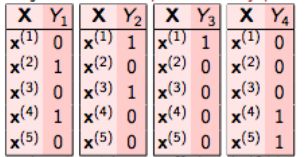
在二元关联中,这个问题被分解成4个不同的类分类问题,如下图所示。
我们不需要手动操作,multi-learn库在python中提供了它的实现。那么,让我们看看它在随机生成的数据上的实现。
# using binary relevance
from skmultilearn.problem_transform import BinaryRelevance
from sklearn.naive_bayes import GaussianNB
initialize binary relevance multi-label classifier
with a gaussian naive bayes base classifier
classifier = BinaryRelevance(GaussianNB())
train
classifier.fit(X_train, y_train)
predict
predictions = classifier.predict(X_test)
注意:在这里,我们使用了Naive Bayes的算法,你也可以使用任何其他的分类算法。
现在,在一个多标签分类问题中,我们不能简单地用我们的标准来计算我们的预测的准确性。所以,我们将使用accuracy score。这个函数计算子集的精度,这意味着预测的标签集应该与真正的标签集完全匹配。
那么,让我们计算一下预测的准确性。
from sklearn.metrics import accuracy_score
accuracy_score(y_test,predictions)
0.45454545454545453
我们的准确率达到了45%,还不算太糟。它是最简单和有效的方法,但是这种方法的惟一缺点是它不考虑标签的相关性,因为它单独处理每个目标变量。
4.1.2分类器链(Classifier Chains)
在这种情况下,第一个分类器只在输入数据上进行训练,然后每个分类器都在输入空间和链上的所有之前的分类器上进行训练。
让我们试着通过一个例子来理解这个问题。在下面给出的数据集里,我们将X作为输入空间,而Y作为标签。
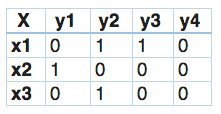
在分类器链中,这个问题将被转换成4个不同的标签问题,就像下面所示。黄色部分是输入空间,白色部分代表目标变量。

这与二元关联非常相似,唯一的区别在于它是为了保持标签相关性而形成的。那么,让我们尝试使用multi-learn库来实现它。
# using classifier chains
from skmultilearn.problem_transform import ClassifierChain
from sklearn.naive_bayes import GaussianNB
initialize classifier chains multi-label classifier
with a gaussian naive bayes base classifier
classifier = ClassifierChain(GaussianNB())
train
classifier.fit(X_train, y_train)
predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
0.21212121212121213
我们可以看到,使用这个我们得到了21%的准确率,这比二元关联要低得多。可能是因为没有标签相关性,因为我们已经随机生成了数据。
4.1.3标签Powerset(Label Powerset)
在这方面,我们将问题转化为一个多类问题,一个多类分类器在训练数据中发现的所有唯一的标签组合上被训练。让我们通过一个例子来理解它。
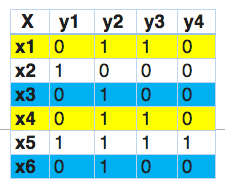
在这一点上,我们发现x1和x4有相同的标签。同样的,x3和x6有相同的标签。因此,标签powerset将这个问题转换为一个单一的多类问题,如下所示。
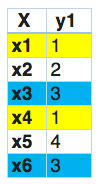
因此,标签powerset给训练集中的每一个可能的标签组合提供了一个独特的类。让我们看看它在Python中的实现。
# using Label Powerset
from skmultilearn.problem_transform import LabelPowerset
from sklearn.naive_bayes import GaussianNB
initialize Label Powerset multi-label classifier
with a gaussian naive bayes base classifier
classifier = LabelPowerset(GaussianNB())
train
classifier.fit(X_train, y_train)
predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
0.5757575757575758
这使我们在之前讨论过的三个问题中得到了最高的准确性,57%。唯一的缺点是随着训练数据的增加,类的数量也会增加。因此,增加了模型的复杂性,并降低了精确度。
现在,让我们看一下解决多标签分类问题的第二种方法。
4.2改编算法
改编算法来直接执行多标签分类,而不是将问题转化为不同的问题子集。例如,kNN的多标签版本是由MLkNN表示的。那么,让我们快速地在我们的随机生成的数据集上实现这个。
from skmultilearn.adapt import MLkNN
classifier = MLkNN(k=20)
train
classifier.fit(X_train, y_train)
predict
predictions = classifier.predict(X_test)
accuracy_score(y_test,predictions)
0.69
很好,你的测试数据已经达到了69%的准确率。
在一些算法中,例如随机森林(Random Forest)和岭回归(Ridge regression),Sci-kit learn提供了多标签分类的内置支持。因此,你可以直接调用它们并预测输出。
如果你想了解更多关于其他类型的改编算法,你可以查看multi-learn库。地址:http://scikit.ml/api/api/skmultilearn.adapt.html#module-skmultilearn.adapt
4.3集成方法
集成总是能产生更好的效果。Scikit-Multilearn库提供不同的组合分类功能,你可以使用它来获得更好的结果。
对于直接实现,你可以查看:http://scikit.ml/api/classify.html#ensemble-approaches
5.案例研究
在现实世界中,多标签分类问题非常普遍。所以,来看看我们能在哪些领域找到它们。
5.1音频分类
我们知道歌曲会被分类为不同的流派。他们也被分类为,如“放松的平静”,或“悲伤的孤独”等等情感或情绪的基础。
来源:http://lpis.csd.auth.gr/publications/tsoumakas-ismir08.pdf
5.2图像分类
使用图像的多标签分类也有广泛的应用。图像可以被标记为不同的对象、人或概念。

5.3生物信息学
多标签分类在生物信息学领域有很多用途,例如,在酵母数据集中的基因分类。它还被用来使用几个未标记的蛋白质来预测蛋白质的多重功能。
5.4文本分类
谷歌新闻所做的是,将每条新闻都标记为一个或多个类别,这样它就会显示在不同的类别之下。
例如,看看下面的图片。
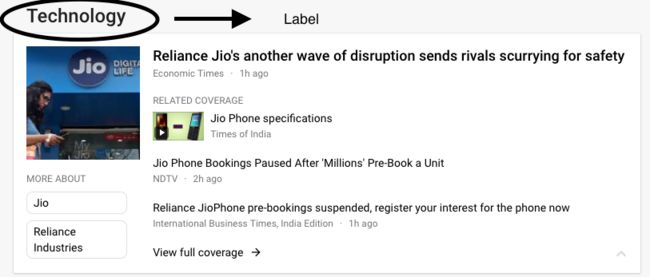
图片来源:https://news.google.com/news/headlines/section/topic/TECHNOLOGY.en_in/Technology?ned=in&hl=en-IN
同样的新闻出现在“Technology”,“Latest” 等类别中,因为它已经被分类为不同的标签。从而使其成为一个多标签分类问题。
多标记分类和传统的分类问题相比较,主要难点在于以下两个方面:
(1)类标数量不确定,有些样本可能只有一个类标,有些样本的类标可能高达几十甚至上百个。
(2)类标之间相互依赖,例如包含蓝天类标的样本很大概率上包含白云,如何解决类标之间的依赖性问题也是一大难点。
对于多标记学习领域的研究,国外起步较早,起源于2000年Schapire R E等人提出的基于boost方法的文本多分类,著名的学者有G Tsoumakas、Eyke Hüllermeier、Jesse Read,Saso Dzeroski等等。在国内,南京大学的周志华和张敏灵和哈工大的叶允明等等学者在这一领域较都有很好研究成果。
目前有很多关于多标签的学习算法,依据解决问题的角度,这些算法可以分为两大类:一是基于问题转化(Problem Transformation)的方法,二是基于算法适应的方法和算法适应方法(Algorithm Adaptation)。基于问题转化的多标记分类是转化问题数据,使之适用现有算法;基于算法适应的方法是指针对某一特定的算法进行扩展,从而能够直接处理多标记数据,改进算法,适应数据。基于这两种思想,目前已经有多种相对成熟的算法被提出,如下图所示:
问题转化方法(Problem Transformation):该类方法的基本思想是通过对多标记训练样本进行处理,将多标记学习问题转换为其它已知的学习问题进行求解。代表性学习算法LP[[1]],Binary Relevance[[2]],Calibrated Label Ranking[[3]], Random k-labelsets[[4]]。总体来说,这类方法有考虑类标之间的联系,但是对于类标较多、数据量较大的数据集,这类方法的计算复杂度是一个很明显的缺陷。
算法适应方法与问题转化方法不同,问题转化方法是将多标记问题转化成一个或者多个单类标问题,算法适应方法是在多标记的基础上研究算法。近年来,用于多标记的算法适应的算法越来越多,代表性学习算法ML-kNN[[5]],Rank-SVM[[6]],LEAD[[7]],CML。
对于分类策略,基于考察标记之间相关性的不同方式,已有的多标记学习算法的策略思路大致可以分为以下三类[[8]]:
a) “一阶(first-order)”策略:该类策略通过逐一考察单个标记而忽略标记之间的相关性,如将多标记学习问题分解为个独立的二类分类问题,从而构造多标记学习系统。该类方法效率较高且实现简单,但由于其完全忽略标记之间可能存在的相关性,其系统的泛化性能往往较低。
b) “二阶(second-order)”策略:该类策略通过考察两两标记之间的相关性,如相关标记与无关标记之间的排序关系,两两标记之间的交互关系等等,从而构造多标记学习系统。该类方法由于在一定程度上考察了标记之间的相关性,因此其系统泛化性能较优。
c) “高阶(high-order)”策略:该类策略通过考察高阶的标记相关性,如处理任一标记对其它所有标记的影响,处理一组随机标记集合的相关性等等,从而构造多标记学习系统。该类方法虽然可以较好地反映真实世界问题的标记相关性,但其模型复杂度往往过高,难以处理大规模学习问题。
[[1]] Madjarov G, Kocev D, Gjorgjevikj D, et al. An extensive experimental comparison of methods for multi-label learning[J]. Pattern Recognition, 2012, 45(9): 3084-3104.
[[2]] Boutell M R, Luo J, Shen X, Brown C M. Learning multi-label scene classification. Pattern Recognition, 2004, 37(9): 1757-1771.
[[3]] Fürnkranz J, Hüllermeier E, Loza Mencía E, Brinker K. Multilabel classification via calibrated label ranking. Machine Learning, 2008, 73(2): 133-153.
[[4]] Tsoumakas G, Vlahavas I. Random k-labelsets: An ensemble method for multilabel classification. In: Kok J N, Koronacki J, de Mantaras R L, Matwin S, Mladenič D, Skowron A, eds. Lecture Notes in Artificial Intelligence 4701, Berlin: Springer, 2007, 406-417.
[[5]] Zhang M-L, Zhou Z-H. ML-kNN: A lazy learning approach to multi-label learning. Pattern Recognition, 2007, 40(7): 2038-2048.
[[6]] Elisseeff A, Weston J. A kernel method for multi-labelled classification. In: Dietterich T G, Becker S, Ghahramani Z, eds. Advances in Neural Information Processing Systems 14 (NIPS’01), Cambridge, MA: MIT Press, 2002, 681-687.
[[7]] Zhang M-L, Zhang K. Multi-label learning by exploiting label dependency. In: Pro ceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’10), Washington, D. C., 2010, 999-1007.
[[8]] Zhang M L, Zhang K. Multi-label learning by exploiting label dependency[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2010:999-1008.