【mysql题目】按各科成绩排序,并显示名次(同名次空缺vs合并)
按各科成绩排序,并显示名次(同名次空缺vs合并)
数据表
-- 学生表
Student(sid,sname,sage,ssex)
insert into Student values('01','张三','1991-11-11','男');
-- 课程表
Course(cid,cname,tid)
insert into Course values('01','语文','01');
-- 教师表
Teacher(tid,tname)
insert into Teacher values('01','小王');
-- 成绩表
SC(sid,cid,score)
insert into SC values('01','01',90);
数据在此就不提供了
回到原题,
1、 按各科成绩排序,并显示名次(同名次空缺)
这个还行,左联表,判断同科目的分数比其他同科目同学的高的有多少
简单的说,就是
a left join b on a.cid = b.cid and a.score < b.score
这样得到的结果表代表b表部分的就能显示出数量差距了
select *from sc a
left join sc b on a.cid = b.cid and a.score < b.score order by a.sid,a.cid

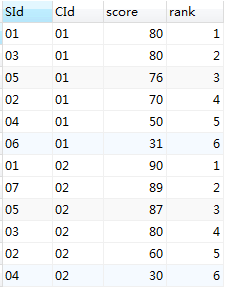
这里只是截取01,02号学生的成绩与其他同学比较,很明显,01号同学是学霸,3科成绩没人比他高的,02号同学01科目比他高的有3个(03、05、01),02科目比他高的有4个(05、07、03、01),03科目比他高的有2个(01、07)
接下来只需要进行统计排序就可以了,根据左联表同sid(同一个同学)、cid(同一科目)的条目进行统计(每一条代表)有一个人比他的该科目成绩高,
select a.*,count(a.score) rank from sc a
left join sc b on a.cid = b.cid and a.score < b.score
group by a.cid,a.sid
order by a.cid,rank
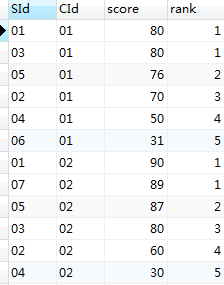
这样得到的结果会发现,并列名次后并没有空缺,因为左联得到的结果,如果只是单个排名第一,会得到一条右半数据为null的项。
所以,这并不符合我们题目要求,既然是因为多了一条null项,所以只需要选择统计的项是b表的就可以了
select a.*,count(b.score)+1 rank from sc a
left join sc b on a.cid = b.cid and a.score < b.score
group by a.cid,a.sid
order by a.cid,rank

名次空缺完成,接下来就是同名次不空缺的了。
2、 按各科成绩排序,并显示名次(同名次合并【按学号排序】)
开始我是按第一题的逻辑来做的,
先空缺排序、找到同名次项、更新排名,貌似咋看下应该也不难,所以:
- 空缺排序
select a.* ,count(b.score)+1 rank from sc a left join sc b
on a.cid = b.cid and a.score < b.score
group by a.cid,a.sid
order by a.cid,count(b.score)
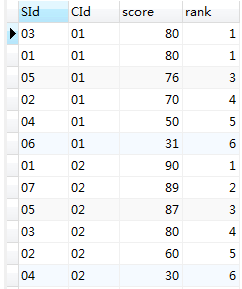
这一步没毛病,接着
- 找到同名次项
这一般情况得内连判断同科目同名次以及不同学号的人存在;
可是这又有一个问题要联表,那么得有个表,还不能是临时表(因为临时表不能在一个查询中重命名使用),好吧,那就将第一次排序查询的结果保留下来,刚好,更新排名还得用上,这里我认了
create table tpc as select * from(
select a.* ,count(b.score)+1 rank from sc a left join sc b
on a.cid = b.cid and a.score < b.score
group by a.cid,a.sid
order by a.cid,count(b.score)
) c;
-- 内连2种写法都可以
select a.* from tpc a,tpc b
where a.cid = b.cid
and a.score = b.score
and a.rank = b.rank
and a.sid <> b.sid;
select a.sid,a.cid,a.score,a.rank from tpc a
inner join tpc b
on a.cid = b.cid
and a.score = b.score
and a.rank = b.rank
and a.sid <> b.sid;
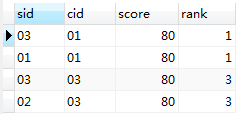
emmmm,既然都走到这了,就将就了,下一步
- 更新排名
更新排名,也就是要重新将查到的同名给再一次排名,也就是我要再一次左联同名次排序,???,什么鬼,我还得再将同名次的保存一个表?好吧,胜利在望,我忍了
create table tpd as
select a.* from tpc a,tpc b
where a.cid = b.cid
and a.score = b.score
and a.rank = b.rank
and a.sid <> b.sid;
update tpc a,
(
select a.sid,a.cid,a.score,count(b.sid)+1 rank from tpd a left join tpd b
on a.cid = b.cid and a.score = b.score and a.sid > b.sid
group by a.sid,a.cid
order by a.cid,count(b.sid)
) b
set a.rank = b.rank
where a.sid = b.sid and a.cid = b.cid and a.score = b.score;
到这里准备工作终于好了,内心是崩溃的 = =|||
终于,可以拿到结果了
select * from tpc order by cid,rank;
-- 删除临时表
drop table tpc;
drop table tpd;
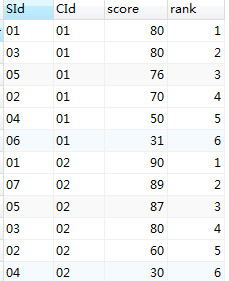
虽然路途曲折,不过结果总算是出来了。
回头看了下过程,这是什么鬼逻辑?突然灵光一闪
另一个解法
左联计算空缺时,只要判断比自己高的,如果同分数,再判断学号高低,这样就可以得到合适的项了
select a.* ,count(b.score)+1 rank from sc a left join sc b
on a.cid = b.cid and (a.score < b.score or (a.score = b.score and a.sid > b.sid))
group by a.cid,a.sid
order by a.cid,count(b.score)
啪啦啪啦敲完,看着结果,怀疑人生中TAT