爬取搜狗热搜榜数据制成南丁格尔图
【实验目的】
1.在Windows平台上使用基本的Python语言结合Scrapy将搜狗热搜榜上的九个热门类型的数据进行爬取,并将爬取数据保存到本地数据库;
2.使用eclipse编辑工具结合echarts和jQuery等组件将爬取到的数据以南丁格尔图的形式展现出来。
【实验原理】
1.Scrapy结合xpath和Css可以很方便快捷的从获取到的网页中找出所需标签的文本内容,同时可以为爬取到的数据建模,在存储数据的时候免去了对数据的繁琐处理;
2.Python结合Scrapy可以在短时间内快速的爬取多个网页的内容,通过对网页内容的分析处理找出所需的数据,同时Python通过pymysql可以直接操作MySQL数据库,这样就可以把网页上爬取到的想要的数据直接存储到数据库中。
【实验环境】
Windows10-64位操作系统
Python-3.6.1
Scrapy-1.3.3
Eclipse-Mars.1 Release (4.5.1)
Apache Tomcat v8.0
MySQL Ver 14.14 Distrib 5.5.37, for Win32 (x86)
Google Chrome
【实验内容】
搜狗热搜榜网页中有九个热门的类型,比如有热门电影、热门电视剧、热门游戏等,每个热门的类型都提供了十个热门数据,每个热门数据中都包含着数据的名字以及搜索指数,南丁格尔图可以直观的对每个热门类型的数据进行比较,将热搜榜的九个类型做成南丁格尔图显示出来。
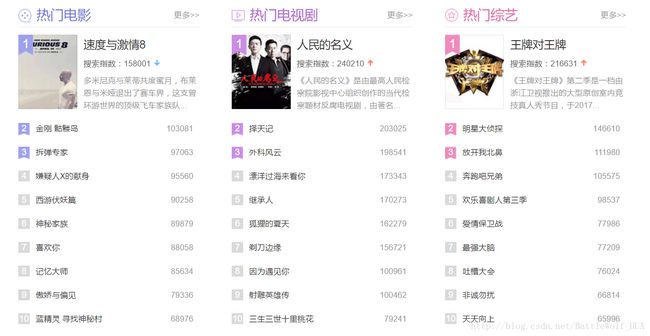
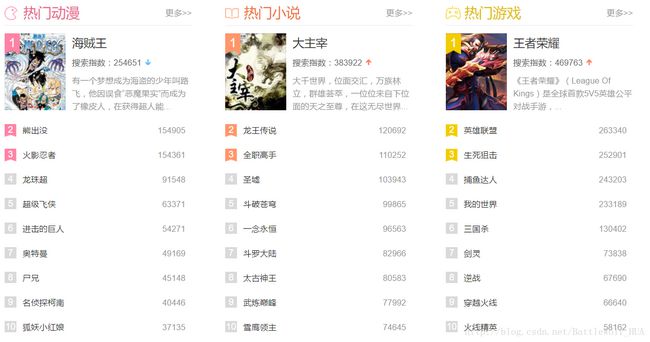
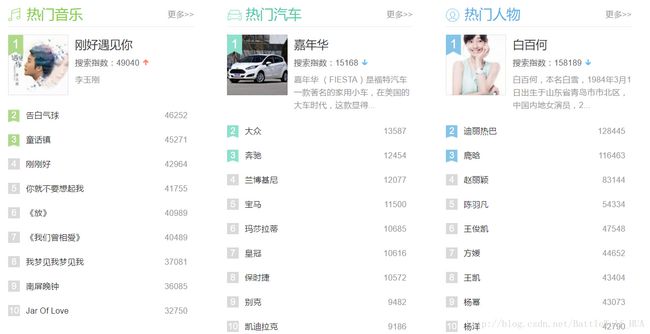

【实验步骤】
<一、安装Python3.6.1、Scrapy>
Windows:
1>从https://www.python.org/downloads/上安装Python3.6.1

2>下载后的安装文件

3>双击进行安装:
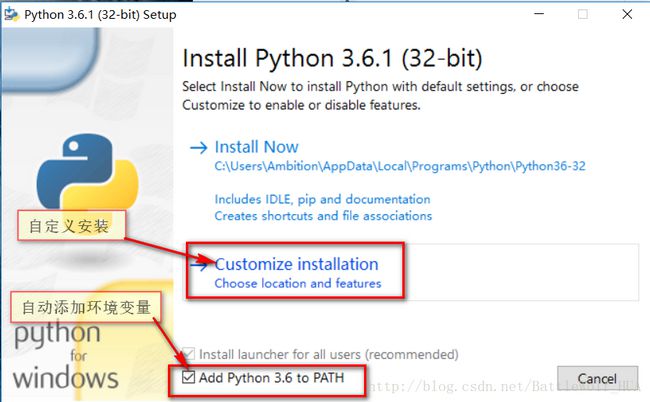
4>点击下一步
5>下一步
6>安装完成后退出。打开DOS命令行,查询Python版本
python --version7>从https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/下载安装pywin32
请确认下载符合系统的pywin32版本(win32或者amd64)
8>双击进行安装即可。安装完成后,打开DOS命令行进行安装Scrapy
pip install Scrapy9>安装完成后,输入命令查看Scrapy版本:
Scrapy -V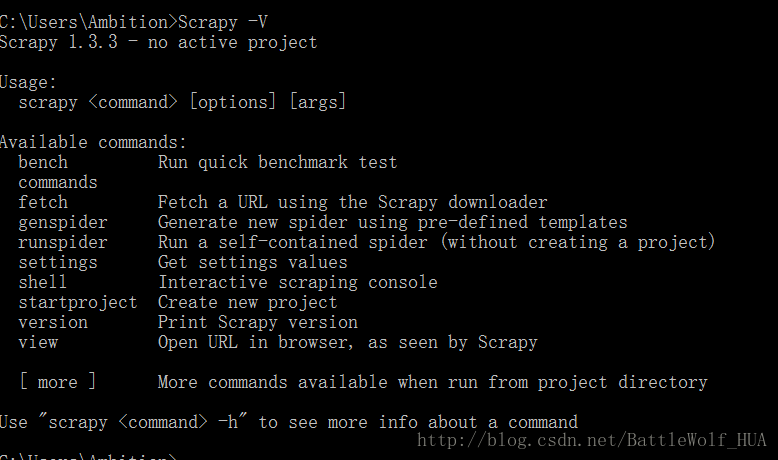
< 二、使用Scrapy 进行数据的爬取>
1.打开DOS命令行,进入桌面:
cd Desktop2.使用Scrapy创建爬虫项目,名字为resou:
scrapy startproject resou3.resou文件夹->resou文件夹->spider文件夹,手动创建一个Python文件,名字为resou.py(创建一个文本文档,更改名字和后缀为:resou.py)

4.右键点击resou.py文件,用IDLE编写Python文件
5>编辑爬取数据的代码:
#导入Scrapy包和pymysql包
import scrapy
import pymysql
#pymysql包是Python连接MySQL数据库所需要的包
#创建ReSouSpider类,继承scrapy.Spider类
class ReSouSpider(scrapy.Spider):
#为爬虫定义一个名字(这个名字必须是独一无二的)
name = "ReSouSpider"
#爬虫爬取网页的域
allowed_domains=['http://top.sogou.com/']
#爬取网页的链接
start_urls = [
'http://top.sogou.com/'
]
#定义parse函数
def parse(self,response):
#网页中控制九个热门类型的div标签
divs = ['//div[@class="section s1"]',
'//div[@class="section s2"]',
'//div[@class="section s3"]',
'//div[@class="section s4"]',
'//div[@class="section s5"]',
'//div[@class="section s6"]',
'//div[@class="section s7"]',
'//div[@class="section s8"]',
'//div[@class="section s9"]']
#循环读取九个标签中的数据
for div in divs:
#这里获取到的是对应热门类型的第一条内容的名字
FName= response.xpath(div+'/ul/li/div[@class="txt-box"]/p/a/text()').extract()
#这里读取到的是对应热门类型的第一条内容对应的搜索指数
FStringData = response.xpath(div+'/ul/li/div[@class="txt-box"]/p/text()')[0].extract()
#获取搜索指数中的数据
FData=FStringData.split(":")[-1]
#这里读取到的是对应热门类型从第二条内容开始读取到的内容名字集
ONames = response.xpath(div+'/ul/li/a/text()').extract()
#连接数据库
conn = pymysql.connect(host="127.0.0.1",
port=3306,
user="root",
passwd="wph",
db="r",
charset='utf8mb4'
)
cursor = conn.cursor()
#获取到含有数据表名字的字符串
tableStringName = response.xpath(div+'/div/a/@href')[0].extract()
#通过截取字符串获取到数据表的名字
tableName = tableStringName.split('/')[0]
try:
#创建数据表,包含三条记录,(id 主键,自增,name,value)
cursor.execute("create table "+tableName+"(id int NOT NULL AUTO_INCREMENT,name varchar(255) NOT NULL,value varchar(255) NOT NULL,PRIMARY KEY (id))")
#将爬取到的热门类型的第一条内容的名字和搜索指数存储到数据表
cursor.execute("insert into "+tableName+"(name,value)values(%s,%s)",(FName,FData))
#存储够进行提交,没有提交将不会保存到数据库的表中
conn.commit()
Index=0
#开始遍历其他内容的名字
for EName in ONames:
#获取到从热门类型从第二条记录开始的数据集中的数据
OData=response.xpath(div+'/ul/li/span/text()')[Index].extract()
Index+=1
#将热门类型从第二开始的数据保存到数据库表中
cursor.execute("insert into "+tableName+"(name,value) values(%s,%s)",(EName,OData))
conn.commit()
finally:
cursor.close()
conn.close()
6>这样爬取网页的爬虫代码就编写好了,下一步就可以爬取网页了,打开DOS命令行,进入之前创建好的resou文件夹,开始爬取数据:
cd resou
scrapy crawl ReSouSpider7>输入命令点击回车后,爬虫就开始自动爬取数据了,等到出现下图是,就爬取结束。
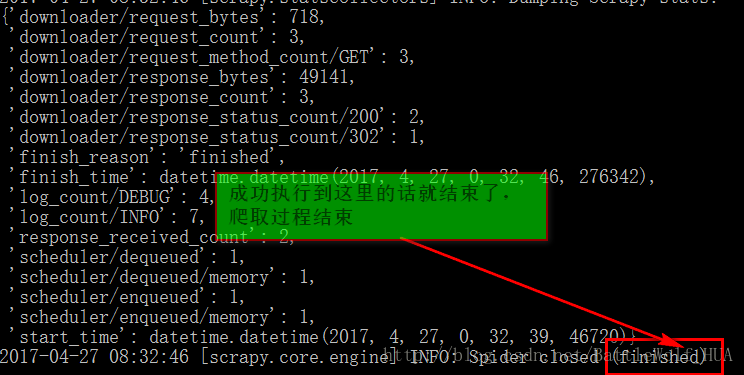
8>接下来就可以去数据库中查看爬取下的数据了,在DOS命令行登录数据库查看数据,记住自己的账号和密码哦
mysql -u数据库用户 -p数据库密码
show databases;
use resou;
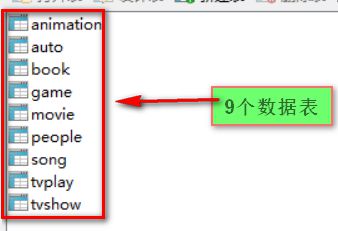
show tables;就会出现九个热门类型的数据表了,你可以挨个查看每个数据表中的数据
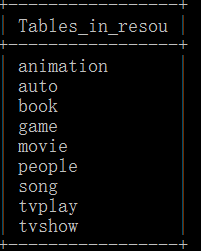
select * from animation或者你可以通过数据库可视化工具来查看我们爬取下的数据表和其中的数据:
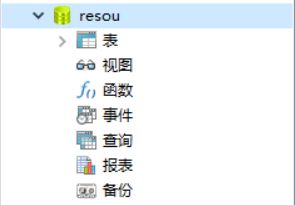
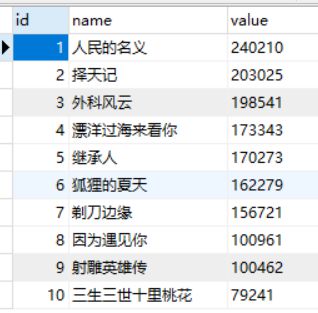
这里我们的爬虫爬取数据就结束了,这个过程中我们爬取了搜狗热搜榜上九个热门类型的数据,并把每个热门类型的前十条数据的名字和热搜数据保存到了mysql数据库,接下来我们就开始把这些数据做成南丁格尔图吧。
<三、借助Eclipse结合Echarts等组件做南丁格尔图>
1>打开Eclipse,创建一个动态web工程,名字就取为Echarts-NDGE
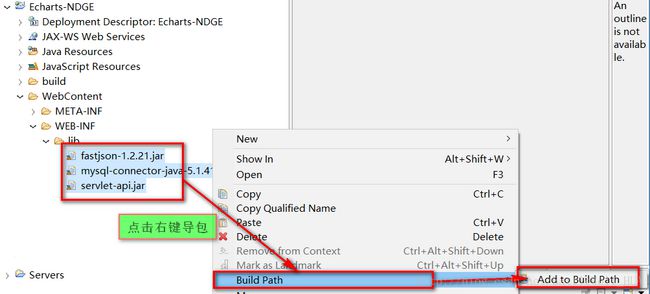
2>在webcontent->WEB-INFO->lib中导入所需要的jar包,并将他们加入到路径中去
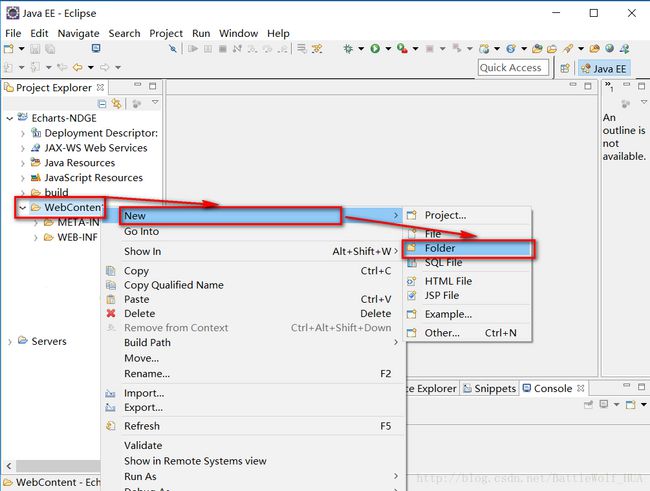
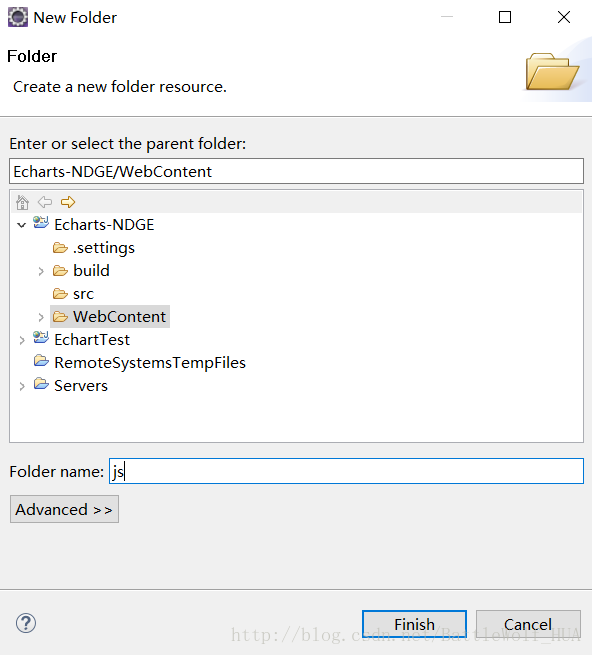
3>在webcontent文件下创建js文件夹,用来存放js文件
4>在创建好的js文件中加入我们需要用到的echarts和jquery这两个js文件

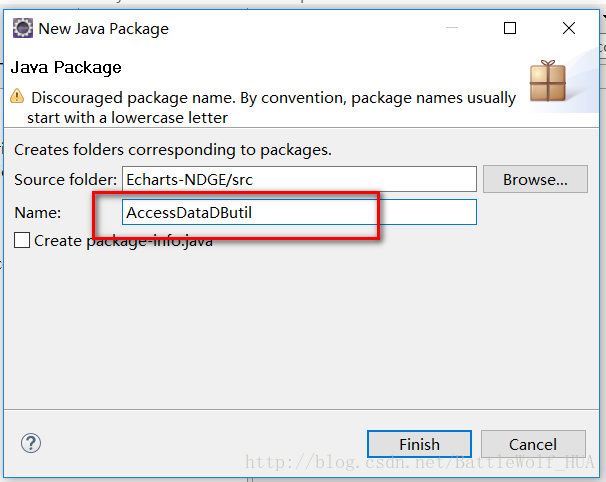
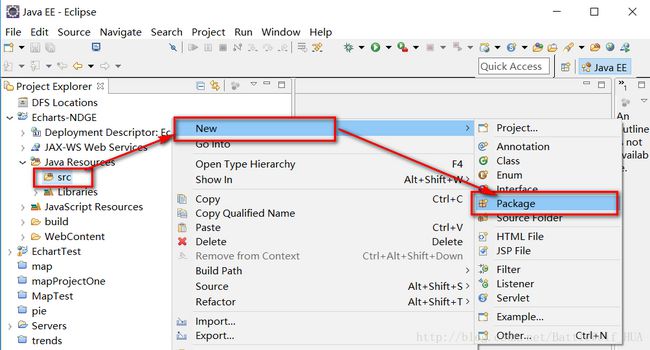
5>导包结束和文件添加结束后,我们就正式开始编程了,先从获取MySQL数据库的数据入手,在src下建立一个名为AccessDataDButil包,里边创建一个名为DButil的java文件

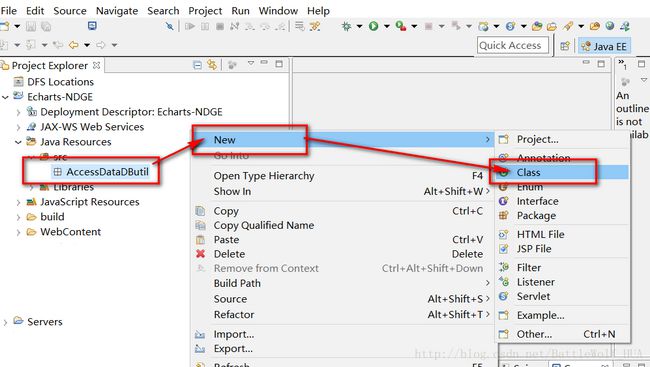

6>DButil.java中的代码如下;主要是连接数据库,在其他类调用时返回这个连接;
package AccessDataDButil;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DButil {
private Connection connection;
public Connection getConnection(){
try {
//加载驱动
Class.forName("org.gjt.mm.mysql.Driver");
//驱动连接数据库
connection=DriverManager.getConnection("jdbc:mysql://localhost:3306/resou","root","wph");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//返回connection
return connection;
}
public void ConnClose(){
try {
connection.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
7>在src文件下创建一个DataModel包,里边创建一个DataEntity.java文件;



在DataEntity中,对数据进行建模,规定数据的类型;
package DataModel;
public class DataEntity {
private String name;
private float value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getValue() {
return value;
}
public void setValue(float value) {
this.value = value;
}
}
8>在src文件下创建一个AccessDataDAO包,里边创建一个AccessDao.java文件;
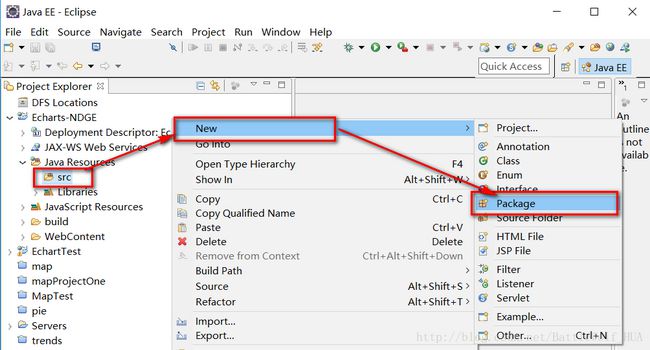
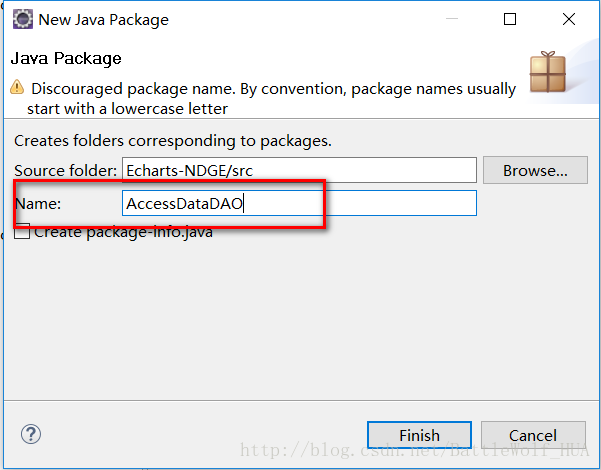

在AccessDao文件中编写代码,主要是获取数据库的连接,然后通过sql语句进行获取数据表中的数据。
package AccessDataDAO;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import AccessDataDButil.DButil;
import DataModel.DataEntity;
public class AccessDao {
Connection conn;
DButil db;
ResultSet set;
Statement st;
public List getAttribute(String TableName){
db=new DButil();
conn=db.getConnection();
String sql = "select name,value from "+TableName;
List list = new ArrayList();
try {
st = conn.createStatement();
set = st.executeQuery(sql);
while (set.next()) {
DataEntity entity = new DataEntity();
entity.setName(set.getString("name"));
entity.setValue(Float.parseFloat(set.getString("value")));
list.add(entity);
}
} catch (SQLException e) {
System.err.println(e.getMessage());
}
return list;
}
}
9>在src下面创建一个DataService包,在包下边创建一个getData.java文件

在getData文件中,对获取到的数据进行处理,并进行数据的传送;
package DataService;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.alibaba.fastjson.JSON;
import AccessDataDAO.AccessDao;
import DataModel.DataEntity;
public class getData extends HttpServlet{
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//编码类型
response.setContentType("text/html;charset=utf-8");
String[] dbName= {"movie","animation","book","people","auto","game","song","tvplay","tvshow"};
AccessDao dao=new AccessDao();
List list0,list1,list2,list3,list4,list5,list6,list7,list8;
list0=dao.getAttribute(dbName[0]);
list1=dao.getAttribute(dbName[1]);
list2=dao.getAttribute(dbName[2]);
list3=dao.getAttribute(dbName[3]);
list4=dao.getAttribute(dbName[4]);
list5=dao.getAttribute(dbName[5]);
list6=dao.getAttribute(dbName[6]);
list7=dao.getAttribute(dbName[7]);
list8=dao.getAttribute(dbName[8]);
String jsonString0=JSON.toJSONString(list0);
String jsonString1="?"+JSON.toJSONString(list1);
String jsonString2="?"+JSON.toJSONString(list2);
String jsonString3="?"+JSON.toJSONString(list3);
String jsonString4="?"+JSON.toJSONString(list4);
String jsonString5="?"+JSON.toJSONString(list5);
String jsonString6="?"+JSON.toJSONString(list6);
String jsonString7="?"+JSON.toJSONString(list7);
String jsonString8="?"+JSON.toJSONString(list8);
PrintWriter out = response.getWriter();
out.print(jsonString0);
out.print(jsonString1);
out.print(jsonString2);
out.print(jsonString3);
out.print(jsonString4);
out.print(jsonString5);
out.print(jsonString6);
out.print(jsonString7);
out.print(jsonString8);
//System.out.println(list.toString());
out.flush();
out.close();
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
10>在webcontent->WEB-INFO下边创建web.xml文件;


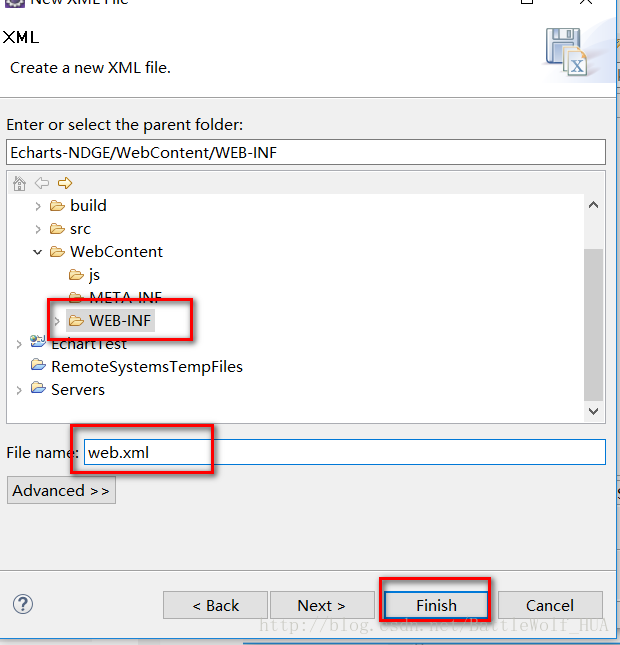
web.xml中代码为:
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" id="WebApp_ID" version="3.1">
<display-name>EchartTestdisplay-name>
<welcome-file-list>
<welcome-file>index.htmlwelcome-file>
<welcome-file>index.htmwelcome-file>
<welcome-file>index.jspwelcome-file>
<welcome-file>default.htmlwelcome-file>
<welcome-file>default.htmwelcome-file>
<welcome-file>default.jspwelcome-file>
welcome-file-list>
<servlet>
<servlet-name>getDataservlet-name>
<servlet-class>DataService.getDataservlet-class>
servlet>
<servlet-mapping>
<servlet-name>getDataservlet-name>
<url-pattern>/getDataurl-pattern>
servlet-mapping>
web-app>11>在webcontent下边创建一个showPicture.jsp文件,编写显示南丁格尔图的代码:
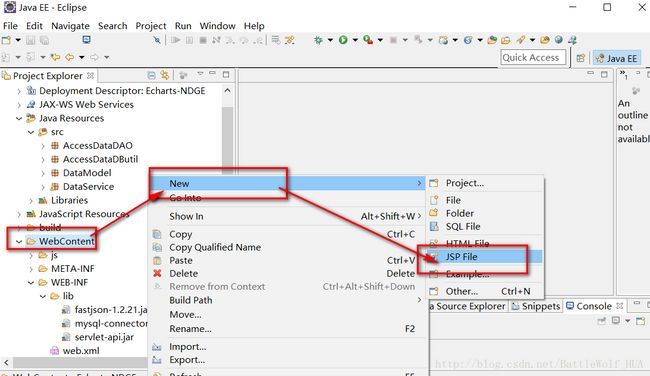
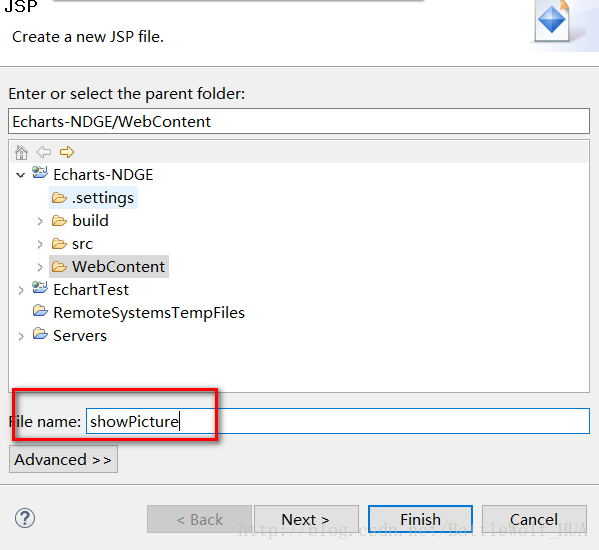
showPicture.jsp中的代码:
<%@ page language="java" import="java.util.*" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<% String path = request.getContextPath(); String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/"; %>
<html>
<head>
<base href="<%=basePath%>">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title heretitle>
<script type="text/javascript" src="js/jquery-2.1.4.min.js">script>
<script type="text/javascript" src="js/echarts.min.js">script>
head>
<body bgcolor="#F0F0F0">
<h1 align="center">南丁格尔玫瑰图h1><br>
<hr>
<br/>
<div id="main" style="width: 1400px;height:1000px;">div>
body>
<script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据 myChart.setOption({ title : { text: '本数据来自搜狗热搜榜---2017.04.27', x:'center' }, tooltip : { trigger: 'item', formatter: "{a}
{b} : {c} ({d}%)" }, toolbox: { show : true, feature : { mark : {show: true}, dataView : {show: true, readOnly: false}, magicType : { show: true, type: ['pie', 'funnel'] }, restore : {show: true}, saveAsImage : {show: true} } }, calculable : true, series : [ { name:'热门电影', type:'pie', radius : [30, 110], center : ['20%', '20%'], roseType : 'area', data:[] }, { name:'热门动漫', type:'pie', radius : [30, 110], center : ['50%', '20%'], roseType : 'area', data:[] }, { name:'热门小说', type:'pie', radius : [30, 110], center : ['80%', '20%'], roseType : 'area', data:[] }, { name:'热门人物', type:'pie', radius : [30, 110], center : ['20%', '50%'], roseType : 'area', data:[] }, { name:'热门汽车', type:'pie', radius : [30, 110], center : ['50%', '50%'], roseType : 'area', data:[] }, { name:'热门游戏', type:'pie', radius : [30, 110], center : ['80%', '50%'], roseType : 'area', data:[] }, { name:'热门音乐', type:'pie', radius : [30, 110], center : ['20%', '80%'], roseType : 'area', data:[] }, { name:'热门电视剧', type:'pie', radius : [30, 110], center : ['50%', '80%'], roseType : 'area', data:[] }, { name:'热门综艺', type:'pie', radius : [30, 110], center : ['80%', '80%'], roseType : 'area', data:[] } ] }); // 异步加载数据 var info = {"opt": "pie"}; $.post("./getData", info, function(data){ var dat=data.split("?"); var dat0=JSON.parse(dat[0]); var dat1=JSON.parse(dat[1]); var dat2=JSON.parse(dat[2]); var dat3=JSON.parse(dat[3]); var dat4=JSON.parse(dat[4]); var dat5=JSON.parse(dat[5]); var dat6=JSON.parse(dat[6]); var dat7=JSON.parse(dat[7]); var dat8=JSON.parse(dat[8]); /* for(var i=0; i < data.length; i++){ mapOnlyKey.push( data[i].name); mapKeyValue.push({"value":data[i].value, "name": data[i].name }); mapOnlyValue.push( data[i].value ); } console.log(mapOnlyKey); console.log(mapKeyValue); console.log(mapOnlyValue); alert(mapKeyValue); */ // 填入数据 myChart.setOption({ series: [{ data: dat0 }, { data: dat1 }, { data: dat2 }, { data: dat3 }, { data: dat4 }, { data: dat5 }, { data: dat6 }, { data: dat7 }, { data: dat8 } ] }); // 使用刚指定的配置项和数据显示图表。 }); script>
html>12>所有的工作都做完了,接下来运行jsp页面,来看看我们做的南丁格尔图吧
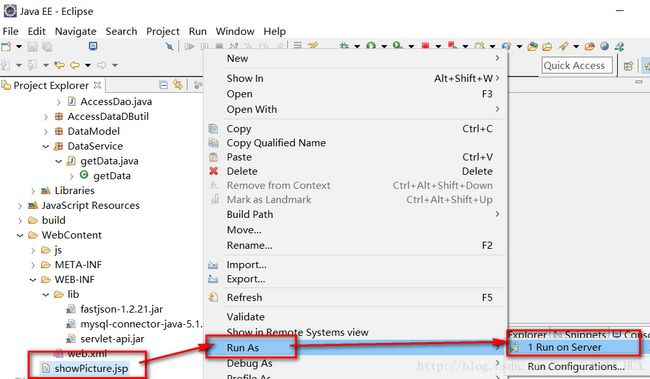
为了更好的查看,我们将链接复制下来,去浏览器上查看吧:

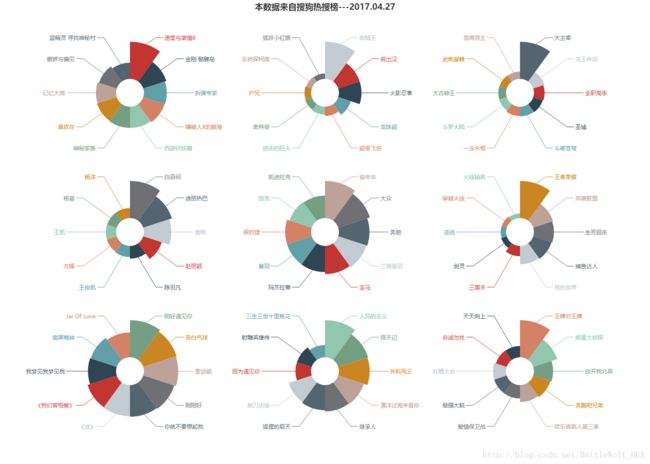
好了,这就是我们要展示的九个热门类型的南丁格尔图,通过这个图,我们可以清楚直观的看到热搜榜上各个热门类型的情况。