从这5个场景, 看MPC多方安全计算的行业应用

作者 | 章磊
责编 | Aholiab
出品 | CSDN、ARPA
在我们之前的“多方安全计算”系列文章中,我们首先通过姚期智教授的“百万富翁问题”引出了数据安全计算这个密码学话题,并介绍了多方安全计算在数据隐私中的应用场景。第二期中,我们又简要的介绍了两种“多方安全计算”的技术路线以及理论知识。
本期,我们将继续深入介绍多方安全计算在行业中的应用。通过这篇文章,读者可以了解到这样一个工具是如何在金融科技,机器学习中发挥作用,打破壁垒,保护隐私。也欢迎读者将安全多方计算放在您的工作场景中来启发出新的行业应用。
场景1 基金联合收益计算
在母基金管理中,我们需要计算每个基金的真实收益情况。而基金的持仓信息是一个非常重要的私密信息,它代表了基金的价值判断和策略导向,也是基金公司的核心机密。
一方面是出于管理预警作用所需要的信息共享,一方面是基金本身的商业信息的保护,传统方法必然导致一方的诉求无法得到满足。
使用MPC计算,不仅能够同时满足双发的利益诉求,甚至可以让基金信息得到有效的政府监管、防止出现市场结构性风险,同时保证商业信息不被泄露。

以一个典型的两方计算场景为例:一方提供编译好的计算函数,一方将加密的数据进行联合计算。代码极其简单,甚至几行代码就能实现其核心逻辑。
场景2 联合个人征信(不经意查询)
个人征信的场景大家再熟悉不过了,通过多个信息渠道对个人历史记录进行多维度计算,反应出一个人的信贷能力。
通过计算信用等级,贷款机构就能算出风险,并能决定是否放贷。个人数据维度越多,信贷能力的计算越准确。传统意义上,我们会使用央行给出的详细个人历史记录作为信用模型计算的依据。
而其他渠道的信息,例如电商购买行为,甚至是手机APP安装情况,都能帮助反应个人的肖像。
然而,多渠道信息融合的难度极大。一方面是法律因素:交易个人隐私信息是违法的;另一方面,处于商业利益的保护,数据共享也会导致数据持有公司失去竞争优势;再次,查询方也会暴露查询的对象和内容,从而在一定程度暴露信息。
而MPC能解决的核心问题,是通过不经意查询,达到数据不被公开、查询对象不暴露、而结果能够被正确查询返回。要达到这个核心目的,我们只需要一下几步:
数据拥有方将查询ID和对应数值构建数组a, b,组成数据库,并秘密分享。这样共享的数据不能被任何一方解密。注意ID需要将asic编码转化成特定的数值编码,方便查询;
查询方将查询ID进行秘密分享,这样所有人都不知道真实的ID是什么。这里ID也进行了相应的数值转换;
通过遍历计算得到相应的位置值。这里两点需要注意:a)查询必须遍历整个列表而不能终止,不然会暴露查询对象;b)返回的不是真实的位置,而是一个代表位置的表达值;
通过位置表达值再进行查询值搜索,最终得到一个多方秘密值;
将秘密求和即可得到最终的值。
ARPA已经将整个操作,包括数据库分享、不经意查询封装成简单的函数方便使用。示意代码如下:

场景3 供应链金融
供应链上下游企业,如何构建一个信息对称共享、核心企业信用价值可传递、商票可拆分流程,是一个极大的挑战。
如果能保证在风险可控前提下,创造出新型供应链金融融资模式,可以为监管提供数据追溯便利,提升行业整体服务效率。
传统供应链金融的实现过程中,有以下痛点:
传统的商票不可拆分,供应商无法基于商票再次背书转让,核心企业信用无法有效传递给多级供应商体系。
供应商、经销商之间的约定或合同信息无法得到有效确认或核实,使得金融机构存在较大的授信风险。
供应链层级的繁复,使贸易真实性和交易透明性无法简单通过系统进行确认和审核,造成了监管的不便利性。
在传统供应链金融多级供应商体系下,信息难以有效传递,使得一级供应商以外的其他层级供应商无法享受到核心企业的信用,融资较难。
比如有些厂商可以基于区块链和密码学算法,为供应链金融提供了金融资产数字化验证的方案,使得企业能够将企业应收账款进行数字化资产登记,形成不可篡改的数据记录,并实现实时信息共享。
同时,通过参与方分布式账本,参与方可以得到资产确认,将企业信用转化成数字资产。此外,还提供了审计入口,方便监管机构审计和查看平台的资产交易情况。最重要的是,在传统区块链只能保证数据的不可修改性前提下,通过MPC和零知识证明等加密技术,可帮助区块链实现智能合约的公开审计确认能力与实际数据保密性的分离,让企业不再担心核心商业信息的泄露。
核心实现内容如下:

场景4 机器学习
人工智能现阶段以机器学习为主,机器学习中使用的算法大体分为 3 类:监督学习、无监督学习和强化学习。
监督学习提供了反馈来表明预测正确与否,而无监督学习没有响应,算法仅尝试根据数据的隐含结构对数据进行分类。
强化学习类似于监督学习,因为它会接收反馈,但反馈并不是对每个输入或状态都是必要的。
目前行业的应用以监督学习为主。通过对数据进行标注所得到的训练数据集,可以用来进行监督训练。
如今,深度学习需要使用大量的数据训练模型。我们发现,一个优秀的深度学习模型是算法通过大量的数据集训练而达到的(而不是一个优秀的算法和少量的数据)。虽然算法理论不断丰富完善,具体的落地模型却被少数人掌握在手中,极为稀少和珍贵。我们都知道,算法+数据=机器学习模型。

然而,这样的共识却会导致一个后果:数据霸权。即数据掌握在少数公司手里。因为数据是企业的核心竞争力,越是有价值的数据,越是没有办法通过共享而产生价值。
这个问题可以通过MPC来解决。企业间可以不用担心数据流失,而是通过MPC实现数据租赁,从而可以得到数据价值变现。同时也让数据的使用价格低至原来的十分之一。
微软研究院也曾在类似方面有所探索,他们在刊发的论文CryptoNet中采用了同态加密的方式来保护CNN中处理的数据,同样因为计算复杂的问题,CryptoNet为CNN中的不同运算进行了对应的优化。
MIT进行生物医药研究的一个小组,利用了安全两方计算来实现了保护隐私的制药实验,传统制药中,可通过受体和药物之间的分子对比来预估药效,这个过程会涉及商业机密,MPC可在制药过程中一些简单步骤上得以应用。
Google则采取了一种完全不同的方案来解决CNN中的数据安全问题,联邦学习,然而这是一个具体问题具体分析的方法,只对分层神经网络有效。
一次CNN训练和预测过程示意图如下:

今天我们展示一下,如何使用Tensorflow实现MPC,从而达到计算深度神经网络。
利用MPC,构建一个CNN模型的代码如下:

下一步是实现MPC张量运算,代码如下:

最后是实现秘密分享,代码如下所示:

其他需要修改的运算
Softmax:是用来计算分类信息的运算操作,里面需要用到exponentiation的计算。这个操作比较复杂,这里就不展开了。
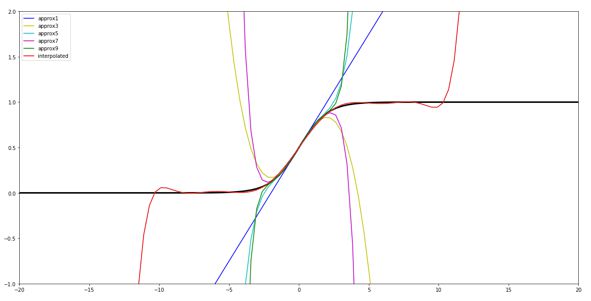
Sigmoid函数:激活函数是一个非线性函数,需要加以修改,我们使用一个9自由度的多项式代替。当然我们也可以使用ReLU来代替,这就需要用到garbled circuits,过程比较复杂,这里就不展开了。
多项式函数以及覆盖函数实现如下:

下图是用不同自由度实现的多项式拟合,最终我们使用了9度。
最终实现,使用TensorBoard可视化如下:

使用深度学习这个话题太大,还涉及Optimizer的优化,Dense Layer的实现,Dropout、Pooling、矩阵计算优化、预训练、迁移学习、精度损失、算法matrix对比、GPU实现等方面的话题。这些会在将来的文章里再详细解说。
场景5 联合风险价值计算
Value at Risk(VaR)按字面的解释就是“处于风险状态的价值”,即在一定置信水平和一定持有期内,某一金融工具或其组合在未来资产价格波动下所面临的最大损失额。
摩根大通定义为:VaR是在既定头寸被冲销(be neutraliged)或重估前可能发生的市场价值最大损失的估计值;而Jorion则把VaR定义为:“给定置信区间的一个持有期内的最坏的预期损失”。
VaR模型计算方法
计算VAR相当于计算E(ω)和ω*或者E(R)和R*的数值。从目前来看,主要采用三种方法计算VaR值:
1. 历史模拟法(historical simulation method);
2. 方差—协方差法;
3. 蒙特卡罗模拟法(Monte Carlo simulation)
咱们在这里主要用到历史模拟法。“历史模拟法”是借助于计算过去一段时间内的资产组合风险收益的频度分布,通过找到历史上一段时间内的平均收益,以及在既定置信水平α下的最低收益率,计算资产组合的VaR值。
计算方式为:首先,计算平均每日收入E(ω);其次,确定ω*的大小,相当于图中左端每日收入为负数的区间内,给定置信水平 α,寻找和确定相应最低的每日收益值。
设置信水平为α,由于观测日为T,则意味差在图的左端让出。
t=T×α,即可得到α概率水平下的最低值ω*。
由此可得:VaR=E(ω)-ω*
从数学上来看,这个工作非常简单。假设现有200支股票持仓的权重向量是w,长度为200。一年的股票价格数据为200x255的矩阵P。如果置信度α为95%,则我们寻找5%的最小的每日持仓价值。
1. 每日持仓价值 h = w’*P;
2. 排序价值 s = sort(h);
3. 找到5%排序价值s作为VaR
在MPC里面,我们除了实现简单的整数、定点小数的四则运算外,还要支持排序和矩阵运算来实现VaR计算。
当然,我们可以用多层循环来实现矩阵叉乘,但实际上,不仅在代码层看起来非常冗余和易错,更重要的是在基于秘密分享的安全计算里面,编译器会将这段逻辑忠诚地反应出来。
这会导致bite code及其庞大,以及计算效率很低。ARPA在矩阵运算上进行了优化,通过局部秘密共享和多线程技术将矩阵乘法优化了一个数量级。
在排序逻辑上,我们也进行了优化。简单来说,通过多个线程实现”Divide and Conquer”,将大量线性运算并行而达到效率的大幅提升。
具体代码示意如下:

结束语
综上所述,MPC可以在包括金融,互联网等行业中得以切实应用。并能够打破行业内已有的数据壁垒,保护数据隐私的同时消除因数据联合分析带来的法规风险,提升数据价值。
以上案例是我们在真实商业环境下与合作公司具体探讨的结果,新的密码学协议和工具需要应用在现实环境下,不止要保证安全性,效率,易用性等问题,还需要能让这个工具契合真实场景,解决真实问题。
*关于作者:
章磊,ARPA联合创始人&首席科学家,美国乔治华盛顿大学金融工程硕士,拥有十年深度学习、AI算法和风险建模经验,并对密码学有深度钻研。曾于硅谷最大的股权众筹公司CircleUp担任资深数据科学家;此前其就职于世界银行、AIG、PineBridge等大型金融机构,精通人工智能和量化策略。同时章磊于2017年创立星尘数据,为AI行业提供数据赋能。
ARPA是一家专注于安全加密计算和区块链底层技术的研发的公司,其核心产品为基于安全多方计算的隐私计算平台,并提供全套区块链+安全计算解决方案。同时ARPA作为行业成员,参与起草了工信部中国信息通信研究院即将出台的安全多方计算标准。

推荐阅读:
Libra硬刚微信、支付宝? 你也试试!
用50年前NASA送阿波罗上天的计算机挖矿什么体验? 出一个块要10^18年……
344亿天价罚单也救不了Libra!
"别太乐观, 冲破黑暗还很远呀! "
性能提升 3 倍的树莓派 4,被爆设计缺陷!
Kubernetes端到端解决方案Part3:如何正确部署Kubernetes
金山云肖江:5G 驱动智慧人居新发展
中文repo“霸榜”GitHub Trending,国外开发者不开心了
中国第一程序员,微软得不到他就要毁了他!
猛戳"阅读原文"有惊喜哟
老铁在看了吗?