Splinter基本用法+零基础的双鸭山抢课脚本
前言
之前一直想写个抢课脚本,但是欧皇加身,选的都中,但今年好运气到了头,报道注册那天,看见心仪的课有三个名额,但是,因为学校教务处还没开始办理注册,眼睁睁的看着3个名额飞走,后面几天,150个满名额雷打不动的占着,故花一天学习了Python的Splinter库实现了抢课脚本,教程推荐官网资料
PS:环境:Python36+Splinter0.77+chromedriver(调用google的exe程序)

Splinter
Splinter 提供一个调用浏览器的脚本接口,可以将人对浏览器的操作,打开某个链接,页面内的跳转,处理弹出窗口等功能转化为代码,是一个自动化测试的脚本库。总之,人对浏览器怎么操作,就怎么写代码就行了,简单易学,易学易用
一、Splinter安装以及环境配置
官方提供Pip安装方式,用cmd进入Python的Script目录,输入pip install splinter就能完成安装,当然,也pip不行的,也可以使用源码安装,具体见此处链接。

Splinter 能通过如下方式调用浏览器接口,具体见此处链接的Driver部分
- 打开一个浏览器,你可以像点击页面链接一样,看到浏览器的页面跳转。
- 不打开浏览器,模拟浏览器的动作,非可见。
因为总是搞不定学校的万恶验证码,所以通过打开浏览器,人判断并输入验证码,完成登录过程。注意:使用1方式,在电脑上必须安装相应浏览器,并下载驱动程序(也就是开头提到的chromedriver)放置在和你Py文件相同的路径

在py文件里,写如下代码,测试环境是否搭建成功
from splinter import Browser
if __name__ == '__main__':
browser = Browser('chrome') # 不加'chrome'等字符串,默认firefox
browser.visit('https://www.baidu.com/')出现如下图片代表环境搭建成功 如果不成功(可能需要pip install selenium,但我觉得在安装Splinter的时候已经安装了selenium依赖),请详细看官网的Google安装部分。

二、Splinter的基本使用
使用Splinter的重点在于找到你要完成的那个操作,比如,拿上面的百度图片来举例,我要完成的操作如下,通过上面的代码打开浏览器后
- 在文本框中输入中山大学
- 点击搜索按钮搜索
- 点击搜索引擎搜索到的第一个链接
在Google浏览器下,通过F12打开开发者工具或者通过选项等方式打开,按照如下步骤,获取文本框的源码tag属性
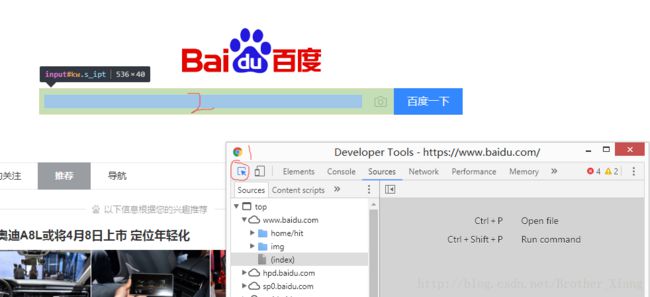

这里简要介绍一下html5和JavaScript,在以后学习开发前端页面中,会有更加详细的博客介绍,浏览器是解释html5呈现出网页给用户,html5中有很多tag,输入框是个tag,按钮是个tag,菜单也是个tag,每个tag中可以设置name和id的属性,其中id属性在整个html5中是唯一的,JavaScript可以让网页某段文字消失或者变换色彩,除此之外JavaScript使用AJAX与服务器进行交互,AJAX发送请求,再接收服务器的答应,百度的点击搜索按钮,AJAX将文本框中输入的东西发送到服务器端,再接收返回的搜索数据呈现出来,当然,这只是简单的举例说明,详细情况复杂得多,但对于此教程来说,已经足够了。
上面输入框的tag源码中,name=’wd’, id=’kw’,我们考虑使用name(使用了browser的一个便捷方法.fill())来定位百度文本框。加上如下代码,即为文本框输入文字:
browser.fill('wd', '中山大学')再来看下,fill实际上是先通过属性name=’wd’找到输入框,再调用输入框的输入函数,输入数据,输入函数如果你查官网的话,可以发现是type(不过只能用在已经找到的tag上),而找到输入框的函数有很多:
browser.find_by_css('h1')
browser.find_by_xpath('//h1')
browser.find_by_tag('h1')
browser.find_by_name('name')
browser.find_by_text('Hello World!')
browser.find_by_id('firstheader')
browser.find_by_value('query')css是层叠样式表,你看小说的时候,换背景,换的就是css,xpath目前不了解,tag就是我们上面说的标签,name是刚才用来寻找元素的属性,text就是源码内的tag的<>扩住的部分,id,value是<>扩住的部分去除左右两端空格和缩进符得到的结果,text和value的使用区别,大家试一下就知道了。
其中值得说一下的是,上面这些方法找到的是一个list,需要通过数组索引方式[],来取得相应元素,通过这些find_by_*方式找到的tag,再对找到的tag调用find_by_*,这就为我们定位元素提供了便利
下面是完成步骤1,2,3的源码,供大家参考尝试
from splinter import Browser
if __name__ == '__main__':
browser = Browser('chrome')
browser.visit('https://www.baidu.com/')
browser.fill('wd', '中山大学')
search_button = browser.find_by_id('su')
search_button.click()
search_result = browser.find_by_id('content_left')[0] # 获取搜索页面tag
# css就是class属性, 但是具体要看开发者工具中的Styles
tag_result = search_result.find_by_css('.c-container')[0] # 获取第一条链接
# 该条链接有2个, 点击哪条链接都可以, 这里点击第一条链接
tag_result.find_by_tag('a')[0].click()对的,写抢课脚本,只用知道这些就够用了,更加详细的教程,请观看上面发的官网链接,大家各取所需就好
抢课脚本
由于双鸭山把选课系统限制为内网才能访问,所以以下代码只能是同为双鸭山的同学使用,有不懂的同学,可以csdn私信问我,代码效果可以看视频。
代码
from splinter import Browser
import time
if __name__=='__main__':
browser = Browser('chrome')
browser.visit('https://cas.sysu.edu.cn/cas/login?service=https%3A%2F%2Fuems.sysu.edu.cn%2Felect%2FcasLogin')
submit = browser.find_by_name('submit')
browser.fill('username', 'NetID')
browser.fill('password', '密码')
browser.fill('captcha', '')
time.sleep(5) # 等5秒给你输入验证码
submit.click()
browser.find_by_text(''' 专选(改补选) ''').click()
courses_table = browser.find_by_id('courses')
courses_list = courses_table.find_by_tag('tr')
Flag = True
while Flag:
for i in range(1, len(courses_list)):
course = courses_list[i]
line = course.find_by_tag('td')
operation, course_name = line[0].find_by_tag('div'), line[1].value
if course_name == 'Android 应用设计与开发':
a_tag = operation.find_by_tag('a')
if len(a_tag) != 0:
a_tag.click()
alert = browser.get_alert()
alert.accept()
Flag = False
else:
time.sleep(3)
break
if Flag:
browser.reload()
courses_table = browser.find_by_id('courses')
courses_list = courses_table.find_by_tag('tr')