java容器的学习
首先
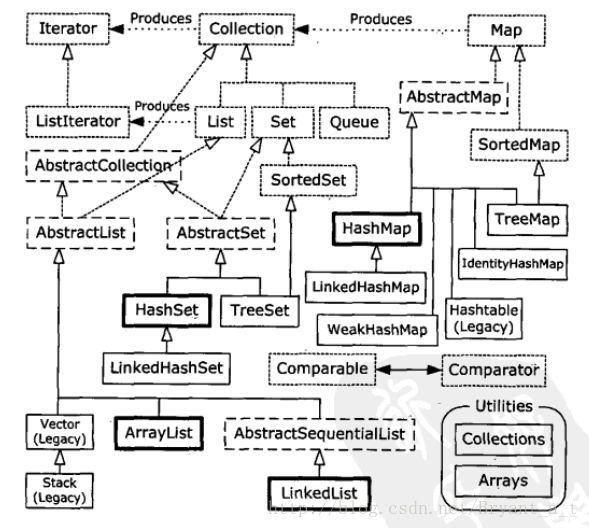
这张图从上往下看,首先是两个重要的接口,Collection和Map
基接口Map
包含的抽象方法
int size()、Boolean isEmpty()、Boolean containsKey(K)、Boolean containsValue(V)、V get()、 V put(K)(该方法在执行成功时会把被覆盖的value值返回)、V remove(K)(该方法返回的是移除的键值对的value值)、void putAll(Map m)把参数m里的值都put到Map中、void clear()、Set KeySet()、Collection values()、equals()、hashCode()
注意:关于Map的遍历方式,直接或间接,
Collection values()
Set keySet()
Set< Map.Entry< K, V>> entrySet()
HashMap
HashMap extends AbstractMapimplements Map, Cloneable, Serializable
(1)初始大小
默认的初始大小是16
默认的负载因子是0.75
扩容是增加到原来的2倍
(2)是否存储NULL值
key、value都可以为NULL
(3)是否是线程安全的
不是线程安全的容器,举个栗子
在进行put操作的时候会进入死循环
private HashMap hashMap = new HashMap<>();
void test(){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
for(int i=0;i<100;++i)
{
new Thread(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
hashMap.put(UUID.randomUUID().toString(),2);
}
}).start();
}
}
});
thread.start();
try {
thread.join();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(hashMap.size());
} 在多线程条件下,put操作查找entry的一个为空的结点插入,但是多线程造成的就是找不到为空的那个节点,所以一直循环找,引起CPU占用率过高。
(4)定位桶的hash算法
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);这里的移位操作主要就是为了让原本传入的参数,尽可能每一位都参与到hash过程当中去,即就是充分哈希。
定位桶下标的函数
static int indexFor(int h, int length) {
return h & (length-1);
}这里就充分说明了为什么HashMap函数的默认桶个数是16,即2的次方个。因为如果不是2的次方个,那么减1以后最后一位就是0,那么按位与以后就永远得不到奇数下标的桶,明显不合理。
(5)主要方法
只重写了containsKey
public boolean containsKey(Object key) {
return getEntry(key) != null;
}(6)迭代方式
java.util.Iterator
Iterator.Entry> it = hashmap.entrySet.iterator(); HashTable
HashTable extends Dictionary implements Map, Cloneable, java.io.Serializable
(1)初始大小
默认的初始大小是11
默认的负载因子是0.75
扩容是增加到原来桶的个数*2+1
(2)是否存储NULL值
key、value都不可以为空,为空时会抛出空指针异常。
这里与HashMap有区别主要是因为Hashtable在进行散列的时候会调用key.hashCode(),在key为空的时候会抛出空指针异常,而且在进行put操作的时候,会先主动的判断value值是否为空,为空则抛出NullPointException
(3)是否是线程安全的
是线程安全的,Hashtable里面关于数据的写操作都是用 synchronized修饰的
(4)定位桶的hash算法
private int hash(Object k) {
return hashSeed ^ k.hashCode();
}
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;按位与上这一个值主要是为了去掉符号位,因为hash值可能是负值,而且这里的桶的默认大小是奇数值也是因为求对应下标的时候是对模上桶的个数。
(5)主要方法
contains()、containsKey()、containsValue()
(6)遍历方式
枚举
private Enumeration getEnumeration(int type) {
if (count == 0) {
return Collections.emptyEnumeration();
} else {
return new Enumerator<>(type, false);
}
} 使用方式,
hasMoreElements(),nextElements()
Hashtable里面关于iterator的方法,其实底层调用的也都是枚举迭代方式的相关方法。
TreeMap
主要特点
(1)TreeMap KEY不能为NULL VALUE可以为NULL
(2)TreeMap KEY重复覆盖 VALUE可以为重复
(3)TreeMap 按照自然顺序排序 或者按照算法排序 这里的排序主要是根据comparable或者在初始化时传入的comparator参数决定的。
底层结构是一颗红黑树(这个到后面再研究)
(4)TreeMap 非线程安全
LinkedHashMap
public class LinkedHashMap<K,V>extends HashMap<K,V> implements Map<K,V>和HashMap相比,主要是把所有的所有的桶也用链表链接起来,所以在遍历的时候的顺序和插入的顺序是相同的。