摘要
日常开发中,需要用到各种各样的框架来实现API、系统的构建。作为程序员,除了会使用框架还必须要了解框架工作的原理。这样可以便于我们排查问题,和自定义的扩展。那么如何去学习框架呢。通常我们通过阅读文档、查看源码,然后又很快忘记。始终不能融汇贯通。本文主要基于Spring Cache扩展为例,介绍如何进行高效的源码阅读。
SpringCache的介绍
为什么以Spring Cache为例呢,原因有两个
- Spring框架是web开发最常用的框架,值得开发者去阅读代码,吸收思想
- 缓存是企业级应用开发必不可少的,而随着系统的迭代,我们可能会需要用到内存缓存、分布式缓存。那么Spring Cache作为胶水层,能够屏蔽掉我们底层的缓存实现。
一句话解释Spring Cache: 通过注解的方式,利用AOP的思想来解放缓存的管理。
step1 查看文档
首先通过查看官方文档,概括了解Spring Cache
https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-caching.html
重点两点
- 两个接口抽象
Cache,CacheManager,具体的实现都是基于这两个抽象实现。
典型的SPI机制,和eat your dog food。当需要提供接口给外部调用,首先自己内部的实现也必须基于同样一套抽象机制
The cache abstraction does not provide an actual store and relies on abstraction materialized by the org.springframework.cache.Cache and org.springframework.cache.CacheManager interfaces.
Spring Cache提供了这些缓存的实现,如果没有一种
CacheManage,或者CacheResolver,会按照指定的顺序去实现If you have not defined a bean of type CacheManager or a CacheResolver named cacheResolver (see CachingConfigurer), Spring Boot tries to detect the following providers (in the indicated order):
1.Generic
2.JCache (JSR-107) (EhCache 3, Hazelcast, Infinispan, and others)
3.EhCache 2.x
4.Hazelcast
5.Infinispan
6.Couchbase
7.Redis
8.Caffeine
9.Simple
step2 run demo
对Spring Cache有了一个大概的了解后,我们首先使用起来,跑个demo。
定义一个用户查询方法
@Component
public class CacheSample {
@Cacheable(cacheNames = "users")
public Map getUser(final Collection userIds) {
System.out.println("not cache");
final Map mapUser = new HashMap<>();
userIds.forEach(userId -> {
mapUser.put(userId, User.builder().userId(userId).name("name").build());
});
return mapUser;
} 配置一个CacheManager
@Configuration
public class CacheConfig {
@Primary
@Bean(name = { "cacheManager" })
public CacheManager getCache() {
return new ConcurrentMapCacheManager("users");
}API调用
@RestController
@RequestMapping("/api/cache")
public class CacheController {
@Autowired
private CacheSample cacheSample;
@GetMapping("/user/v1/1")
public List getUser() {
return cacheSample.getUser(Arrays.asList(1L,2L)).values().stream().collect(Collectors.toList());
}
} step3 debug 查看实现
demo跑起来后,就是debug看看代码如何实现的了。
因为直接看源代码的,没有调用关系,看起来会一头雾水。通过debug能够使你更快了解一个实现。
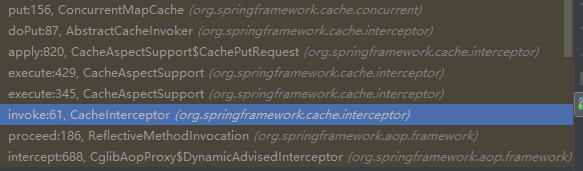
通过debug我们会发现主要控制逻辑是在切面CacheAspectSupport
会先根据cache key找缓存数据,没有的话put进去。
// Check if we have a cached item matching the conditions
Cache.ValueWrapper cacheHit = findCachedItem(contexts.get(CacheableOperation.class));
// Collect puts from any @Cacheable miss, if no cached item is found
List cachePutRequests = new LinkedList<>();
if (cacheHit == null) {
collectPutRequests(contexts.get(CacheableOperation.class),
CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);
} step4 实现扩展
知道如何使用Spring Cache后,我们需要进一步思考,就是如何扩展。那么带着问题出发。
比如Spring Cache不支持批量key的缓存,像上文我们举的例子,我们希望缓存的key是userId,而不是Collection userIds。以userId为key,这样的缓存命中率更高,存储的成本更小。
@Cacheable(cacheNames = "users")
public Map getUser(final Collection userIds) { 所以我们要实现对Spring Cache进行扩展。step3中我们已经大致了解了Spring Cache的实现。那么实现这个扩展的功能就是拆分Collection userIds,缓存命中的从缓存中获取,没有命中的,调用源方法。
@Aspect
@Component
public class CacheExtenionAspect {
@Autowired
private CacheExtensionManage cacheExtensionManage;
/**
* 返回的结果中缓存命中的从缓存中获取,没有命中的调用原来的方法获取
* @param joinPoint
* @return
*/
@Around("@annotation(org.springframework.cache.annotation.Cacheable)")
@SuppressWarnings("unchecked")
public Object aroundCache(final ProceedingJoinPoint joinPoint) {
// 修改掉Collection值,cacheResult需要重新构造一个
args[0] = cacheResult.getMiss();
try {
final Map notHit = CollectionUtils.isEmpty(cacheResult.getMiss()) ? null
: (Map) (method.invoke(target, args));
final Map hits = cacheResult.getHit();
if (Objects.isNull(notHit)) {
return hits;
}
// 设置缓存
cacheResult.getCache().putAll(notHit);
hits.putAll(notHit);
return hits;
}
} 然后扩展Cache,CacheManage
重写Cache的查找缓存方法,返回新的CacheResult
public static Object lookup(final CacheExtension cache, final Object key) {
if (key instanceof Collection) {
final CollectionCacheResult就是新的缓存结果格式
@Builder
@Setter
@Getter
static class CacheResult {
final CacheExtension cache;
// 命中的缓存结果
final Map hit;
// 需要重新调用源方法的keys
private Set 然后扩展CacheManager,没什么重写,就是自定义一种manager类型
为缓存指定新的CacheManager
@Primary @Bean public CacheManager getExtensionCache() { return new CacheExtensionManage("users2"); }
完整代码
https://github.com/FS1360472174/javaweb/tree/master/web/src/main/java/com/fs/web/cache
总结
本文主要介绍一种源码学习方法,纯属抛砖引玉,如果你有好的方法,欢迎分享。
关注公众号【方丈的寺院】,第一时间收到文章的更新,与方丈一起开始技术修行之路
