阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台、云梯2、MaxCompute、实时计算到底是什么,和自建Hadoop平台有什么区别。
先说Hadoop
什么是Hadoop?
Hadoop是一个开源、高可靠、可扩展的分布式大数据计算框架系统,主要用来解决海量数据的存储、分析、分布式资源调度等。Hadoop最大的优点就是能够提供并行计算,充分利用集群的威力进行高速运算和存储。
Hadoop的核心有两大板块:HDFS和MapReduce。
HDFS全称Hadoop Distributed File System,是一种分布式文件存储系统。分布式文件系统是指将固定于某个地点的某个文件系统,扩展到任意多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。HDFS有着高容错性,可以部署在低廉的硬件;提供高吞吐量来访问应用程序的数据;可以有效解决超大数据量存储和管理难题的分布式文件系统属性的特点。因此HDFS天然适合有着超大数据集的应用程序,或者说本身就是为超大规模数据量处理的应用程序而设计的。
MapReduce是一个分布式离线并行计算框架,能够对大数据集进行并行处理。MapReduce就是将一个超大规模计算量的任务或者说数据量分割成无数小的计算任务与计算文件,然后再将计算结果进行合并的过程。MapReduce主要分为Map和Reduce两个阶段。Map是计算阶段,计算足够小的计算任务。Reduce是汇总阶段,将map阶段的计算结果汇总合并起来。
Hadoop的初始版本或者说核心就是这两大板块:HDFS为海量数据提供了存储,而MapReduce为海量数据提供了计算框架。
Hadoop的历史
1998年9月4日,Google公司在美国硅谷成立。
与此同时,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库,命名为Lucene。Lucene是用JAVA写成的,因为好用而且开源,非常受程序员们的欢迎。
2001年底,Lucene成为Apache软件基金会jakarta项目的一个子项目。
2004年,Doug Cutting在Lucene的基础上和Apache开源伙伴Mike Cafarella合作开发了一款开源搜索引擎,命名为Nutch。Nutch是一个建立在Lucene核心之上的网页搜索应用程序,类似于Google。
随着时间的推移,互联网发展迅速,数据量暴增,搜索引擎需要检索的对象的数据量也在不断增大。尤其是Google,需要不断优化自己的搜索算法,提升搜索效率。在这个过程中Google提出了不少的新方法与思路。
2003年,Google发表了一篇技术学术论文,公开了自己的谷歌文件系统GFS(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件系统。
第二年,2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。
2004年,Google又发表了一篇技术学术论文,公开了自己的MapReduce编程模型。MapReduce用于大规模数据集的并行分析运算。
第二年,2005年,Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了大规模数据集的并行分析运算。
2006年,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop。NDFS也改名为HDFS(Hadoop Distributed File System)。
此后,大名鼎鼎的大数据框架系统——Hadoop诞生。而Doug Cutting也被人们称为Hadoop之父。
所以说Hadoop的核心就两大部分:为大数据提供存储的HDFS和为大数据计算的MapReduce。

HDFS与MapReduce的核心工作原理
HDFS
HDFS主要有两个角色:NameNode、DataNode和Client。
NameNode是HDFS的守护程序,也是是Master节点,主节点。NameNode中会存储文件的元数据信息,记录文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,可以对内存和I/O进行集中管理。NameNode单点在发生故障时将使集群崩溃。
DataNode是Slave节点,从节点。DataNode负责把HDFS数据块读写到本地文件系统,是真正存储文件的节点。一个文件会被切割成一个或者多个block块,这些block块会被存储在一系列的DataNode节点中,并且每一个块可能会在多个DataNode上存在备份。
Client:用户与HDFS的桥梁。主要用于切分用户提交的文件,与NameNode交互,获得文件位置信息。然后直接与DataNode交互,读取和写入数据。
HDFS写入流程(参考的现有文档):
1、用户向Client(客户机)提出请求。例如,需要写入200MB的数据。
2、Client制定计划:将数据按照64MB为块,进行切割;所有的块都保存三份。
3、Client将大文件切分成块(block)。
4、针对第一个块,Client告诉NameNode(主控节点),请帮助我,将64MB的块复制三份。
5、NameNode告诉Client三个DataNode(数据节点)的地址,并且将它们根据到Client的距离,进行了排序。
6、Client把数据和清单发给第一个DataNode。
7、第一个DataNode将数据复制给第二个DataNode。
8、第二个DataNode将数据复制给第三个DataNode。
9、如果某一个块的所有数据都已写入,就会向NameNode反馈已完成。
10、对第二个Block,也进行相同的操作。
11、所有Block都完成后,关闭文件。NameNode会将数据持久化到磁盘上。
HDFS读取流程:
1、用户向Client提出读取请求。
2、Client向NameNode请求这个文件的所有信息。
3、NameNode将给Client这个文件的块列表,以及存储各个块的数据节点清单(按照和客户端的距离排序)。
4、Client从距离最近的数据节点下载所需的块。
MapReduce
MapReduce主要也有两个角色:JobTracker和TaskTracker。
JobTracker,类似于 NameNode。JobTracker是 Hadoop 集群中惟一负责控制 MapReduce应用程序的系统,位于Master节点上。在用户计算作业的应用程序提交之后,JobTracker决定有哪些文件参与处理,使用文件块信息确定如何创建其他 TaskTracker 从属任务,同时监控task并且于不同的节点上重启失败的task。TaskTracker位于slave从节点上与dataNode结合管理各自节点上由jobtracker分配的task,每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务。每个 TaskTracker 将状态和完成信息报告给 JobTracker。
(实际上MapReduce计算逻辑非常复杂,以上只是简化描述)
HDFS和MapReduce的组合只是Hadoop的1.0版本,这个版本有一些比较大的缺陷:
1、可伸缩性问题:JobTracker负载较重,JobTracker 必须不断跟踪数千个 TaskTracker、数百个作业,以及数万个 map 和 reduce 任务。相反,TaskTracker 通常只运行十来个任务。JobTracker存在单点故障,成为性能瓶颈。
2、可靠性差,NameNode只有一个,万一挂掉,整个系统就会崩溃。
为了解决一些问题,2012年5月,Hadoop推出了 2.0版本 。
2.0版本中,在HDFS与MapReduce之间,增加了YARN资源管理框架层。

YARN全称Yet Another Resource Negotiator是一个资源管理模块,负责整个集群资源的管理和调度,例如对每个作业,分配CPU,内存等等,都由yarn来管理。它的特点是扩展性,容错性,多框架资源统一调度。区别于hadoop1.0只支持MapReduce作业,yarn之上可以运行不同类型的作业。很多应用都可以运行在yarn之上,由yarn统一进行调度。
YARN的运行原理:
YARN的一个基本思想是讲资源管理和作业调度/监视的功能分解为独立的守护进程。其思想是有一个全局的ResourceManager (RM) 和每一个应用的ApplicationMaster (AM)。一个应用可以是单个的job,也可以是一组job。
YARN框架由ResourceManager节点和NodeManager组成。ResourceManager具有着应用系统中资源分配的最终权威。NodeManager是每台机器的一个框架代理,监控每台机器的资源使用情况(cpu、内存、磁盘、网络),同时上报给ResourceManager。每一个应用的ApplicationMaster是一个框架特定的库,它的任务是向ResourceManager协调资源并与NodeManager一起执行监视任务。
从流程上来说:当用户提交了一个计算任务,ResourceManager首先会在一个NodeManager为这个任务生成一个ApplicationMaster作为任务的管理者,ApplicationMaster向ResourceManager申请所需要的资源,ResourceManager会告诉NodeManager分配资源,NodeManager分配资源来供任务进行计算。NodeManager在不断的向ResourceManager汇报资源使用情况。
其实MapReduce与HDFS并不是一定要互相耦合工作的,两个都可以彼此独立工作,MapReduce也可以连接本地文件服务来进行计算,但是他们互相配合的时候才能发挥出最大的能力。
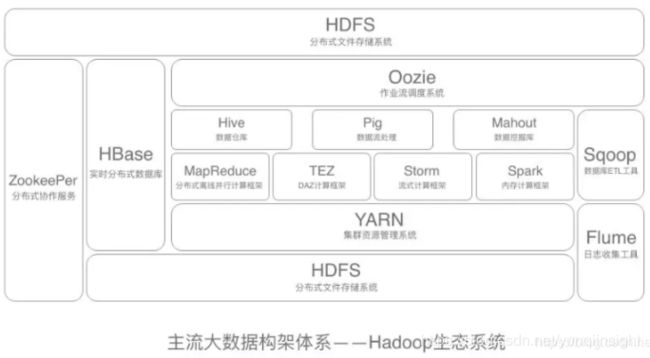
大数据架构体系——Hadoop生态系统
目前业界内最流行的大数据架构体系就是Hadoop的生态系统。目前,包括Yahoo、IBM、Facebook、亚马逊、阿里巴巴、华为、百度、腾讯等公司,都采用Hadoop构建自己的大数据系统,当然,是在Hadoop的基础上进行二次开发。
Hadoop生态系统是指以大数据分布式存储(HDFS),分布式计算(MapReduce)和资源调度(YARN)为基础联合其他各种组件在内的一整套软件。Hadoop生态系统的每一个子系统只解决某一个特定的问题域。不是一个全能系统,而是多个小而精的系统。
在这之前有个插曲:
2006年,Google又发论文了。这次,Google介绍了自己的BigTable,一种分布式数据存储系统,用来处理海量数据的非关系型数据库。
于是Doug Cutting在自己的Hadoop系统里面又引入了BigTable,并命名为HBase。
简单介绍Hadoop生态系统的主要构成组件:
HDFS: 基础的文件系统,Hadoop分布式文件系统
MapReduce:并行计算框架,运行在Yarn之上
HBase: 类似Google BigTable的分布式NoSQL列分布式数据库。适用于实时快速查询的场景。
Hive:数据仓库工具。处理的是海量结构化日志数据的统计问题。可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Zookeeper:分布式协调服务,“动物园管理员”角色,是一个对集群服务进行管理的框架,主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度。
Pig: 一个基于Hadoop的大规模数据分析工具,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
Sqoop:在Hadoop与传统的数据库间进行数据的传递。
Mahout:一个可扩展的机器学习和数据挖掘库,实现了很多数据挖掘的经典算法,帮助用户很方便地创建应用程序。
Oozie/Azkaban:一个工作流调度引擎,用来处理具有依赖关系的作业调度。
Presto/Kylin:一个交互式的查询引擎,实现低延时查询。
Flume:日志收集框架。将多种应用服务器上的日志,统一收集到HDFS上,这样就可以使用hadoop进行处理
对于大数据领域最早的应用者阿里巴巴对大数据的研究是一直走在前列的。感兴趣的用户可以看看一本书:《阿里巴巴大数据之路》书中很详细的介绍了阿里巴巴的整体大数据架构。
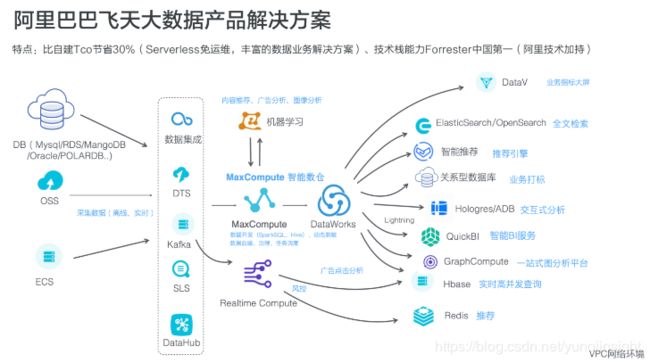
阿里巴巴飞天大数据平台是在开源Hadoop的基础上自研的一套体系,这种Serverless大数据服务成为当下主流趋势,可以减少企业本地服务器部署压力,显著提升企业工作效率的同时减少了企业在开发和人力方面的成本投入,让企业能更专注于业务发展,培养更多面向业务的技术人员。

7月25日,阿里云飞天大数据平台亮相阿里云峰会上海站,拥有中国唯一自主研发的计算引擎,是全球集群规模最大的计算平台,最大可扩展至10万台计算集群,支撑海量数据存储和计算。
原文链接
本文为云栖社区原创内容,未经允许不得转载。