模型评估和超参数调整(二)——交叉验证 (cross validation)
读《python machine learning》chapt 6
Learning Best Practices for Model Evaluation and Hyperparameter Tuning
【主要内容】
(1)获得对模型评估的无偏估计
(2)诊断机器学习算法的常见问题
(3)调整机器学习模型
(4)使用不同的性能指标对评估预测模型
git源码地址 https://github.com/xuman-Amy/Model-evaluation-and-Hypamameter-tuning
【交叉验证 cross-validation】
常见的交叉验证方法holdout cv ,k-fold cv
【cross-validation ----holdout CV】
【主要思想】
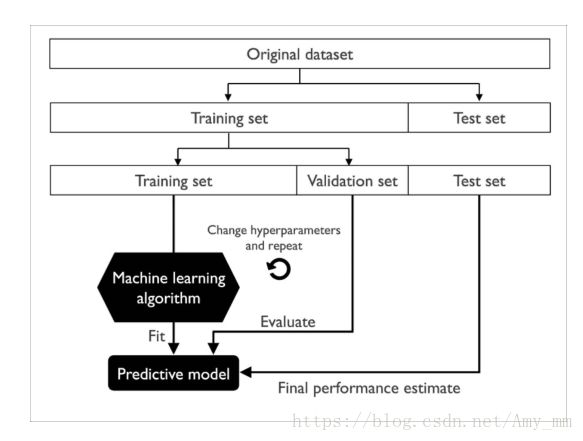
将数据分为三部分:训练集(training data )、 验证集(validation data) 、 测试集(test data)
训练集(training data ):fit不同的模型
验证集(validation data):用于模型选择
测试集(test data):对于泛化到新数据的性能,能得到较小偏差的估计值
流程图:
【缺点】
性能评估对于如何划分训练集和验证集比较敏感,对于不同的数据样本得到的性能评估不同。
【cross-validation ----k-fold CV】
【主要思想】
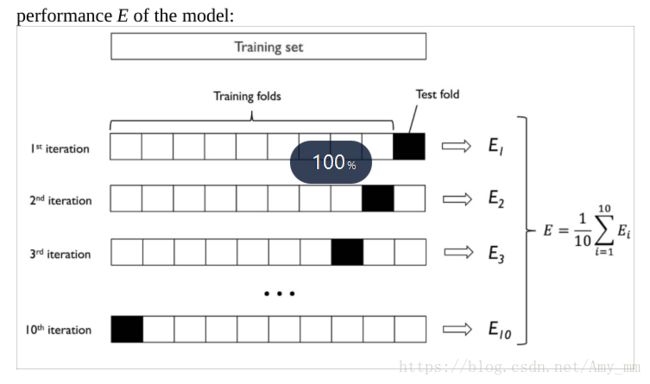
将数据集无替换的随机分为K份,k-1份用来fit模型,剩下的一份用来性能评估。这样重复k次,得到K个模型和性能评估结果。
在得到K个性能评估后,计算平均性能评估。
另外,也可以找到泛华能力较好的最优参数。
找到这一参数后,在整个数据集上重新训练模型,再用独立的测试集得到最终的性能评估。
【K=10 的 流程图】
【stratified k-fold CV】
对于k-fold CV的一个改进时stratified k-fold CV,在每个训练集中保留了原始数据的类比例。
【sklearn实现 stratified k-fold cv】
# stratified k-fold cv
import numpy as np
from sklearn.model_selection import StratifiedKFold
Kfold = StratifiedKFold(n_splits = 10,
random_state = 1).split(X_train, y_train)
scores = []
for k ,(train, test) in enumerate (Kfold):
pipe_lr.fit(X_train[train], y_train[train])
score = pipe_lr.score(X_train[test], y_train[test])
scores.append(score)
print('Fold: %2d, Class dist.: %s, Acc: %.3f' % (k+1, np.bincount(y_train[train]), score))
print('\nCV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))
sklearn 提供了k-fold cross-validation scorer, 可利用stratified k-fold cross-validation直接评估模型
from sklearn.model_selection import cross_val_score
scores = cross_val_score(estimator = pipe_lr,
X = X_train,
y = y_train,
cv = 10,
n_jobs = 1)
print('CV accuracy scores:\n\n %s \n' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))