几个有用的R小函数
最近写的代码基本是R脚本了,越发感到R的强大。现在用它做一些数据分析以及进行一些模拟。
收几个常的函数在这里。
1. 批次替换data frame中的数据
i. 将所有为0的数据替换为100
res2$valueX[res2$valueX %in% 0]<-100
ii.将NA替换为0
res2$valueX[is.na(res2$valueX)]<-0
2. CDF line
CDF(累积分布函数)是一个好工具,可以清楚的了解数据的分布情况。
showCDF<-function(data,field){
res_cdf=ecdf(data)
plot(res_cdf,main=paste('CDF of',field))
#显示中位数、上四分位,最大值,以及最大值的2倍(视情况,可以去掉)
summaryData=boxplot.stats(data)$stats
summaryData[6]=summaryData[5]*2
for(index in 3:length(summaryData)){
tempV=as.numeric(summaryData[index])
R_value=floor(res_cdf(tempV)*10000)/100
lines(c(tempV,tempV),c(R_value/100,0),col='red',lwd=2,lty=3)
label=paste('<-',floor(tempV*100)/100,':',R_value,'%',sep='')
text(tempV,index*0.15,label,cex=0.8,adj=c(0,1))
}
}
效果:
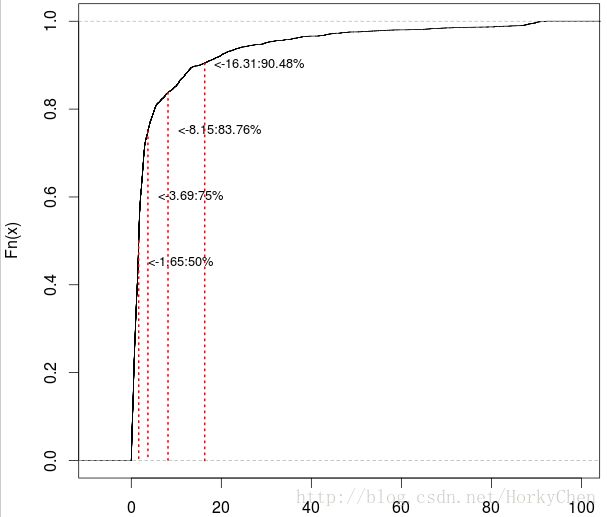
*配合下面的语句可以显示出占具体概率值的分位点, 如:
y<-quantile(data,c(0.5,0.99))
将取出data中占50%及99%的分位点。
3. 从MySQL中读取数据
library('RMySQL')
readDataFromMySQL<-function(tableName,targetDate){
drv<-dbDriver('MySQL')
con<-dbConnect(drv,host='xxx.xxx.xxx.xxx',port=3006,username='xx',password='xxxx',dbname='xxxx')
sqlStatement=paste("select * from ",tableName)
if(nchar(targetDate)>0){
sqlStatement = paste(sqlStatement," where date='",targetDate,"'",sep='')
}
print(sqlStatement)
data=dbGetQuery(con, sqlStatement)
dbDisconnect(con)
return(data)
}
*对于SQLite或其它的Database可以对应变换。
4. 问题求解
对于Header First数据分析中第3章最优化问题的求解, 需要在系统上安装lpsolve包及R的工具包:lpSolve和lpSolveAPI。
library(lpSolve)
f2.obj<-c(5,4)
f2.con<-matrix(c(1,0,0,1,100,125),nrow=3,byrow=T)
f2.dir<-c('<=','<=','<=')
f2.rhs<-c(400,300,50000)
lp('max',f2.obj,f2.con,f2.dir,f2.rhs)$solution
参考:http://lpsolve.sourceforge.net/5.5/R.htm
5. 从命令行执行时获取参数
#main entry
args <- commandArgs(trailingOnly = TRUE)
if(length(args)<1) {
print("Wrong parameters, please specify the target date!",quote = F)
} else {
callProcessFunction(args[1])
}
这样在执行时可以类似如下方式:
Rscript xxx.R 2014-01-13
6. 通过箱形图(BoxPlot)去除异常数据
removeOutData<-function(data){
result = data[!data %in% boxplot.stats(data)$out]
return (result)
}
7.使用字串过滤数据
filterData<-function(data,url){
rows=grep(url,data$url)
return(data[c(rows),])
}
8. 使用ggplot2绘图
ggplot2提供非常强大的功能,如果plot系列需要多次绘制,ggplot2基本可以一句搞定,非常值得学习应用。
放一张在这里供参考:
9. Bars
drawBars<-function(data,xlab) {
labels <- c("A", "B", "C","D")
maxValue=max(max(data$A),max(data$B),max(data$C),max(data$D))
ylim<-c(0,maxValue*1.1)
datax<-rbind(data$A,data$B,data$C,data$D)
barplot(t(datax),beside=TRUE,col=terrain.colors(length(data$t0)),offset=0,names.arg = labels,ylim=ylim,xlab=xlab)
box()
}
效果:
10.分类
dataCluster<-function(data,col,clusterNum) {
require("fpc")
require(cluster)
z2<-na.omit(data[,col])
km <- kmeans(z2, clusterNum)
clusplot(data, km$cluster, color=TRUE, shade=TRUE, labels=2, lines=0)
}
效果:
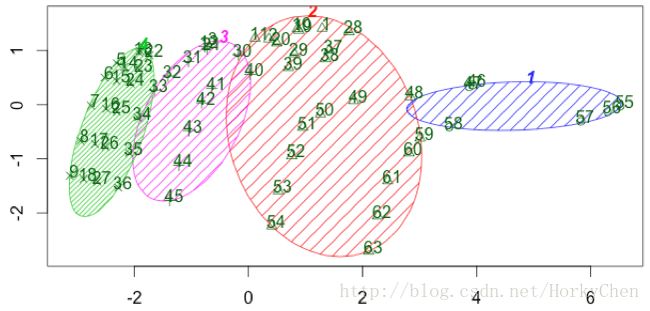
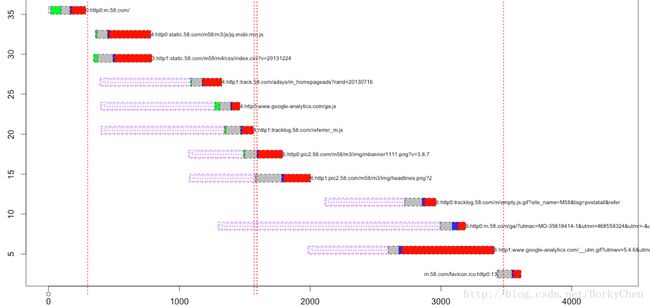
*数据可视化可以帮助分析问题,比如分析加载流程:
11. 将Factor数列转为Numeric
一些从文件加载的frame, 其数列可能是factors, 不能直接转换为numeric, 这时就需要下面的函数了:
asNumeric <- function(x) as.numeric(as.character(x))
factorsNumeric <- function(d) modifyList(d, lapply(d[, sapply(d, is.factor)], asNumeric))
上面的函数使用比较简单:
data.x = asNumeric(data.x)
关键在于要先转为字串,才能转为正确的数字。
*转换前,如果有一些异常值,比如NULL, 记得要用第一条转换一下,或者过滤掉。
如果数据中含有逗号千分位,可以试下这个:
asNumeric2 <- function(x) as.numeric(gsub('![[:alnum:]]*[[:space:]]|[[:punct:]]', '', as.character(x)))
12. 以列的名称进行操作
以字段名的取值会提高应用的灵活性,如下所示:
as.matrix(res[c('data')]) 等价于res$data
这种用法可以解决以列号指定数据时无法应对数据变化的问题。比如:
keys<-c('data_sum','data1','data2')
for(key in keys){
data[c(key)]<-asNumeric(as.matrix(data[c(key)])) #转为数值型
data[c(key)][is.na(data[c(key)]),1]<-0 #将所有NA赋为0
}
13. 观察数据分布类型
datadistribution<-function(x,na.omit=F){
if(na.omit){
x<-x[!is.na(x)]
}
m<-mean(x)
n<-length(x)
s<-sd(x)
skew<-sum((x-m)^3/s^3)/n
kurt<-sum((x-m)^4/s^4)/n-3
return(c(n=n,mean=m,stdev=s,skew=skew,kurtosis=kurt))
}sapply(base_data[c('a','b')],datadistribution)
14. 分组计数
使用aggregate函数可以出色地完成一些分组统计的工作,可惜无法直接使用length。下面是通过自定义一个函数来实现只对唯一值计数。
fun<-function(x){return(length(unique(x)))}
res<-aggregate(values~groupby,data=data, FUN=fun)
另一个比较好用的是plyr工具包的summarise函数:
library(plyr)
sdata<-ddply(data,c('field2'),summarise,N=length(rt),mean=mean(rt),sd=sd(rt),se=sd/sqrt(N))
print('Result of ddply function:')
print(sdata)15. 字串操作
R中的字串操作常常是使用正则表达式完成。 去除字串首尾的空格: trim <- function (x) gsub("^\\s+|\\s+$", "", x)
下面是使用grep查找字串和分隔字串的示例:
strVal<-trim(temp[j])
if(length(grep('^max-age',strVal))>0){
values<-strsplit(strVal,'=')
data$cache_max_age[i]<-as.numeric(values[[1]][2])
}