分布式系统迁移Docker云案例分享
前言
“只要站在风口,猪也能飞起来”,这碗心灵鸡汤不知道激励了多少英雄豪杰踏上寻风口之路。而现如今,Docker这阵龙卷风呼啸来袭,更让众人生起迎风而上、直冲云霄的欲望。为了找到这风口,腾讯数据平台部开始全面拥抱Docker,基于多年的大数据集群管理经验,倾力打造DockerOnGaia云平台(简称Gaia云),并动员将数平自身的核心系统全面接入Gaia云。
Lhotse系统作为先锋部队,经过一段时间的改造-验证-灰度,目前现网已经完全接入、稳定运营。本文旨在分享Lhotse接入Gaia云的一些实践经验,抛砖引玉,期待更多的系统加入队伍,一起在Docker云中探索前行。
背景介绍
Lhotse是一个大数据任务调度系统,从架构上看是典型的Master-Agent分布式架构,如下图所示,作为调度核心的Base统筹分配任务,交由对应类型的Runner执行:
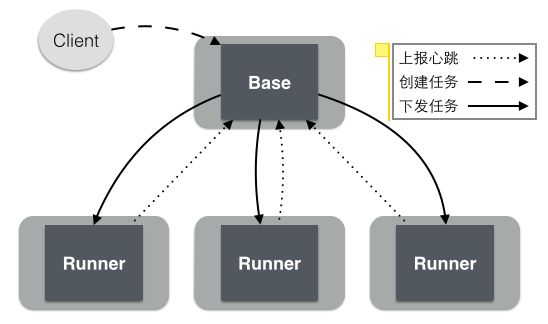
到目前为止,Lhotse线上支持68种Runner,分别对应68种不同的任务类型,集群总机器数将近200台。面对这种复杂多样的系统环境,Lhotse接入Gaia云的核心诉求是自动化,通过自动化来降低系统管理复杂度、提高运维效率。自动化运维可以总结为两点:
机器操作取代人工操作——将复杂枯燥的工作(比如资源分配、程序部署)交给云平台处理。
通用实现取代重复实现——云平台将一些通用性的基础工作(比如进程监控、自动拉起)抽象成标准化服务,不必重复造轮子。
除了自动化之外,Gaia云带来的另一个核心点是透明化。它在应用的不同阶段有不同的含义:
在应用部署阶段,指的是机器集群的透明化。集群规模、机器分布、机器规格等因素对用户来说都是透明的,成群的服务器被Gaia封装成了一台超级计算机。
在应用运行阶段,指的是实例状态/资源使用/历史事件/系统日志的透明化。通过Gaia封装的API或者web portal,应用的一切运行动态尽在掌握,透明公开。
下面我们将分别从部署、调度、容错、灰度升级、扩缩容及服务发现六个纬度,来讨论Gaia云如何为Lhotse带来自动化与透明化。
部署
Lhotse部署遇到的最大难点在于,每个类型的Runner所依赖的运行环境都有差异。例如,Pig Runner需要机器上预装PigClient、Hadoop,而Compute Runner需要预装PLC。极端的情况是,68种Runner对应68种不同的运行环境,要在200台机器里交叉部署,并且保证各个运行环境完整一致、相互不受影响,这对运维来说是极大的挑战。
对症下药,Gaia云给我们开出Docker这一药方,带来了如下功效:
环境一致:将软件运行环境(包括程序包、软件依赖、配置文件等)镜像化后,无论在哪台机器运行,只要镜像相同,容器启动后的运行环境总是一致的。
环境隔离:在同一台机器运行的多个容器,其运行环境(比如,软件版本与配置)相互隔离、不受干扰。
版本管理:每次软件升级可重新构建镜像,通过镜像tag来管理标注不同的版本,方便灰度、回滚。
快速部署:将软件部署到新的机器,仅需获取镜像这一步操作,无需拷贝、安装、配置等一系列过程。
现在,Lhotse的部署流程已经完全Docker化:我们将每个Base/Runner及其运行环境build成一个Docker镜像,push到Gaia云的Registry;每次启动Base/Runner容器时,Gaia自动从Registry pull最新的镜像。整个部署过程如下图所示:
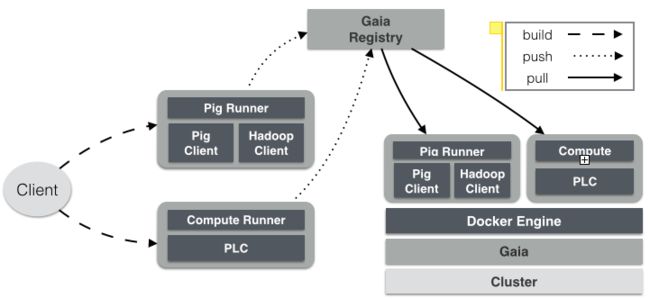
调度
有了自动化部署,我们可以方便地将Base/Runner发布到集群的任意机器。但接下来的问题是,选择哪台机器在什么时候运行哪个程序——这是调度要解决的问题。
以前,Lhotse集群的调度都是人工静态处理,资源分配粒度只能到机器级别。这导致调度工作量大,资源利用率却不高。如下两图分别展示了各个Runner机器的CPU与内存利用率(横坐标表示Runner类型编号,纵坐标表示利用率数值):
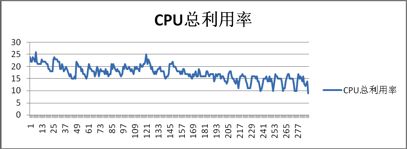
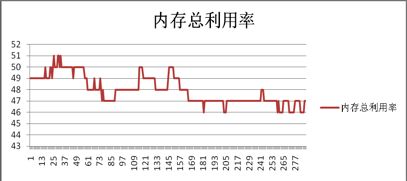
现在,得益于Gaia云强大的调度能力,Lhotse已经告别了人工资源分配的时代,完全实现调度的自动化。Gaia的调度能力主要体现在两个方面:
资源分配粒度精细到CPU与内存级别。Lhotse可以根据每个Runner的资源需求来设定具体的CPU个数、内存值。目前,Gaia正在规划支持磁盘、网络带宽等其他资源,实现更精细化的调度。
集群公平地与其他租户共享(租户可以是不同的系统,也可以是同一个系统内的不同模块)。目前,Lhotse与Hermes系统共享集群,如下图所示,在Gaia中通过树形队列来抽象租户层次:Lhotse与Hermes作为顶级租户,根据它们不同的资源需求(Lhotse偏向CPU密集,Hermes偏向memory密集)按比例瓜分集群资源。在Lhotse租户内部,Base租户与Runner租户根据同样的调配逻辑来瓜分Lhotse的资源。这种层级化的多租户资源调配,既实现了资源的最大化利用,也保证了资源共享的公平性、可控性。

容错
如前文所言,Lhotse的Runner多达68种,任何一个Runner出错,都有可能影响大批的调度任务。因此,对于每个Runner的监控及出错处理至关重要。
以前,Lhotse通过自定义脚本来监控Runner进程,在发现错误的情况下自动重启或拉起。这种方式存在两点弊端:一是监控脚本本身也需要维护;二是只能做本机重启,无法跨机重试,对于机器挂掉的情况无能为力。
现在,借助Gaia云的自动容错机制,Lhotse从单机容错上升为集群容错,主要体现在两个层面:
自动重试,包括本地重试和跨机重试。Gaia云对于机器宕机、进程异常退出、OutOfMemory等异常都可以做到自动重试告警,且重试次数可以自行设定,本地重试优先于跨机重试。对于有本地上下文信息的Runner,可以设定较高的本地重试次数,以尽量保证效率。
自动屏蔽,即黑名单机制。当机器失败达到预设的次数,将被推上黑名单,在一定的时间内对调度屏蔽,以尽量降低出错的影响,且对业务来说是透明的。
灰度升级
为了保证任务高并发和系统高可用,Lhotse每个Base/Runner应用需要运行多个实例,在Gaia云中分别由Applicaiton和Instance来抽象:向Gaia提交Application时,可以指定Docker镜像、Instance个数以及其他相关配置,如下图表示了一个Runner应用的部署抽象:

在这种部署/运行模型下,对应用做灰度升级非常方便,只需选择新版本的Docker镜像,reload待升级的Instance:
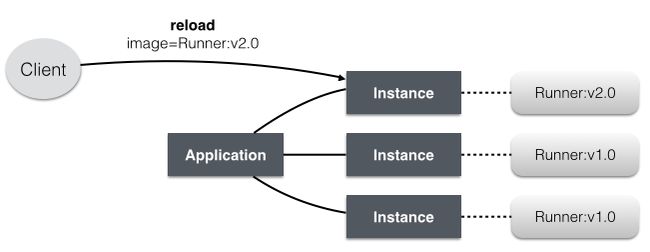
既然可以将v1.0的实例reload成v2.0,当然也可以将v2.0的实例reload成v1.0。前者是升级,后者是回退。得益于Docker的镜像管理特性,应用在Gaia云中的升级与回退本质上是同类的操作。
扩缩容
按需弹性分配资源是云计算的核心理念,扩缩容自然成为云平台的标配特性之一。在Gaia云中,扩缩容一个应用非常方便,只需选择相应的Docker镜像与实例个数,rampup待扩缩容的Application:
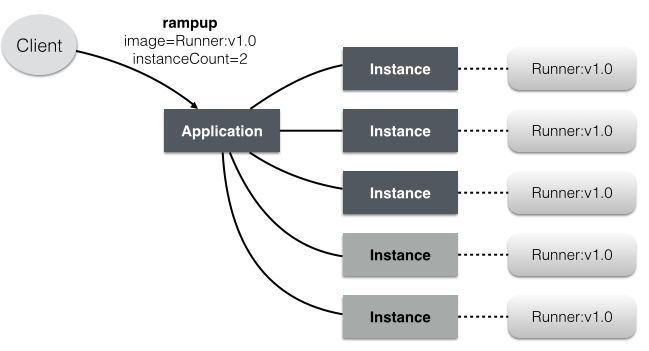
在实际运维中,Lhotse已经多次通过Gaia来扩容Runner,得益于Docker带来的快速部署/启动能力,可以轻松实现秒级扩容。
目前,尽管扩缩容过程是自动化执行的,但操作还需要人工进行触发。实际上,作为一个任务调度系统,Lhotse任务负载的时间分布实际上是有规律、可预估的(通过监控数据发现,有相当一部分Runner的任务负载都在某种程度上遵循着二八定律,即有20%的时间处于高峰期,承受成倍于其他时间的负载)。下面两图分别展示了两种Runner连续三天的任务负载分布,可以看到,负载高峰通常是在凌晨某个时段。


因此,Lhotse扩缩容是可以基于时间/负载等因素来自动触发的。Gaia云根据业务系统的需求,正在规划自动扩缩容的方案,后续Lhotse将保持跟进,第一时间验证测试。
服务发现
从前文的架构图上可以看到,Lhotse内部最基本的通讯路径是——Runner向Base上报心跳。在静态分配资源时代,Runner通过配置文件写死IP来发现Base。这种方式在动态分配资源的Gaia云中显然是不可行的,需要新的服务发现机制。它要满足两个需求:
自动注册/更新地址——当服务实例发生迁移或者新的服务实例部署时,需要对地址列表做自动更新。
自动负载均衡——当有服务有多个实例时,需要自动将访问请求分配到某一个实例。
Gaia云为此采纳了基于“Etcd-Confd-HAProxy”的服务发现架构:Etcd作为服务地址的存储中心,HAProxy作为服务访问的代理(负载均衡)中心,Confd则是连接前两者的纽带,实现地址列表的自动更新(具体实现可以参考《构建一个高可用及自动发现的Docker基础架构-HECD》)。基于这种服务发现机制,Runner发现Base的过程如下图所示:

总结
本文分享了Lhotse系统接入Gaia云,实现自动化运维的实践经验: 通过部署、调度、扩缩容自动化,释放了人工运维的压力;通过容错、灰度升级、服务发现自动化,避免了重复造轮子。
当然,天下没有免费的午餐,要享受Gaia云带来的自动化,对于老的系统可能会有一定的改造成本。比如,Lhotse在迁移过程中对代码做了全面梳理,把所有写死IP的代码做了改造。不过,Lhotse的经验表明,这样的系统改造基本不涉及关键模块(比如数据存储、组件通讯、任务执行等),工作量相对不大。另外值得一提的是,在接入过程中,Gaia云根据业务系统的特点不断地演进平台特性,尽可能地降低老系统的迁移成本。
作为第一个抵达风口的“猪”,Lhotse乘风而起,扶摇直上云端里,吹响了全民拥抱Docker云的号角,并且会继续探索前行,为大部队点灯开道。与此同时,我们也期望Gaia云持续优化完善,提供舒适的云环境,让我们沉浸其中、欲罢不能。