使用神奇的xor(异或)解决Storm的Tuple确认问题
日光之下,并无新事” —《旧约 传道书》
Storm作为一个高性能的实时流式数据处理框架,非常优秀,虽然它大多数方面比不上Flink(我没有亲自试,我也是听人说的,但这个人我信任),但我个人而言还是很喜欢它而不是Flink。本文介绍Storm的Tuple确认机制。
由于本文是一篇随笔而不是一篇教程,所以我不会从头介绍什么是Storm,更不会介绍Storm的安装使用方法,本文的内容仅仅包括“经由Storm的诸多bolt处理后的消息如何向spout进行确认”。
为了简单起见,本文假设所有的bolt处理都是成功的,即它在向下游拓扑emit某个或者某些绑定与某Tuple的msg之后,只无条件调用了ack方法而没有调用fail。在介绍之前,先看看几个显而易见的事实。
Storm spout的nextTuple以及bolt的execute
Storm的API非常丰富,但是记住,本文介绍的ACK机制需要特殊的支持。也就是说,本文所说的ACK的机制只是Storm的一种可选机制,你完全可以无视它去选择一种轻量的无确认的Best effort方式去使用Storm,本文之所以单独介绍ACK机制,是因为其优雅。
在编写spout的nextTuple时,最终你必须要emit一个Tuple,记住,要这么做:
this.collector.emit(new Values(...), msgID);一定要有msgID这个参数,一定要有!否则Storm便不会跟踪这个Tuple。这句话的意思是在Storm执行完spout的emit之后,会在系统内部创建一个类似下面的映射:
msgID-Tuple:ACKvalue
其ACKvalue的初始值为一个随机的数字,该数字由spout为该被emit的msg生成,显然,如果spout一次emit了多个msg,那么该ACKvalue便是所有这些数值的异或的结果。这个后面会详述。
此外,在后续的bolt的execute方法中emit新的msg时,记住,一定要携带tuple参数,不然后续的拓扑便会丢失针对该tuple的追踪,要写成:
collector.emit(tuple, new Values(...)); 而不是:
collector.emit(new Values(...));当然如果你想故意不再跟踪某个Tuple在后续拓扑中的结果(比如你只是希望保证特定几个步骤的执行成功),你完全可以在特定的bolt的execute的emit方法中不再携带tuple参数,一切由你决定。
ACK原理进化脉络
如果发送者发出一个消息,希望确认接收者是否收到,最简单的方案就是下面的了:

这里能说很多很多,比如TCP就是这么实现的,TCP这种老掉牙的东西真的不想在多说,所以一句话总结吧,这种方式是采用了带内ACK的方法进行可靠性保证的。推广到接力流水线的方式,就变成了下面的样子:
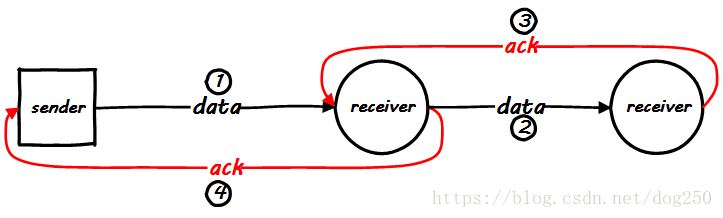
但是,想想这有什么问题。
中间节点的压力大吗?要知道,即便是TCP也不是这样运作的。TCP是一个端到端协议,只是进行端到端确认,而Storm显然并没有进行分层设计,显然在应用层,这样进行中继确认的方式并不合适。于是乎,我们也选择一种端到端的方案看看如何:

看起来不错的样子,但是可以更进一步。因为应用层的逻辑往往没有底层那么固定,业务逻辑复杂多变的情况下,尽量用中间件来进行解耦,即避免receiver和sender之间的直接交流。因此,我们显然换成了一种带外ACK的方式进行确认:

好了,现在的数据通路被清理的干干净净,确认通过一个叫做Acker的中间服务进行协助,这个Acker中间服务可以是个集群,是多个。带内数据和带外确认完全分开,提高了系统的健壮性,结构非常清晰。
可是这样完美吗?
要知道,Storm的拓扑最终是一个有向无环图,显然不是一条直线啊。一个bolt经过处理,可能会分出多个msg发往多个bolt,同时,一个bolt也可以接收来自多个bolt的多个Tuple,比如多路日志的合并就经常面临这个局面。典型的场景就是下面的图示所示:

这可怎么办?
其实也简单,只要能追踪每一个bolt发射的msg属于哪个Tuple,就能定位到到达最终叶子节点的msg属于哪个Tuple,然后想办法把处理的结果告诉spout,当然,显而易见的办法就是还通过Acker来转交:

办法是显而易见且通用的,但是问题也已经写在了图中。要解决这个问题,需要复杂的数据结构和复杂的维护设施。Storm使用了一种极其巧妙的方法解决了这个问题。
Storm之ACK实现
Storm采用了非常简单的XOR来解决这个问题。
如果上游bolt在emit一个msg的时候,如何确认下游的bolt会收到呢?其实这是一个循环问题。其实根本就不用下游bolt显式告诉上游我收到了,而是采用下面的手段即可:

bolt1在发出一个msg的时候,会将一个随机生成的ID报告给Acker,并将此ID携带到msg中向下游传递,一旦bolt2收到了一个属于同一个Tuple的msg,它便会将解析出来的ID也传递给Acker,不出意外,二者XOR的结果将会是0!
这就是原理。下面我们看一下更一般的图示:
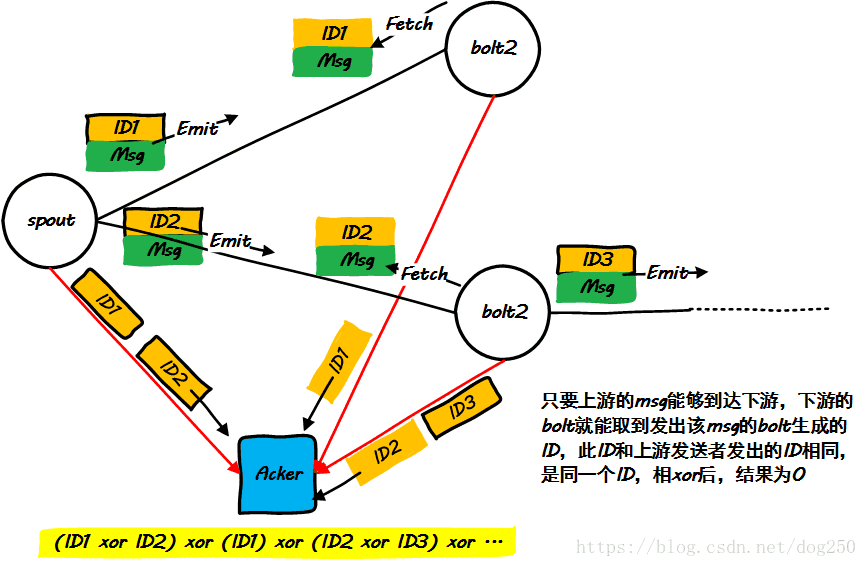
Acker要做的仅仅是搜集所有bolt报告给它的其接收到的ID和发出的ID,然后进行XOR运算。当然了,在bolt在ack方法调用中往Acker发送ID的时候,其会携带Tuple信息,Acker会根据这个Tuple对应到内存中其保存的表项。上面的例子,按照这种方式运作,便是:

最后,给出一个一般化的流程:

如果有哪一步错误没有使得msg正确传递到叶子终点,显然Acker不会收到能使XOR结果为0的ID,进而最终spout会超时重发msg。但是…
但是更容易出现的问题是,你忘了调用ack方法!不是出错了导致ID没有报道,而是你根本就忘了上报!这会导致该轮msg处理失败,但这不是最严重的后果,最严重的显然是OOM,即OutOfMemoryError…
神奇的XOR
很多人都知道xor的概念以及如何操作,但是很少有人真正理解它。
很少有人理解XOR的理由很简单,不是因为它很难,而是因为中文对XOR的翻译没有做到信达雅中的达。
什么是XOR,中文解释是异或,也许是计算机专业学生普遍是古文学的不好,其实“异”这个词本身就有排他的含义,如果不理解这个,就很难直接掌握XOR的本质!
XOR的本质含义就是“exclusive or”,你要么是A,要么是B,不能既是A又是B。用韦恩图解释要简单的多:

简单做个实验,把B盖上去,即计算一下A xor B xor B的值,按照概念,即互斥的概念,下图就是答案:
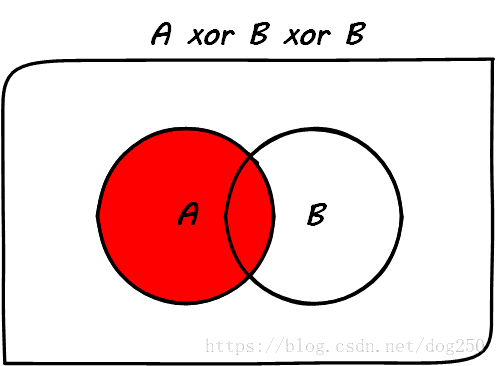
像不像日全食呢?这就是日全食的道理。通过这个盖盖子的例子,你是不是理解了为了仅仅通过xor操作就可以做到两个数字交换了呢?
如果我们不去盖上一个B,而是盖上一个C呢?三者互斥相或,即:

找到规律了吗?不管是用哪个集合往上面盖,重合的部分会被反色,盖一次就反一次,按照这个,你会发现XOR完全符合结合律以及交换率,顺便你还能发现它就是一个群…
由于交换律的存在,Storm里面哪个bolt先调用ack无所谓。只要Acker发现ACKvalue变成了0,就会上报spout对应的msg成功处理完毕,最终结局:

利用上面的描述,是不是对xor理解更深刻呢?
Storm
没有意义,哪里是出路…当我漫步畅想房子的后面是另一个广阔世界的时候,不知不觉就到了路的尽头,抬头一看,这原来是我熟悉的地方。