Kmeans聚类-matlab实现
数据集来自周志华《机器学习》202页西瓜数据集。
算法初始随机选取的三个样本,按照书上选的运行测试代码,可根据需求对代码进行改写,详细过程如下:
1、data.txt 数据集
0.697 0.460
0.774,0.376
0.634,0.264
0.608,0.318
0.556,0.215
0.403,0.237
0.481,0.149
0.437,0.211
0.666,0.091
0.243,0.267
0.245,0.057
0.343,0.099
0.639 0.161
0.657,0.198
0.360,0.370
0.593,0.042
0.719,0.103
0.359,0.188
0.339,0.241
0.282,0.257
0.748,0.232
0.714,0.346
0.483,0.312
0.478,0.437
0.525,0.369
0.751,0.489
0.532,0.472
0.473,0.376
0.725,0.445
0.446,0.459
2、Kmeans 实现
clc,clear;
%load data
data = load('E:\Matlabwork\image_processing\Clustering_Practice\data.txt');
k = 3; %Number of Clustering
%randomly select k samples as the initial mean vector
[M ,N] = size(data);
t = randperm(size(data,1));
% for i = 1:k
% u(i,:) = data(t(i),:);
% end
u = [0.403,0.237;0.343,0.099;0.478,0.437];
u1 = zeros(k,N);
n = 1;
while 1
C = cell(3,1);
for j = 1:M
%compute the distance between xj and ui
for i = 1:k
d(i) = norm(data(j,:)-u(i,:));
end
[~,D] = min(d);
C{D,:} = [C{D,:};data(j,:)];
end
for j = 1:k
u1(j,:) = sum(C{j,1})/length(C{j,1});
end
figure(n)
plot(u1(:,1),u1(:,2),'k+');
hold on;
plot(C{1,1}(:,1),C{1,1}(:,2),'r+');
plot(C{2,1}(:,1),C{2,1}(:,2),'g+');
plot(C{3,1}(:,1),C{3,1}(:,2),'c+');
xlabel('密度');% x轴名称
ylabel('含糖率');
%set(gca,'XTick',[0:0.1:0.8]);
axis([0.1,0.9,0,0.8]);
n = n+1;
if norm(u - u1)<0.01
break;
end
u = u1;
end
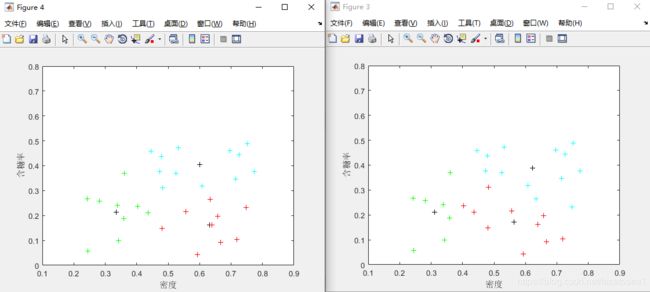
3、运行结果
经过第一次、第二次迭代后,结果如下图所示(其中黑色+代表当前簇心,除此之外,相同颜色的+属于同一簇。):
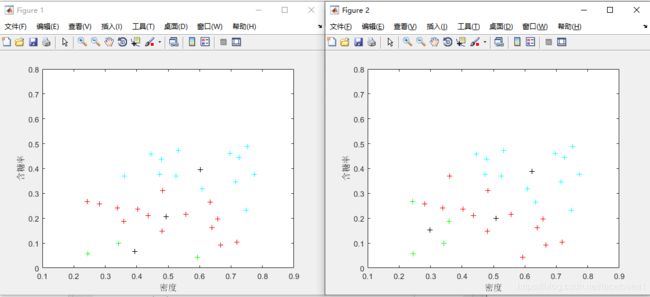
经过第三次、第四次迭代后,结果如下图所示: