推荐系统:矩阵分解(Matrix factorization)
目录
一、问题描述
二、算法概述
(一)BasicSVD
(二)FunkSVD
(三)Baseline estimates & Matrix factorization
(四)Asymmetric-SVD
(五)SVD++
三、总结
一、问题描述
给定用户 - 物品评分矩阵(下文简称评分矩阵)![]() 如下表所示:
如下表所示:
| u/i | 1 | 2 | 3 | 4 | ... |
|---|---|---|---|---|---|
| 1 | 4 | 5 | ... | ||
| 2 | 3 | ... | |||
| 3 | 2 | 4 | ... | ||
| 4 | 1 | ... | |||
| ... | ... | ... | ... | ... | ... |
这是一个极其稀疏的矩阵,表格中的空白项表示用户未进行评分,我们的任务就是对空白项进行评分预测。
二、算法概述
矩阵分解算法由奇异值分解算法(Singular Value Decomposition, SVD)演变而来,传统的奇异值分解算法只能对数据稠密的矩阵进行分解,而评分矩阵是极度稀疏的,因此,若要使用SVD对评分矩阵进行分解,首先要对矩阵的缺失值进行填充,这样便造成了以下两个问题:
- 填充缺失数据会极大的增加数据量,导致算法复杂度上升。
- 填充方法不当会导致数据失真。
由于SVD算法在评分矩阵中不能发挥良好的作用,人们转而研究是否能只考虑已有评分对矩阵进行分解,于是便有了BasicSVD、FunkSVD、SVD++等矩阵分解方法。
(一)BasicSVD
BasicSVD是最简单的矩阵分解方法,它将评分矩阵分解为两个低阶矩阵,分别代表用户的隐含特征和物品的隐含特征,如下所示:
![]()
u 为用户数,i 为物品数,k 为隐含特征数。通过最小化误差平方和(SSE)得到隐含特征矩阵 p、q,进而通过隐含特征矩阵进行评分预测。
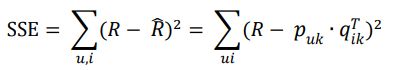
优化目标为最小化SSE,参数为矩阵p、q:
![]()
(二)FunkSVD
FunkSVD(又称RSVD,正则化SVD)在BasicSVD的基础上添加了正则化项,防止过拟合。优化目标为最小化SSE和正则化项之和,参数为矩阵p、q:
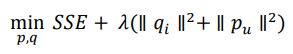
(三)Baseline estimates & Matrix factorization
Baseline estimates是一种考虑用户评分倾向和物品评分倾向的方法,用户 u 对物品 i 的预测评分表示如下:
![]()
其中,![]() 表示用户 u 对物品 i 的评分预测值,μ 表示已有评分数据的总体平均值,
表示用户 u 对物品 i 的评分预测值,μ 表示已有评分数据的总体平均值,![]() 代表用户的评分倾向(偏好),
代表用户的评分倾向(偏好),![]() 表示物品的评分倾向(偏好)。
表示物品的评分倾向(偏好)。
例如预测用户 u 对物品 i 的评分,假设当前已有评分数据的总体平均值为3.5。一方面,u 是一个严苛的用户,他倾向于低于平均值0.3的评分,另一方面,i 是一个热门的物品,它的评分基本高于平均水平0.5分。因此,用户 u 对物品 i 的预测评分为:3.5 - 0.3 + 0.5 = 3.7。
优化目标为最小化SSE,参数为向量![]() 和
和![]() ,表示如下:
,表示如下:

FunkSVD结合Baseline estimates方法,在用户历史评分的基础上加入对用户、物品偏好的考虑,提高模型预测的精度,此种方法中用户 u 对物品 i 的预测评分表示为:
![]()
优化目标为最小化SSE,参数为向量![]() 、
、![]() 和矩阵 p 、q,表示如下:
和矩阵 p 、q,表示如下:

(四)Asymmetric-SVD
Asymmetric-SVD(非对称SVD)是对Baseline estimates的改进,该方法引入了用户显式反馈和隐式反馈对预测的影响。在评分数据集中,用户的评分值代表了用户的显式反馈,而用户评分和未评分的操作代表了用户的隐式反馈。Asymmetric-SVD方法将用户的潜在特征替换为用户对感兴趣的物品的显式和隐式反馈,预测评分表示如下:

其中![]() 为用户 u 的显式反馈(评分)集合,
为用户 u 的显式反馈(评分)集合,![]() 为显式反馈物品的权重(相关性),比如预测用户对物品 i 的评分,而用户对物品 i 的相关物品 j 的评分较高,那么认为用户对 i 的评分也会比较高,这种方式不会因为考虑物品 j 而导致误差增大,因为当物品i、j 较为相似时,
为显式反馈物品的权重(相关性),比如预测用户对物品 i 的评分,而用户对物品 i 的相关物品 j 的评分较高,那么认为用户对 i 的评分也会比较高,这种方式不会因为考虑物品 j 而导致误差增大,因为当物品i、j 较为相似时,![]() 接近于0,i 和 j 不相似时,
接近于0,i 和 j 不相似时,![]() 接近于0,这样就惩罚了其他预测不准确的情况。
接近于0,这样就惩罚了其他预测不准确的情况。
N(u)为用户u的隐式反馈集合,y为隐式反馈物品的权重,u 对 j 的隐式偏好将通过 y 反应到对 i 的预测中,如果 j 可以预测 i,那么 y 将较大(可通过0或1表示)。
这种方法的用意是:用户的兴趣不仅和评分物品有关,而且和未评分物品有关。
优化目标为最小化SSE,参数为向量![]() 、
、![]() 和矩阵q、x、y,表示如下:
和矩阵q、x、y,表示如下:
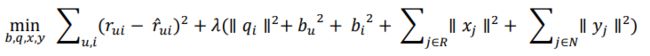
(五)SVD++
SVD++是对Asymmetric-SVD的改进,进一步简化了Asymmetric-SVD方法,更加直观、高效,预测评分表达为:
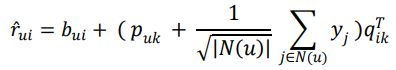
优化目标为最小化SSE,参数为向量![]() 、
、![]() 和矩阵 p、q、y,表示如下:
和矩阵 p、q、y,表示如下:
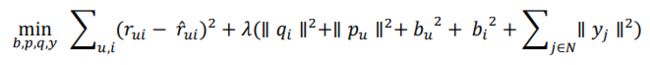
三、总结
矩阵分解是协同过滤算法中应用十分广泛的算法之一,适合用于评分预测推荐领域,这种通过机器学习方法进行评分推荐的算法能够在海量数据中挖掘出用户和物品的潜在特征,是协同过滤推荐算法的热门研究方向。
在设计实验时,矩阵分解算法通常会采用随机梯度下降法来训练模型,需要将损失函数对各个参数求偏导得到参数的更新式,迭代更新参数,直到算法收敛。