源码编译torch
最近在研究pytorch,但是呢,在安装的时候遇到不少麻烦,特此坐下记录。
在ubantu16.04下安装pytorch和Torchvision(conda,pip 均失败后采用源码安装)
因为网络原因(墙),用官网的安装办法根本无法安装pytorch,无奈去github看到了源码安装。话不多说,开始安装吧
解决方法----源码编译
源码包在github上的托管地址为
https://github.com/pytorch/vision
https://github.com/pytorch/pytorch
安装步骤:
安装pytorch
1.git clone --recursive https://github.com/pytorch/pytorch
2.cd pytorch
3.python setup.py install
安装torchvision
1.1.git clone --recursive https://github.com/pytorch/vision
2.cd vision
3.python setup.py install
装完后验证:
各位,爱折腾的我又来啦!这次我准备搞点不一样的,在Windows搞定PyTorch的编译。
首先,我先简要介绍一下PyTorch吧。PyTorch是Facebook开发维护的一个符号运算库,可用于搭建动态的神经网络。它的代码简洁,优美,也具有很强的性能。举个例子,如果我们要在Theano或者TensorFlow下进行向量的运算,我们会先定义一个tensor,再对tensor做计算,然后定义一个function,最后调用函数并传入参数,获得输出。样例代码:
import theano
import theano.tensor as T
x = T.dmatrix('x')
s = 1 / (1 + T.exp(-x))
logistic = function([x], s)
logistic([[0, 1], [-1, -2]])如果我们使用PyTorch呢,我们这样写
import torch
x = torch.FloatTensor([[0, 1], [-1, -2]])
s = 1 / (1 + torch.exp(-x))只需要定义变量,即可进行运算。是不是更加符合我们的思维呢?
最后我再引用一句话来宣传一波:
Matlab is so 2012.
Caffe is so 2013.
Theano is so 2014.
Torch is so 2015.
TensorFlow is so 2016. :D –Andrej Karpathy
It’s 2017 now.
让我们步入正题,看看如何在Windows下安装PyTorch。
先做一个友情提醒,如果不想折腾的话,对于Windows 10 用户,可以在WSL下进行体验,缺点是不能使用GPU进行计算的加速。或者你也可以等待官方放出正式的安装包。下面的安装过程是测试,不保证能够安装成功。
首先我们可以找到官方repo的相关issue。其中有一位大神已经为我们做好了大量的工作,他将他的代码存放在这里。当然你也可以直接使用我最终修改后的代码,就在他的基础上做了一点工作,不过我的代码通过了所有的CUDA单元测试,他的还没有。
首先,我们需要准备好安装所需要的工具,包括:
- Visual Studio 2015 with Update 1及以上(不能是2013,2017,原因我下面会解释)
- CMake
- 一种BLAS运算库,比如Openblas或者Intel MKL
- PyTorch的源码,从上面的地址获取
- CUDA 7.5及以上
- CUDNN 5.1.10及以上
- Anaconda3 (Python版本3.5及以上)
安装步骤大致如下:
- 安装VS,CUDA,cuDNN, CMake,Anaconda。这没什么好多说的,至于为什么一定要VS 2015 Update 1及以上,其实这是我踩坑之后得到的宝贵经验。VS 2013对C99标准的支持比较弱, VS 2017 尚且不支持作为CUDA 8.0的编译器,而原生的VS 2015 会报一个莫名其妙的链接错误。选取Anaconda3的原因也是为了兼容C99。
- 添加环境变量,添加CMake和MSBuild的路径至PATH中。他们大概在这样的路径下:
C:\Program Files\CMake\bin
C:\Program Files (x86)\MSBuild\14.0\Bin\amd64- 定位到pytorch代码目录的torch\lib下面,我们新建一个目录tmp_install,在这个目录下面再新建一个目录lib,然后将blas相关的lib统统丢进去。然后对build_all.bat进行修改,定位到结尾,可以发现这样一段代码
cmake ../../%~1 -G "Visual Studio 14 2015 Win64" ^
-DCMAKE_MODULE_PATH=%BASE_DIR%/cmake/FindCUDA ^
-DTorch_FOUND="1" ^
-DCMAKE_INSTALL_PREFIX="%INSTALL_DIR%" ^
-DCMAKE_C_FLAGS="%C_FLAGS%" ^
-DCMAKE_SHARED_LINKER_FLAGS="%LINK_FLAGS%" ^
-DCMAKE_CXX_FLAGS="%C_FLAGS% %CPP_FLAGS%" ^
-DCUDA_NVCC_FLAGS="%BASIC_CUDA_FLAGS%" ^
-DTH_INCLUDE_PATH="%INSTALL_DIR%/include" ^
-DTH_LIB_PATH="%INSTALL_DIR%/lib" ^
-DTH_LIBRARIES="%INSTALL_DIR%/lib/TH.lib" ^
-DTHS_LIBRARIES="%INSTALL_DIR%/lib/THS.lib" ^
-DTHC_LIBRARIES="%INSTALL_DIR%/lib/THC.lib" ^
-DTHCS_LIBRARIES="%INSTALL_DIR%/lib/THCS.lib" ^
-DTH_SO_VERSION=1 ^
-DTHC_SO_VERSION=1 ^
-DTHNN_SO_VERSION=1 ^
-DTHCUNN_SO_VERSION=1 ^
-DCMAKE_BUILD_TYPE=Release ^
-DLAPACK_LIBRARIES="%INSTALL_DIR%/lib/mkl_rt.lib" -DLAPACK_FOUND=TRUE可以将最后一行进行适当的修改,如使用OpenBlas可将其改为openblas.lib;如不打算使用blas,则将最后一行去掉。
4. 打开一个CMD窗口,定位到pytorch代码根目录下,然后执行以下代码:
cd torch\lib
build_all.bat --with-cuda然后大家就可以喝喝茶,看看电影,度过这个漫长的编译时间。
5. 检查一下torch\lib下是否包含THPP.dll,如果没有的话,说明编译失败了。看看之前的输出,想想问题大概出在哪里。
6. 如果顺利的话,我们再键入最后两行命令。
cd ..\..
python setup.py install- 如果没有报错的话,恭喜你,安装成功了。不过,还需要一些小小的操作。我们先找到cudart和cudnn模块,他们一般在这个位置:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin\cudart64_80.dll
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin\cudnn64_6.dll
# 如果使用cudnn v5,那么就是
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin\cudnn64_5.dll- 将他们拷贝至Anaconda3的Lib\site-packages\torch\lib下面
- 如果你使用的是cudnn v5的话,打开Anaconda3的Lib\site-packages\torch\backends\cudnn下面的__init__.py。将_libcudnn函数修改为:
def _libcudnn():
global lib, __cudnn_version
if lib is None:
lib = ctypes.cdll.LoadLibrary("cudnn64_5")
if hasattr(lib, 'cudnnGetErrorString'):
lib.cudnnGetErrorString.restype = ctypes.c_char_p
__cudnn_version = lib.cudnnGetVersion()
else:
lib = None
return lib就这样,我们就完成了PyTorch在64位Windows下的安装。我们可以跑一下MNIST来测试一下:
from __future__ import print_function
import argparse
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torch.backends import cudnn
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10000, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
print('Using CUDA:' + str(args.cuda))
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
model = Net()
if args.cuda:
model.cuda()
# cudnn.enabled = False
cudnn.benchmark = True
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
train_dataset = datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_dataset = datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=args.batch_size, shuffle=True, **kwargs)
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.momentum)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx *
len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data[0]))
def test(epoch):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).data[0]
# get the index of the max log-probability
pred = output.data.max(1)[1]
correct += pred.eq(target.data).cpu().sum()
test_loss = test_loss
# loss function already averages over batch size
test_loss /= len(test_loader)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)为啥一定要在外层用主模块判断呢?其实是因为现在PyTorch在Windows下的Multi Processing库还存在一些问题,在DataLoader加载时,会用另外一个线程重新打开该文件,造成冲突。其他基本上没有太大的问题,可以正常使用。MNIST的运行实测如下图,跑的还是挺快的。
以上,就是文章的全部内容啦,如果感觉还意犹未尽的话,可以给我的Github 主页或者项目加个watch或者star之类的(滑稽),以后说不定还会再分享一些相关的经验。
经过几个月的努力,随着11月8号PR 2941并入PyTorch之后,我们终于将关于Windows支持的相关PR全部并入了PyTorch的master分支,现在你可以直接对master分支进行编译了。编译需要的组件有:
CPU版本:
- Visual Studio 2017 C++ Build Tools
- CMake 3.0 及以上
- 64位Windows系统
- 64位Anaconda/Miniconda 或者 Python 3.5及以上
GPU版本:
- CUDA 8.0 及以上
- NVTX (在 CUDA 中为VS的插件,若安装失败,可以解压CUDA安装包,在CUDAVisualStudioIntegration中找到)
- 对于CUDA 8 的编译还需要Visual Studio 2015 with Update 2 及以上
可选项:
- cuDNN 6.0 及以上
- BLAS 运算库 (主要是OpenBLAS和MKL)
更新:已添加一个repo用于一键进行编译安装,欢迎体验使用。
编译步骤如下:
- clone 官方 repo,并执行一些预备处理
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
xcopy /Y aten\src\ATen\common_with_cwrap.py tools\shared\cwrap_common.py
2. 在开始菜单找到x86_x64 Cross Tools Command Prompt for VS 2017,打开并切换目录至pytorch的目录下。如果找不到,他的位置一般在C:\Program Files (x86)\Microsoft Visual Studio\2017\Enterprise\VC\Auxiliary\Build\vcvarsx86_amd64.bat。
3. 在x86_x64 Cross Tools Command Prompt for VS 2017下执行如下一些预配置(在set命令后请务必不要多打空格或Tab)
# 如果不需要 CUDA 支持
set NO_CUDA=1
# 如果安装有多个 CUDA 版本,默认会编译最后安装的版本,若要覆盖
set CUDA_PATH=%CUDA_PATH_V8_0%
# 或者
set CUDA_PATH=%CUDA_PATH_V9_0%
# 对于 CUDA 8 的编译
set CMAKE_GENERATOR=Visual Studio 14 2015 Win64
# 对于 CUDA 9 / CPU 的编译
set CMAKE_GENERATOR=Visual Studio 15 2017 Win64
# 你也可以使用 Ninja 来加速 CUDA 的编译
pip install ninja
set CMAKE_GENERATOR=Ninja
# 如果使用 Ninja 为 CUDA 8 进行编译
set PREBUILD_COMMAND=%VS140COMNTOOLS%\..\..\VC\vcvarsall.bat
set PREBUILD_COMMAND_ARGS=x86_amd64
# 如果需要多次编译,可以使用 clcache 来加快下次编译的速度
pip install git+https://github.com/frerich/clcache.git
set USE_CLCACHE=1
set CC=clcache
set CXX=clcache
# 如果需要添加 BLAS 支持(OpenBLAS, MKL)
set LIB=[PATH_TO_BLAS_LIBS];%LIB%
# (仅Conda)如果你的Python版本低于3.5
set PYTHON_VERSION=3.5 # 3.6 or up is also fine
conda create -q -n test python=PYTHON_VERSION numpy mkl cffi pyyaml
activate test
# (仅Python)请安装第三方的numpy和mkl包和官方的pyyaml
pip install numpy.whl
pip install mkl.whl
pip install pyyaml
# 如果你同时安装了 VS 2015 和 2017
set DISTUTILS_USE_SDK=1
4. 开始编译安装
python setup.py install
目前针对Windows的已修复项:
- 在backward过程中抛出异常会导致死锁 PR 2941
- 在Dataloader开多线程时,会存在内存泄漏 PR 2897
- torch.cuda下的一个缩进bug PR 2941
- 增加对新 CUDA 和 cuDNN 版本的支持 PR 2941
目前Windows的已知问题:
- 部分测试会遇到权限不足问题 PR 3447
- 分布式 torch.distributed 和 多显卡 nccl 不支持
- python 3.5 以下的版本不支持
- 多线程的使用方式与 Unix 不同,对于DataLoader的迭代过程一定要使用如下代码做保护。如遇到多线程下的问题,请先将num_worker设置为0试试是否正常。
if __name__ == '__main__':
另外,大家一定很关心什么时候能出正式Windows正式版,日前,Soumith大神给出了他的回复:
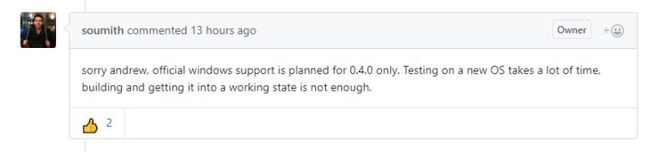
所以这次应该还是见不到正式的Windows版本,但是各位可以期待到时候我的Conda包。
参考:
https://zhuanlan.zhihu.com/p/30954018