机器学习(西瓜书)--第二章 模型评估与选择
一,概念:
错误率:E=1/m;
精度:=1-错误率;
过拟合(overfitting),欠拟合(underfitting);
二,评估方法:
1,留出法(hold-out):将数据集D分成两个互斥的概念,一个训练集S,一个测试集T;
单次的留出法往往得不到稳定可靠的结果,需要进行若干次随机划分、重复实验后,取平均值作为留出法的评估值。
通常选择(2/3~4/5)样本作为训练,其余作为测试,从而解决样本性价比。
2.交叉验证法(cross validation):将数据集D分为k个大小相同的互斥子集,k-1个子集作为训练集,1个子集作为测试集;(k通常取10).与留出法类似,比如10次10折交叉验证法=100次留出法。
3.自助法(bootstrapping):留出法和交叉检验法,测试集比训练集小,会引入一些训练样本规模不同导致的估计偏差。
m个样本数据集D,采样的D', 随机挑选一个样本放入D',然后在放入初始数据集D,重复执行m次后得到m个样本数据集D'.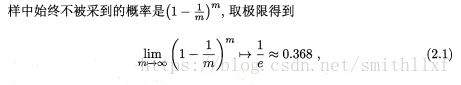 这样我们就有1/3没有在训练集出现的样本用作测试。
这样我们就有1/3没有在训练集出现的样本用作测试。
自主法在数据量小、难于有效划分测试集很有用,可这种方法改变了初始数据集的分布,会引入估计误差。
三,性能度量
1.错误率和精度
2:查准率、全差率
正真例TP,假正例FP,TN真反例,FN假反例;
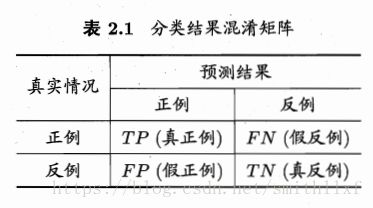
查准率(precision)P:TP/(TP+FP),真正例/预测为真
查全率(recall)R:TP/(TP+FN), 真正例/全部正例。
查全率和查准率是一对矛盾的度量,查全率高时,例如要将好瓜尽可能多的选出来,通过选瓜数量实现,譬如把全部瓜都选上好瓜肯定也都选上了,可是查准率较低;查准率高时,只能选择有把握的瓜,此时查全率就低了。如下图P-R曲线图,如图B将C完全包住,可断言B的性能优于C:
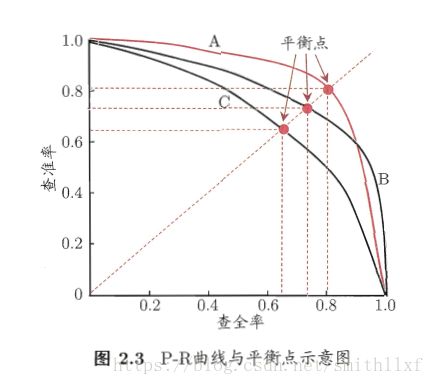
平衡点(Break-Even Point BEP)是查准率=查全率的取值。
F1度量值:查全率和查准率的调和平准值。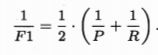


β=1时为标准F1,β>1时查全率有更大影响,β<1时查准率有更大影响。
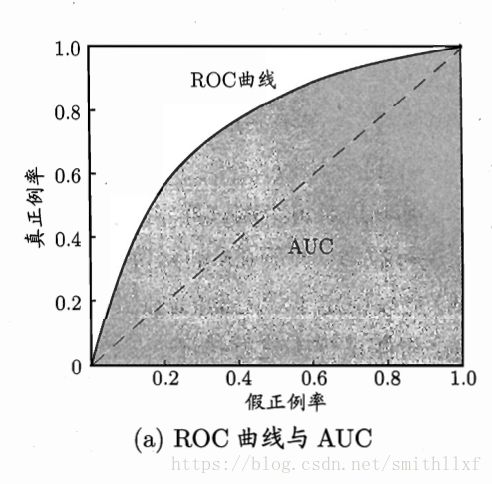
3 ROC与AUC
ROC(Receiver Operating Characteristic)受试者工作特征曲线:纵轴是真正率TPR=TP/(TP+FN),横轴是假正率FPR=FP/(FP+TN);
AUC(Area under ROC Cruve) ROC曲线下的面积。若A方法曲线完全包住B方法,A的性能优于B;
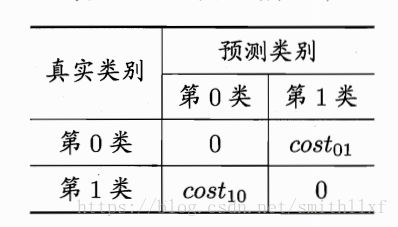
4代价敏感错误率和代价曲线
现实生活中,不同类型的错误导致的损失不同,通过不同的权重代表;比如二分类问题,若costij表示将第i类样本与预测为第j类样本,所以一般costii=0;若将第0类判别为1类损失更大则cost01>cost10;
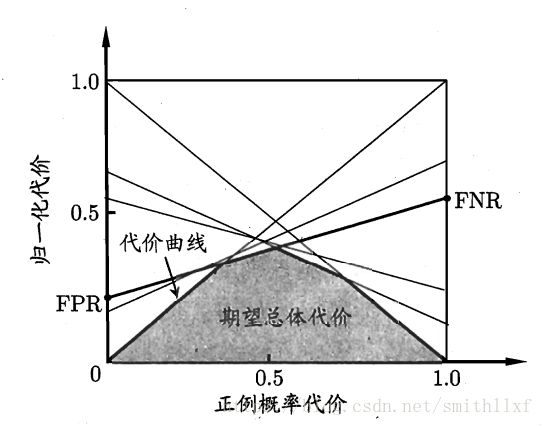
对于非均等代价里,ROC不能直接反映学习器的期望总体代价,而代价曲线可以达到该目的。
四:比较检验(Hypothesis test)
1.测试集和实际情况未必相同;2,测试集的性能和测试集本身有很大关系,不同个测试集结果不同;3,很多算法有一定随机性,同一测试集结果未必相同。泛化错误率ε:在真是情况下的误差。
1 二项分布:
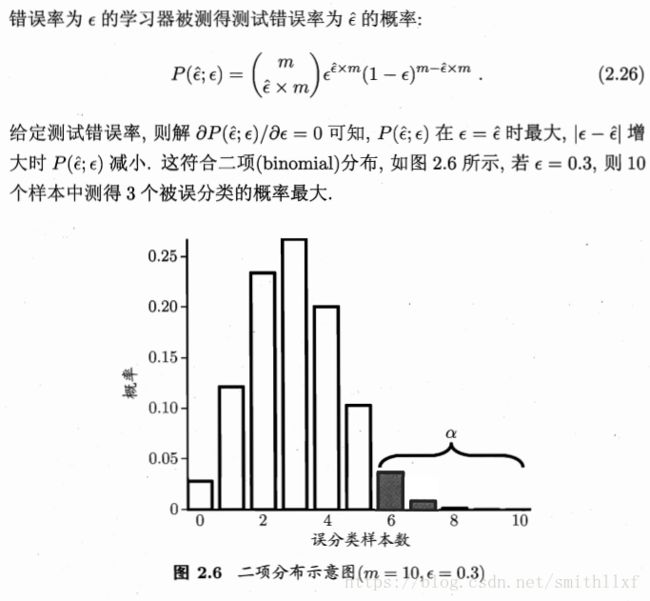
置信度(Confidence):而置信度95%上的置信区间是(50%,60%),那么他的真实支持率有百分之九十五的机率落在百分之五十和百分之六十之间;
t检验:https://blog.csdn.net/m0_37777649/article/details/74937242
2 交叉验证t检验:
对于两个机器学习A、B,若两个学习器性能相同,其错误率应相同;5*2交叉检验是做5次2折交叉检验;
3 McNemar检验:
若两学习器的性能相同,则A预测正确B预测错误数应等于B预测错误A预测正确数;
因此,如下所示的变量服从自由度为1的卡方分布,即服从标准正态分布N(0,1)的随机变量的平方和,下式只有一个变量,故自由度为1,检验的方法同上:做出假设–>求出满足显著度的临界点–>给出拒绝域–>验证假设。
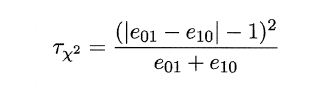
4 Friedman校验和Nemenyi后续校验:
以上的几个算法只能在一个数据集对两种算法进行比较,而Friedman校验可以对多个算法进行比较;
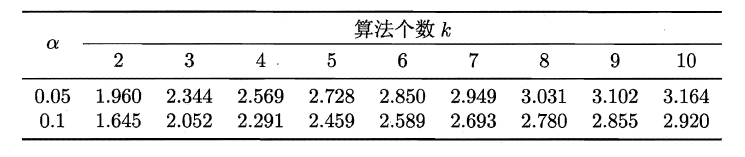
首先对ABC三个算法求平均序值。若算法性能相同,则平均序值均相同,且第i个算法的平均序值ri服从正态分布N((k+1)/2,(k+1)(k-1)/12)。

Nemenyi:
如果“所有算法的性能相同”这个假设被拒绝,则需要进行后续检验(post-hoc test),来得到具体的算法之间的差异。
Nemenyi计算平均序值的临界值域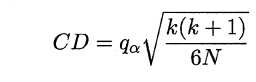 若两个算法的平均序值差超出了临界值域CD,则相应的置信度1-α拒绝“两个算法性能相同”的假设。
若两个算法的平均序值差超出了临界值域CD,则相应的置信度1-α拒绝“两个算法性能相同”的假设。
直观的讲,Friedman校验里的ABC算法,AB算法有交集,因此没有显著差别;AC算法没有交集,因此A算法显著优于C算法;

5 偏差与方差
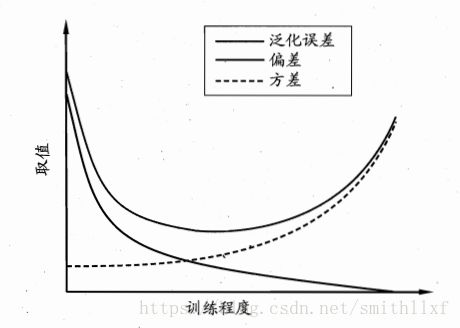
"偏差-方差分解"(bias-variance decomposition)是解释学习算法泛化性能的重要工具;
偏差体现了学习器预测的准确度;而方差体现了学习器预测的稳定性;噪声刻画了学习难度;


一般来说,方差和偏差是有冲突的,当训练强度较低时,偏差做主导,欠拟合;训练强度将高时,方差做主导,过拟合;
课后习题:
1.数据集包含1000个样本,其中500个正例,500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式。
答:将500正反例子分别选150测试集、350训练集,共有![]() .种;
.种;
2.2.数据集包含100个样本,其中正反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
答:目的是将测试集被划分到训练样本中多的类,留一法将一个作为测试集,99个为训练集,训练样本较多的为50个都与测试集不同,今次错误率100%;
10折交叉验证,10个子集,由于每次训练样本中正反例数目一样,所以讲结果判断为正反例的概率也是一样的,所以错误率的期望是5050%。
2.3 .若学习器A的F1值比学习器B高,试析A的BEP值是否也比B高。
BEP:查准率=查全率
F1:查准率\查全率 调和平均值。
P=R时,F1=BEP;因此答案时肯定的。
2.4 .试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)之间的联系。
答:真正例率 = 查准率;假正例率没有关联;
2.5 证明式子AUC=1−lrank
2.6 错误率和ROC曲线的关系
2.7.试证明任意一条ROC曲线都有一条代价曲线与之对应,反之亦然。
2.8.Min-Max规范化与z-score规范化如下所示。试析二者的优缺点。
2.9 试述卡方检验的过程