深度强化学习——A3C
联系方式:[email protected]
异步的优势行动者评论家算法(Asynchronous Advantage Actor-Critic,A3C)是Mnih等人根据异步强化学习(Asynchronous Reinforcement Learning, ARL) 的思想,提出的一种轻量级的 DRL 框架,该框架可以使用异步的梯度下降法来优化网络控制器的参数,并可以结合多种RL算法。
一、问题与贡献
存在的问题
不同类型的深度神经网络为 DRL 中策略优化任务提供了高效运行的表征形式。 为了缓解传统策略梯度方法与神经网络结合时出现的不稳定性,各类深度策略梯度方法(如 DDPG、 SVG 等)都采用了经验回放机制来消除训练数据间的相关性。
然而经验回放机制存在两个问题:
- agent 与环境的每次实时交互都需要耗费很多的内存和计算力;
- 经验回放机制要求 agent 采用离策略(off-policy)方法来进行学习,而off-policy方法只能基于旧策略生成的数据进行更新;
此外,过往DRL的训练都依赖于计算能力很强的图形处理器(如GPU)
论文贡献
异步地执行多个 agent, 通过并行的 agent 经历的不同状态,去除训练过程中产生的状态转移样本之间的关联性;
只需一个标准的多核CPU即可实现算法,在效果、时间和资源消耗上都优于传统方法。
适用范围:
on-policy:sarsa, n-step methods, actor-critic
off-policy:Q-Learning
离散、连续型动作控制
二、RL背景知识
Value-Based(或Q-Learning)和Policy-Based(或Policy Gradients)是强化学习中最重要的两类方法,区别在于
- Value-Based是预测某个State下所有Action的期望价值(Q值),之后通过选择最大Q值对应的Action执行策略,适合仅有少量离散取值的Action的环境;
- Policy-Based是直接预测某个State下应该采取的Action,适合高维连续Action的环境,更通用;
根据是否对State的变化进行预测,RL又可以分为model-based和model-free:
- model-based,根据State和采取的Action预测接下来的State,并利用这个信息训练强化学习模型(知道状态的转移概率);
- model-free,不需对环境状态进行任何预测,也不考虑行动将如何影响环境,直接对策略或Action的期望价值进行预测,计算效率非常高。
因为复杂环境中难以使用model预测接下来的环境状态,所以传统的DRL都是基于model-free。
1. Value-Based & model-free
t时刻开始到情节结束时,总回报:
状态价值函数
动作价值函数
DQN的Loss Function
上面的Loss Function基于one-step Q-learning。
所谓one-step是计算Target Q值时只看下一个State,而n-step则是计算了后续n步的State,即
One-step的缺点:
只直接影响产生回报r的pair(s, a)的Value,其他pairs的Value只能通过Q(s,a)间接影响,造成学习速度很慢。
n-step的优点:
一个回报r直接影响先前n个pairs,学习更有效。
2. Policy-Based & model-free
直接将策略参数化
通过迭代更新 θ ,使总回报期望 E[Rt] 梯度上升。
具体地
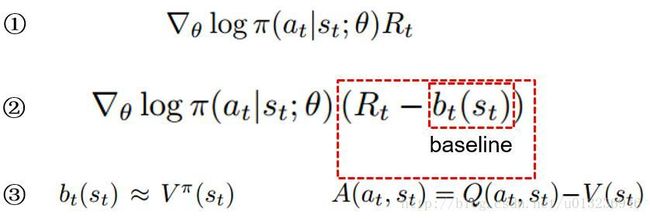
①中, π(at|st;θ) 表示在 st,θ 的情况下选择动作 at 的概率。概率的对数乘以该动作的总回报 Rt ,对 θ 求梯度,以梯度上升的方式更新 θ 。该公式的意义在于,回报越高的动作越努力提高它出现的概率。
但是某些情形下,每个动作的总回报 Rt 都不为负,那么所有的梯度值都大于等于0,此时每个动作出现的概率都会提高,这在很大程度下减缓了学习的速度,而且也会使梯度的方差很大。因此需要对 Rt 使用某种标准化操作来降低梯度的方差。
②具体地,可以让 Rt 减去一个基线 b (baseline), b 通常设为 Rt 的一个期望估计,通过求梯度更新 θ ,总回报超过基线的动作的概率会提高,反之则降低,同时还可以降低梯度方差(证明略)。这种方式被叫做行动者-评论家(actor-critic)体系结构,其中策略 π 是行动者,基线 bt 是评论家。
③在实际中, Rt−bt(st) 可使用动作优势函数 Aπ(at,st)=Qπ(at,st)−Vπ(st) 代替,因为 Rt 可以视为 Qπ(at,st) 的估计,基线 bt(st) 视为 Vπ(st) 的估计。
三、异步RL框架
论文共实现了四种异步训练的强化学习算法,分别是one-step Q-learning, one-step Sarsa, n-step Q-learning, and advantage actor-critic(A3C)。
不同线程的agent,其探索策略不同以保证多样性,不需要经验回放机制,通过各并行agent收集的样本训练降低样本相关性,且学习的速度和线程数大约成线性关系,能适用off-policy、on-policy,离散型、连续型动作。
Asynchronous one-step Q-learning

Asynchronous one-step Sarsa

相比Q-learning的算法只有一处不同。
Sara是on-policy,Q-learning是off-policy。
Asynchronous n-step Q-learning

A3C

A3C更新公式有两条,一条梯度上升更新策略 π 参数,如前面介绍actor-critic体系结构,
θ′ 是策略 π 的参数, θ′v 是状态值函数的参数。 k 是可变化的,上界由n-step决定,即n。
在实际操作中,论文在该公式中加入了策略 π 的熵项 β∇θ′H(π(st;θ′)) ,防止过早的进入次优策略。
另一条公式是使用TD方式梯度下降更新状态值函数的参数,即算法中的
注意:
A3C算法中已经没有了TargetNet,而且在控制离散动作时 π(at|st,θ) 和 Vπ(st;θv) 用的是同一个网络,在网络的输出层分 π 和 Vπ 。
四个算法都是等所有的异步agent执行完后再用累计的梯度信息更新网络参数。其中n-step的算法(后两个)需要每个异步agent复制一份子网络,每个anget执行n步后倒退算出每步的总回报和相关梯度,用累计梯度更新主网络参数(如果不复制子网络,则等单个agent执行完n-step耗时太多,而one-step可忽略这个影响)。
四、实验
论文共对4个实验平台进行了测试,分别是Atari 2600、TORCS 3D 赛车模拟器、MuJoCo 物理模拟器、Labyrinth (3D 迷宫),在这些实验中A3C取得了非常好的效果。
因为我当时主要研究的是连续动作控制,所以详细说一下MuJoCo的实验。
在论文中,相比Atari 2600离散动作控制的A3C,MuJoCo连续动作控制的A3C主要不同点在于:
网络输出层
在离散动作控制中,策略的输出使用的是Softmax,对应每个动作被选中的概率。
而连续动作难以用Softmax表示动作的概率,但可以用正态分布表示,因此策略网络输出分两部分,一个是正态分布均值向量 μ (对应多维情况),另一个是正态分布方差标量 σ2 。训练时使用两者构成的正态分布采样动作,实际应用时用均值 μ 当动作。
(在实验中,我发现使用网络确定的 σ2 很难训练出好的策略,可能是因为 σ2 容易很快变小,所以我通常用自己确定的 σ2 。)
策略和值函数
在其他实验里,策略网络和值函数网络是用一个,只是输出层分开;而在MuJoCo连续动作控制中,两个网络是分开的。
更新方式
因为MuJoCo实验中情节长度一般最多只有几百步,所以将单个情节的所有样本作为一个minibatch更新网络
五、GPU版A3C
M Babaeizadeh等人提出了一种混合CPU/GPU版的A3C,并提供开源代码https://github.com/NVlabs/GA3C。
原版A3C存在的问题:
- 原版A3C未用到GPU,而GPU可以加快网络训练速度;
原版A3C训练时需要给每个并行的agent复制一份子网络来收集样本计算累计梯度,当并行的agent数量很多时耗内存。
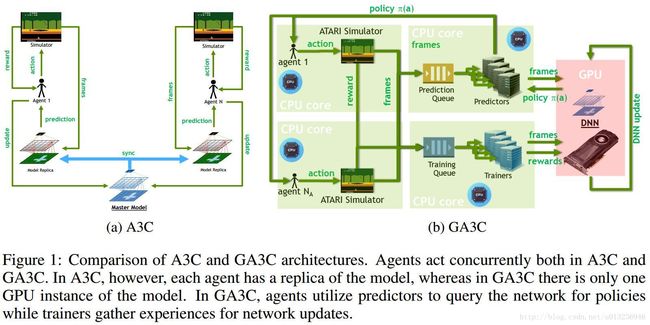
如上图所示,左边 (a) 是原版A3C,需要每个agent复制一份模型;右边 (b) 是GA3C,只需要一个模型,用GPU训练或预测动作。
具体地,GA3C主要分为:
- Agent,和A3C功能一样,收集样本,但是不需要各自复制一份模型,只需要在每次选择Action前,将当前的State作为请求加入 Prediction Queue;执行动作n步后倒退算出每步的总回报,得到的n个 (st,at,R,st+1) 加入 Trainning Queue;
- Predictor,将 Prediction Queue 中的请求样本出队作为minibatch填入GPU的网络模型中,将模型预测的Action返回给各自的Agent,为减少延迟,可以使用多线程并行多个predictiors;
- Trainer,将 Trainning Queue 的样本出队作为minibatch填入GPU的网络模型中,训练更新模型,同样,为减少延迟,可以使用多线程并行多个trainers;
GA3C带来的问题:
- 需要协调Agent、Predictior和Trainer的个数;
- 可能存在策略延迟,即产生当前训练样本的策略非当前要更新的策略,导致算法不稳定。
实验表明,相比A3C,GA3C的训练速度大幅度提升,且减少内存消耗。
参考文献
[1]Asynchronous Methods for Deep Reinforcement Learning
[2]Reinforcement learning through asynchronous advantage actor-critic on a gpu
[3]深度强化学习综述_刘全等