hadoop 超详细集群部署过程-Ali0th
Author : Ali0th
Date : 2019-4-22
经过上一篇部署单机 hadoop 之后,开始尝试部署 hadoop 集群。hadoop集群最少需要三台机,因为hdfs副本数最少为3。这里我们使用四台机子进行搭建。
本文尽求详尽,包括所有步骤与问题的解决。可见目录,有对遇到的bug的一些解决方法。可以看到我是如何踩坑过来的。
0.1. 目录
文章目录
- 0.1. 目录
- 0.2. 环境
- 0.3. 集群设备
- 0.4. hostname 配置
- 0.5. 环境变量配置
- 0.6. ssh 免密登录
- 0.7. 配置时间当步
- 0.8. hadoop 配置文件
- 0.8.1. 创建数据存储目录
- 0.8.2. 配置 hadoop-env.sh
- 0.8.3. core-site.xml hdfs-site.xml
- 0.8.4. 编辑 yarn-site.xml 配置文件
- 0.8.5. 拷贝并编辑 MapReduce 的配置文件
- 0.8.6. 配置从节点主机名
- 0.8.7. 配置分发
- 0.9. 对NameNode做格式化
- 0.10. 启动集群
- 0.11. 查看进程与端口
- 0.12. 附录
- 0.12.1. `/etc/hosts` 与 `/etc/sysconfig/network` 的区别
- 0.12.2. hadoop 3.0 与 2.0 的异同
- 0.13. 问题与解决
- 0.14. 资料
0.2. 环境
hadoop 3.0
CentOS release 6.4
openjdk version "1.8.0_201"
0.3. 集群设备
准备四台虚拟机,一台 master,三台 slaver。master 作为NameNode、DataNode、ResourceManager、NodeManager,slave 均作为DataNode、NodeManager。
master : 192.168.192.164
slave1 : 192.168.192.165
slave2 : 192.168.192.167
slave3 : 192.168.192.166
0.4. hostname 配置
由于 Hadoop 集群内部有时需要通过主机名来进行相互通信,因此我们需要保证每一台机器的主机名都不相同。
vim /etc/hosts # 四台机器都需要操作
192.168.192.164 master
192.168.192.165 slave1
192.168.192.167 slave2
192.168.192.166 slave3
reboot # 重启
hostname # 查看主机名
/etc/hosts 与 /etc/sysconfig/network 的区别
0.5. 环境变量配置
vim /etc/profile
#java
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el6_10.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
0.6. ssh 免密登录
四台机器均执行下面操作
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
每个机子上都操作一下,把公钥拷贝到其他机器上
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
ssh-copy-id -i ~/.ssh/id_rsa.pub slave3
测试配置成功
[mt@slave3 ~]$ ssh master
Last login: Tue Apr 16 17:51:47 2019 from slave2
[mt@master ~]$ ssh slave3
Last login: Tue Apr 16 17:32:12 2019 from 192.168.192.1
[mt@slave3 ~]$ ssh slave2
Last login: Tue Apr 16 17:51:42 2019 from master
[mt@slave2 ~]$ ssh slave3
Last login: Tue Apr 16 17:53:08 2019 from master
[mt@slave3 ~]$
0.7. 配置时间当步
详细配置见 :hadoop集群时间同步
这里试验使用阿里云时间
ntpdate ntp1.aliyun.com
0.8. hadoop 配置文件
共需要配置/opt/hadoop/hadoop-3.1.0/etc/hadoop/下的六个个文件,分别是
hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
cd $HADOOP_HOME
cd etc/hadoop
0.8.1. 创建数据存储目录
- NameNode 数据存放目录: /usr/local/data/hadoop/name
- SecondaryNameNode 数据存放目录: /usr/local/data/hadoop/secondary
- DataNode 数据存放目录: /usr/local/data/hadoop/data
- 临时数据存放目录: /usr/local/data/hadoop/tmp
- HADOOP_MAPRED_HOME :
sudo mkdir -p /usr/local/data/hadoop/name
sudo mkdir -p /usr/local/data/hadoop/secondary
sudo mkdir -p /usr/local/data/hadoop/data
sudo mkdir -p /usr/local/data/hadoop/tmp
0.8.2. 配置 hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el6_10.x86_64
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
0.8.3. core-site.xml hdfs-site.xml
接着分别编辑core-site.xml以及hdfs-site.xml配置文件
vim core-site.xml # 增加如下内容
hadoop配置文件详解系列(一)-core-site.xml篇
需要配置的是 name,tmp.dir
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://master:8020value>
<description>指定默认的访问地址以及端口号description>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/data/value>
<description>其它临时目录的父目录,会被其它临时目录用到description>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
<description>在序列中使用的缓冲区大小description>
property>
configuration>
vim hdfs-site.xml # 增加如下内容
需要配置的是 replication、namenode 、datanode 、 web.
<configuration>
<property>
<name>dfs.replicationname>
<value>4value>
<description>副本数,HDFS存储时的备份数量description>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/local/data/hadoop/namevalue>
<description>namenode临时文件所存放的目录description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/local/data/hadoop/datavalue>
<description>datanode临时文件所存放的目录description>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>master:50070value>
<description>hdfs web 地址description>
property>
configuration>
0.8.4. 编辑 yarn-site.xml 配置文件
vim yarn-site.xml # 增加如下内容
需要配置的是数据获取方式, master 地址,(配置yarn 外部可访问),关闭内存检测(虚拟机需要),容器可能会覆盖的环境变量。
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<description>nomenodeManager获取数据的方式是shuffledescription>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
<description>指定Yarn的老大(ResourceManager)的地址description>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>192.168.192.164:8088value>
<description>配置 yarn 外部可访问,(外网IP:端口)description>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZvalue>
<description>容器可能会覆盖的环境变量,而不是使用NodeManager的默认值description>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
<description>关闭内存检测,虚拟机需要,不配会报错description>
property>
configuration>
0.8.5. 拷贝并编辑 MapReduce 的配置文件
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml # 增加如下内容
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>告诉hadoop以后MR(Map/Reduce)运行在YARN上description>
property>
<property>
<name>mapreduce.admin.user.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
<description>可以设置AM【AppMaster】端的环境变量,如果上面缺少配置,
可能会造成mapreduce失败description>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
<description>可以设置AM【AppMaster】端的环境变量,如果上面缺少配置,
可能会造成mapreduce失败description>
property>
configuration>
0.8.6. 配置从节点主机名
最后是配置从节点的主机名,如果没有配置主机名的情况下就使用IP:
vim workers # hadoop3.0以后slaves更名为workers
slave1
slave2
slave3
0.8.7. 配置分发
分发 hadoop 及其配置:
rsync -av /usr/local/hadoop slave1:/usr/local/hadoop
rsync -av /usr/local/hadoop slave2:/usr/local/hadoop
rsync -av /usr/local/hadoop slave3:/usr/local/hadoop
rsync -av ~/.bash_profile slave1:~/.bash_profile
rsync -av ~/.bash_profile slave2:~/.bash_profile
rsync -av ~/.bash_profile slave3:~/.bash_profile
这里我每个机子都装了相同的 hadoop ,所以只要分发配置文件即可:
rsync -av /usr/local/hadoop/etc/hadoop/* slave1:/usr/local/hadoop/etc/hadoop
rsync -av /usr/local/hadoop/etc/hadoop/* slave2:/usr/local/hadoop/etc/hadoop
rsync -av /usr/local/hadoop/etc/hadoop/* slave3:/usr/local/hadoop/etc/hadoop
rsync -av ~/.bash_profile slave1:~/.bash_profile
rsync -av ~/.bash_profile slave2:~/.bash_profile
rsync -av ~/.bash_profile slave3:~/.bash_profile
在从节点执行:
source ~/.bash_profile
0.9. 对NameNode做格式化
只需要在 master 执行即可。
hdfs namenode -format
0.10. 启动集群
# 一次性启动
start-all.sh
# 逐个组件启动
start-dfs.sh
start-yarn.sh
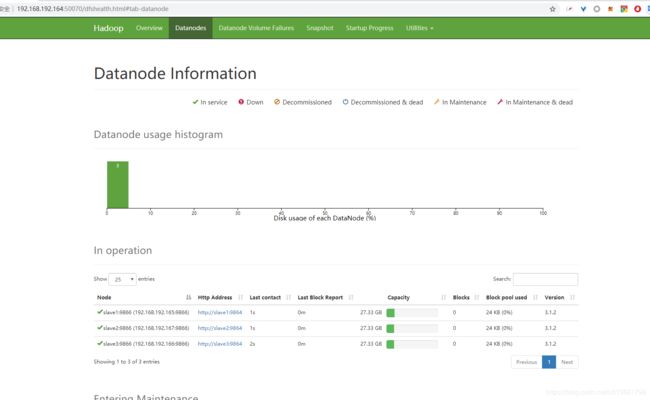
尝试上传文件,成功。
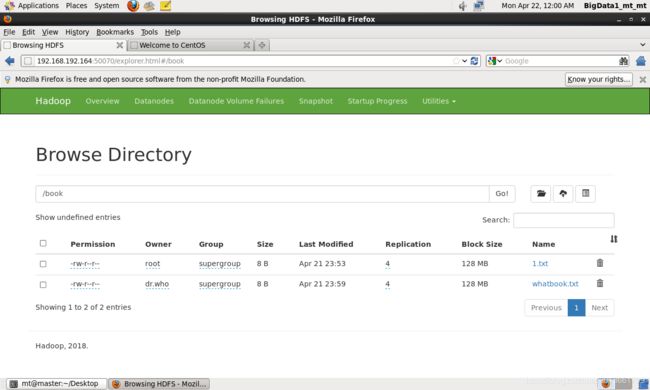
0.11. 查看进程与端口
查看进程
[hadoop@master hadoop]$ jps
13794 NodeManager
13667 ResourceManager
14100 Jps
13143 NameNode
[hadoop@master hadoop]$ ps -ef|grep java
hadoop 13143 1 7 02:10 ? 00:00:03 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el6_10.x86_64/bin/java -Dproc_namenode -Djava.library.path=/lib -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dyarn.log.dir=/usr/local/hadoop/logs -Dyarn.log.file=hadoop-hadoop-namenode-master.log -Dyarn.home.dir=/usr/local/hadoop -Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/usr/local/hadoop/logs -Dhadoop.log.file=hadoop-hadoop-namenode-master.log -Dhadoop.home.dir=/usr/local/hadoop -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.namenode.NameNode
hadoop 13667 1 18 02:10 pts/0 00:00:05 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el6_10.x86_64/bin/java -Dproc_resourcemanager -Djava.library.path=/usr/local/hadoop/lib -Dservice.libdir=/usr/local/hadoop/share/hadoop/yarn,/usr/local/hadoop/share/hadoop/yarn/lib,/usr/local/hadoop/share/hadoop/hdfs,/usr/local/hadoop/share/hadoop/hdfs/lib,/usr/local/hadoop/share/hadoop/common,/usr/local/hadoop/share/hadoop/common/lib -Dyarn.log.dir=/usr/local/hadoop/logs -Dyarn.log.file=hadoop-hadoop-resourcemanager-master.log -Dyarn.home.dir=/usr/local/hadoop -Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/usr/local/hadoop/logs -Dhadoop.log.file=hadoop-hadoop-resourcemanager-master.log -Dhadoop.home.dir=/usr/local/hadoop -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
hadoop 13794 1 17 02:10 ? 00:00:04 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el6_10.x86_64/bin/java -Dproc_nodemanager -Djava.library.path=/lib -Dyarn.log.dir=/usr/local/hadoop/logs -Dyarn.log.file=hadoop-hadoop-nodemanager-master.log -Dyarn.home.dir=/usr/local/hadoop -Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/usr/local/hadoop/logs -Dhadoop.log.file=hadoop-hadoop-nodemanager-master.log -Dhadoop.home.dir=/usr/local/hadoop -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.yarn.server.nodemanager.NodeManager
hadoop 14116 12870 0 02:11 pts/0 00:00:00 grep java
查看端口
netstat -tnlp
0.12. 附录
0.12.1. /etc/hosts 与 /etc/sysconfig/network 的区别
Linux系统在向DNS服务器发出域名解析请求之前会查询/etc/hosts文件,如果里面有相应的记录,就会使用hosts里面的记录。/etc/hosts文件通常里面包含这一条记录
network文件,路径:/etc/sysconfig/network,此文件是针对本计算机的,是给计算机起的一个名字,是计算机的一个标识。
设置了 /etc/hosts 后重启,/etc/rc.d/rc.sysinit 启动脚本会根据 eth0 的 ip 和 /etc/hosts 中的对应关系,把系统的 hostname 改成相应的名称。
# In theory there should be no more than one network interface active
# this early in the boot process -- the one we're booting from.
# Use the network address to set the hostname of the client. This
# must be done even if we have local storage.
ipaddr=
if [ "$HOSTNAME" = "localhost" -o "$HOSTNAME" = "localhost.localdomain" ]; then
ipaddr=$(ip addr show to 0.0.0.0/0 scope global | awk '/[[:space:]]inet / { print gensub("/.*","","g",$2) }')
for ip in $ipaddr ; do
HOSTNAME=
eval $(ipcalc -h $ip 2>/dev/null)
[ -n "$HOSTNAME" ] && { hostname ${HOSTNAME} ; break; }
done
fi
# code ...
# Reread in network configuration data.
if [ -f /etc/sysconfig/network ]; then
. /etc/sysconfig/network
# Reset the hostname.
action $"Resetting hostname ${HOSTNAME}: " hostname ${HOSTNAME}
fi
0.12.2. hadoop 3.0 与 2.0 的异同
官方介绍:https://hadoop.apache.org/docs/r3.0.0/index.html
1 端口变化
Namenode ports: 50470 –> 9871, 50070 –> 9870, 8020 –> 9820
Secondary NN ports: 50091 –> 9869, 50090 –> 9868
Datanode ports: 50020 –> 9867, 50010 –> 9866, 50475 –> 9865, 50075 –> 9864
2 节点配置文件由slaves改为了workers
3 Hadoop3.0最低支持Java8
0.13. 问题与解决
问题:
虽然 hadoop 启动了,但 Jps 不显示 hadoop 进程信息。
解决:
使用hdfs namenode -format格式化namenode时,会在namenode数据文件夹中保存一个current/VERSION文件,记录clusterID,而datanode中保存的current/VERSION文件中的clustreID的值是第一次格式化保存的clusterID,再次进行格式化时,就会生成新的clusterID,并保存在namenode的current/VERSION文件中,从而datanode和namenode之间的ID不一致。导致上述结果!
修改NameNode的VERSION文件的clusterID的值。
namenode节点的路径:/解压路径/hadoop/tmp/dfs/name/current
datanode节点的路径:/解压路径/hadoop/tmp/dfs/data/current/
more VERSION,可发现,datanode的clustreID与其他3台datanode的clustreID不同。
vim VERSION修改clusterID的值与DataNode相同即可,并启动。
问题:
Couldn’t find datanode to write file. Forbidden
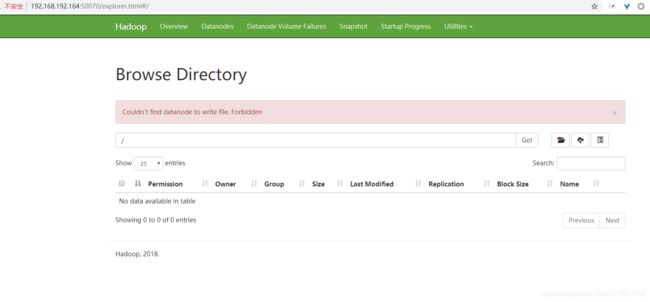
解决:
由于多次格式化hdfs,导致格式化hdfs的时候失败(提示Reformat Y or N,输入了Y也不能格式化成功),可能会导致namenode无法启动,所以如果要重新格式化。清空 hadoop.tmp.dir配置项路径下的tmp和logs 即可。
rm -rf (文件夹路径)/*
rm -rf /usr/local/hadoop/data/*
rm -rf /usr/local/data/hadoop/name/*
rm -rf /usr/local/data/hadoop/data/*
重新启动后,发现问题依旧存在。
使用 hdfs dfsadmin -report 检查。
[root@master hadoop]# hdfs dfsadmin -report
Configured Capacity: 0 (0 B)
Present Capacity: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used: 0 (0 B)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
使用 tail -n 10 logs/hadoop-hadoop-datanode-slave1.log 查看 slave1 的日志。
[root@slave1 hadoop]# tail -n 10 logs/hadoop-hadoop-datanode-slave1.log
2019-04-18 02:18:15,895 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost.localdomain/127.0.0.1:9000. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2019-04-18 02:18:16,896 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost.localdomain/127.0.0.1:9000. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2019-04-18 02:18:17,900 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost.localdomain/127.0.0.1:9000. Already tried 6 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2019-04-18 02:18:18,904 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost.localdomain/127.0.0.1:9000. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2019-04-18 02:18:19,906 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost.localdomain/127.0.0.1:9000. Already tried 8 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2019-04-18 02:18:20,788 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RECEIVED SIGNAL 15: SIGTERM
2019-04-18 02:18:20,792 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at slave1/192.168.192.165
************************************************************/
发现 slave1 连接不上 master,发现是因为 slave1 以为 localhost.localdomain 才是 master,发现 slave1 的配置文件中,core-site.xml 如下,配置是 hdfs://localhost.localdomain:9000。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost.localdomain:9000</value>
<description>hdfs内部通讯访问地址</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/data/hadoop/tmp</value>
</property>
</configuration>
原来是配置没有分发成功,重新进行分发即可。
问题:
Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
解决:
hadoop fs -chmod 777 /
问题:
Couldn’t upload the file 从人工智能到TensorFlow.pdf.
解决:
应该是在别的机子访问时,没有配置host地址解析造成的。
0.14. 资料
Hadoop学习之路(四)Hadoop集群搭建和简单应用
Hadoop分布式集群环境搭建
Hadoop-3.0.0体验