常用网络模型结构LeNet,AlexNET,VGG,BN-inception,ResNet网络模型简介和资料整理--caffe学习(8)
在使用深度神经网络时我们一般推荐使用大牛的组推出的和成功的网络。如最近的google团队推出的BN-inception网络和inception-v3以及微软最新的深度残差网络ResNET。
我们从简单的网络开始介绍,学习理解网络结构是如何发展到今天的,同时本文整理了自己用别人网络结构时别人的网络结构的pre-reain model和prototxt文件的资源。
首先安利caffe zoo大法,可以找到很多caffe的model和prototxt文件:点这里
下面正式开始介绍各个网络:
1:LeNet:1989年Yann LeCun提出的LeNet卷积神经网络模型
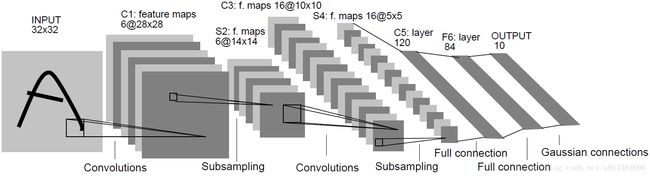
左侧是输入的手写图像,经过C1,S2,C3,S4两对卷积池化层,再经过C5和F6两个全连接隐层得到输出Output。
使用的手写图像库来自于Yann LeCun网站 http://yann.lecun.com/exdb/mnist/ 上下载的手写数字图像库,分辨率为28*28,和模型示意图中稍有区别。其它各层的节点数也稍有不同:C1层不是6个卷积模板,而是20个;C3层为50个不同卷积模板;C5层的神经元节点数为500个。
LeNet网络仅仅使用了两个卷积层,可以说是很浅层的网络,但是其在mnist数据集上的准确率已经达到了100%,可见网络也不一定要很深才能达到很好的效果。
在caffe上已经把这个网络实现了并且当做一个example给我们可以直接使用,everything都在目录caffe-master\examples\mnist下。
初学者也可以参考一下Caffe中的配置文件:
https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet.prototxt
2:AlexNet
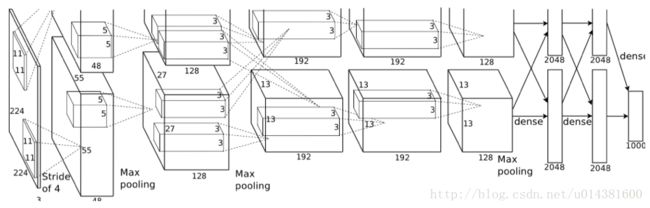
在这里写链接内容网络中将该模型画出来:
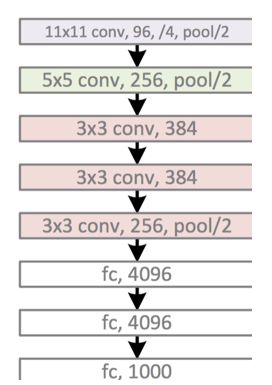
AlexNet相比LeNet主要的改动在于:
(1) Data Augmentation数据增长,现在的网络中已经大量使用了。最主要的是剪裁,光照变换和水平翻转。
(2) Dropout
Dropout方法和数据增强一样,都是防止过拟合的。Dropout应该算是AlexNet中一个很大的创新,以至于Hinton在后来很长一段时间里的Talk都拿Dropout说事,后来还出来了一些变种,比如DropConnect等。
(3) ReLU激活函数
用ReLU代替了传统的Tanh或者Logistic。好处有:
ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
(4) Local Response Normalization
Local Response Normalization要硬翻译的话是局部响应归一化,简称LRN,实际就是利用临近的数据做归一化。这个策略贡献了1.2%的Top-5错误率。
(5) Overlapping Pooling
Overlapping的意思是有重叠,即Pooling的步长比Pooling Kernel的对应边要小。这个策略贡献了0.3%的Top-5错误率。
(6) 多GPU并行
3:VGG
VGG是牛津大学计算机视觉组,网站这里写链接内容
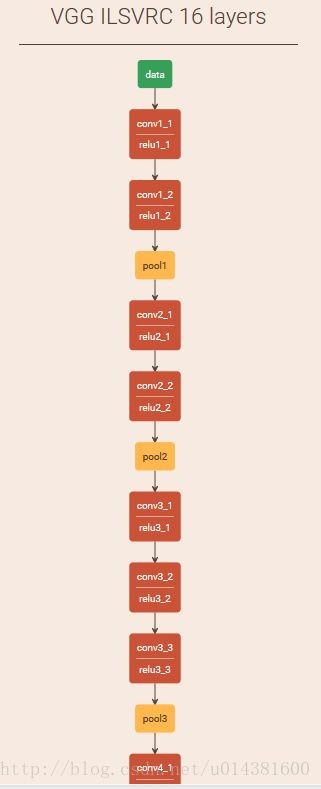
网络太大,这里是一部分的图,16层的层数在目前来说还可以,性能也不错。
有一个 蛋疼的地方,VGG官网给的caffe的prototxt文件不能直接在最新的caffe里面运行,需要改好几处的关键字,这里贴一下我修改过的的vgg16网络结构文件
name: "VGG16"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
# transform_param {
# mirror: true
# crop_size: 224
# mean_file: "data/ilsvrc12_shrt_256/imagenet_mean.binaryproto"
# }
transform_param {
mirror: true
crop_size: 224
mean_value: 103.939
mean_value: 116.779
mean_value: 123.68
}
data_param {
source: "data/ilsvrc12_shrt_256/ilsvrc12_train_leveldb"
batch_size: 64
backend: LEVELDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
# transform_param {
# mirror: false
# crop_size: 224
# mean_file: "data/ilsvrc12_shrt_256/imagenet_mean.binaryproto"
# }
transform_param {
mirror: false
crop_size: 224
mean_value: 103.939
mean_value: 116.779
mean_value: 123.68
}
data_param {
source: "data/ilsvrc12_shrt_256/ilsvrc12_val_leveldb"
batch_size: 50
backend: LEVELDB
}
}
layer {
bottom: "data"
top: "conv1_1"
name: "conv1_1"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv1_1"
top: "conv1_1"
name: "relu1_1"
type: "ReLU"
}
layer {
bottom: "conv1_1"
top: "conv1_2"
name: "conv1_2"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv1_2"
top: "conv1_2"
name: "relu1_2"
type: "ReLU"
}
layer {
bottom: "conv1_2"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool1"
top: "conv2_1"
name: "conv2_1"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv2_1"
top: "conv2_1"
name: "relu2_1"
type: "ReLU"
}
layer {
bottom: "conv2_1"
top: "conv2_2"
name: "conv2_2"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv2_2"
top: "conv2_2"
name: "relu2_2"
type: "ReLU"
}
layer {
bottom: "conv2_2"
top: "pool2"
name: "pool2"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool2"
top: "conv3_1"
name: "conv3_1"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv3_1"
top: "conv3_1"
name: "relu3_1"
type: "ReLU"
}
layer {
bottom: "conv3_1"
top: "conv3_2"
name: "conv3_2"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv3_2"
top: "conv3_2"
name: "relu3_2"
type: "ReLU"
}
layer {
bottom: "conv3_2"
top: "conv3_3"
name: "conv3_3"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv3_3"
top: "conv3_3"
name: "relu3_3"
type: "ReLU"
}
layer {
bottom: "conv3_3"
top: "pool3"
name: "pool3"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool3"
top: "conv4_1"
name: "conv4_1"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv4_1"
top: "conv4_1"
name: "relu4_1"
type: "ReLU"
}
layer {
bottom: "conv4_1"
top: "conv4_2"
name: "conv4_2"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv4_2"
top: "conv4_2"
name: "relu4_2"
type: "ReLU"
}
layer {
bottom: "conv4_2"
top: "conv4_3"
name: "conv4_3"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv4_3"
top: "conv4_3"
name: "relu4_3"
type: "ReLU"
}
layer {
bottom: "conv4_3"
top: "pool4"
name: "pool4"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool4"
top: "conv5_1"
name: "conv5_1"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv5_1"
top: "conv5_1"
name: "relu5_1"
type: "ReLU"
}
layer {
bottom: "conv5_1"
top: "conv5_2"
name: "conv5_2"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv5_2"
top: "conv5_2"
name: "relu5_2"
type: "ReLU"
}
layer {
bottom: "conv5_2"
top: "conv5_3"
name: "conv5_3"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "conv5_3"
top: "conv5_3"
name: "relu5_3"
type: "ReLU"
}
layer {
bottom: "conv5_3"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool5"
top: "fc6"
name: "fc6"
type: "InnerProduct"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
bottom: "fc6"
top: "fc6"
name: "relu6"
type: "ReLU"
}
layer {
bottom: "fc6"
top: "fc6"
name: "drop6"
type: "Dropout"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
bottom: "fc6"
top: "fc7"
name: "fc7"
type: "InnerProduct"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
bottom: "fc7"
top: "fc7"
name: "relu7"
type: "ReLU"
}
layer {
bottom: "fc7"
top: "fc7"
name: "drop7"
type: "Dropout"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
bottom: "fc7"
top: "fc8"
name: "fc8"
type: "InnerProduct"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "accuracy_at_1"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy_at_1"
accuracy_param {
top_k: 1
}
include {
phase: TEST
}
}
layer {
name: "accuracy_at_5"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy_at_5"
accuracy_param {
top_k: 5
}
include {
phase: TEST
}
}
layer {
bottom: "fc8"
bottom: "label"
top: "loss"
name: "loss"
type: "SoftmaxWithLoss"
}4:BN-inception网络
BN-inception网络是GoogLeNet的一种,BN-inceptionv1训练速度较原googlenet快了14倍,在imagenet分类问题的top5上达到4.8%,超过了人类标注top5准确率。
理论见:Batch Normalization(http://arxiv.org/pdf/1502.03167v3.pdf)文章
网络结构见:这里写链接内容
性能:
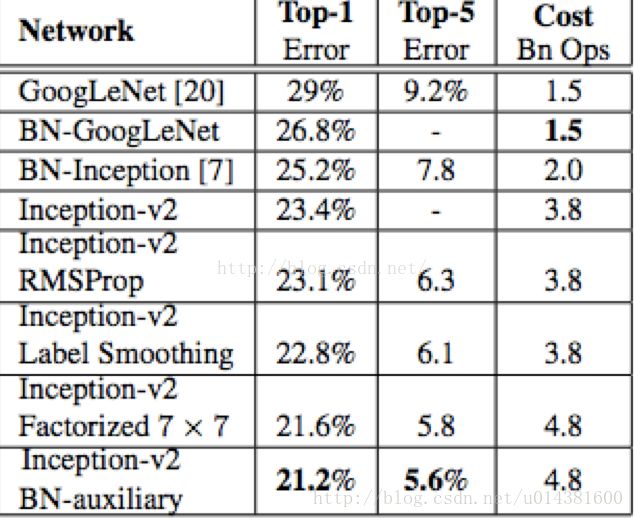
goole团队还推出了其他的网络V1到V4,见
1
2
5:ResNet网络
获奖无数的深度残差学习,清华学霸的又一次No.1 |(CVPR2016 最佳论文 )
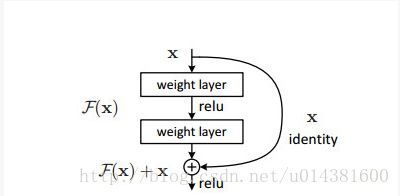
它的一个基本构件结构如上。
残差学习
将H(X)假设为由几个堆叠层匹配的(不一定是整个网)基础映射,用x表示这些第一层的输入。假设多元非线性层能逼近复杂的函数2,也就相当于假设它们可以逼近残差函数,例如H(x)-x(假设输入和输出在同一规模)。因此我们非常明确的让这些层近似于残差函数,而并非期待堆叠层近似于H(x)。所以原函数变成了:F(x)+x。尽管两种形式都能逼近期望函数,但它的学习难易度可能不同。
RESNET网络model和文件
最后:AlexNet、VGG、GoogLeNet、ResNet对比
LeNet主要是用于识别10个手写数字的,当然,只要稍加改造也能用在ImageNet数据集上,但效果较差。而本文要介绍的后续模型都是ILSVRC竞赛历年的佼佼者,这里具体比较AlexNet、VGG、GoogLeNet、ResNet四个模型。如下表所示。

图片参考