目标检测算法综述(近20年)
目标检测最新总结文献 :
1《Deep Learning for Generic Object Detection A Survey》 下载地址
2.《Object Detection in 20 Years: A Survey》下载地址
GitHub:下载地址
目标检测是将图像或者视频中的目标与其他不感兴趣区域进行区分,判断是否存在目标,确定目标位置,识别目标种类的计算机视觉任务。
以AlexNet为分界线,2012年之前为传统算法,2013年之后为深度学习算法。

一、目标检测传统算法
包括:
``
1、Viola-Jones算法
2、HOG 特征算法
3 DPM 模型
``
二、 基于深度神经网络的目标检测与识别
2012年, Hinton教授的团队利用卷积神经网络设计了AlexNet,在ImageNet数据集上打败所有传统方法的团队,使得CNN成为计算机视觉领域中最为重要的工具。
基于深度学习的目标检测算法大致分为三类:
1、基于区域建议的算法 如,R-CNN、 Fast R-CNN、Faster R-CNN等。
2、基于目标回归的检测算法,如YOLO、SSD。
3、基于搜索的目标检测与识别算法, AttentionNet,强化学习。

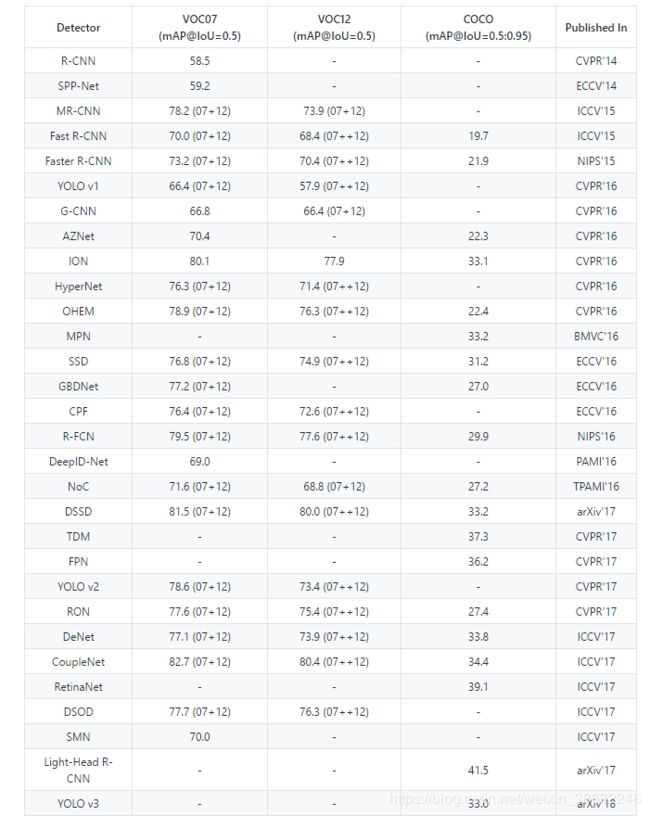
网络性能比较如下:

1.R-CNN 论文地址
代码地址
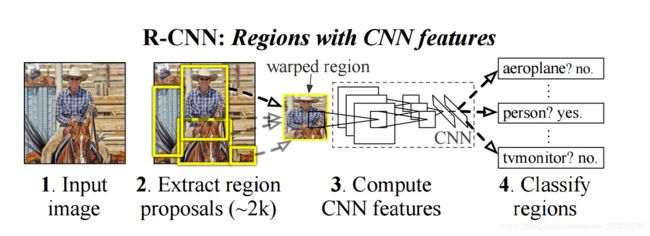
主要思想:
1.输入一张图像
2.(Selective Search)选择性搜索从图像中生成2000个左右的区域建议框。
3.对于每一个区域建议框使用CNN提取特征,并组合特征。
4.使用线性SVM分类器对每个区域建议框分类
5.通过边界框回归算法重新定义目标边界框
局限性:
1.目标候选区域的重叠使CNN特征提取存在很大冗余
2.Fast R-CNN 论文地址
代码地址

主要思想:
1.生成建议窗口,Fast R-CNN用(Selective Search)方法生成建议窗口,每张图片大约2000张。
2.Fast R-CNN将建议窗口映射到CNN的最后一层卷积feature map上
2.使用Softmax预测区域类别概率
3 Smooth L1 Loss 生成边框回归
解决R-CNN问题:
- Fast R-CNN直接将图像归一化后接CNN,然后在最后一层特征图上增加区域建议框,相比R-CNN要将每个区域建议框使用CNN提取特征要节省很多计算量
- R-CNN 在SVM分类之前,把CNN提取的特征存储在硬盘上,读写速度慢造成训练耗时大。Fast R-CNN将训练数据在GPU上直接使用Softmax分类,不需要将大量数据存储在硬盘上
3.Faster R-CNN 论文地址
代码
算法详解(anchor机制)
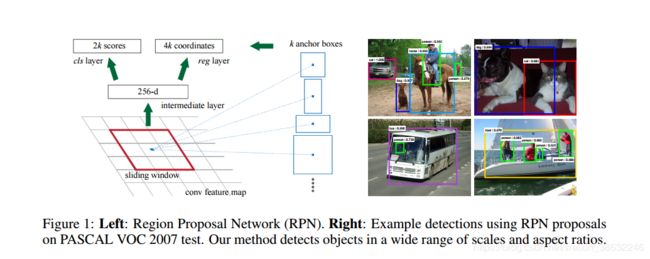
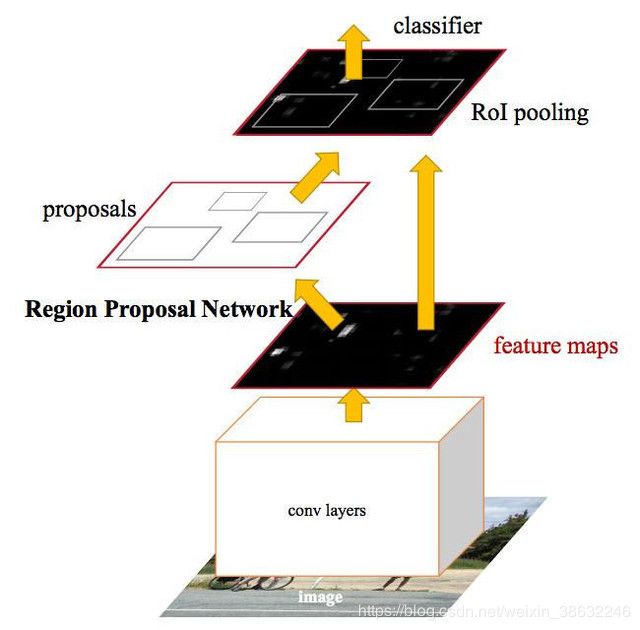
Faster R-CNN 主要采用RPN(Region proposal Network),直接生成建议框,只有300个,RPN和Fast R-CNN部分共享,大幅提升目标检测速度。
主要思想:
1.Faster R-CNN 目标检测分为4个部分(候选区域生成,特征提取,分类,和Bounding box回归)
2.候选区域由RPN完成,其它三个部分沿用Fast R-CNN
4.YOLO v1 论文地址
代码


YOLO算法主要有以下优点:
1.检测速度达到实时帧检测,在Titan X GPU上每秒可检测45帧,快速版每秒能做到150帧
2.YOLO 是对整张图进行检测,采取回归的方式检测目标的位置和类别,是一种全新的检测方式
缺点:
1.定位精度差,没有区域建议算法高,主要由于该算法对图像做回归而不是滑动窗口检测
2.对小目标,或目标之间位置接近的情况下检测效果不好
主要思想:
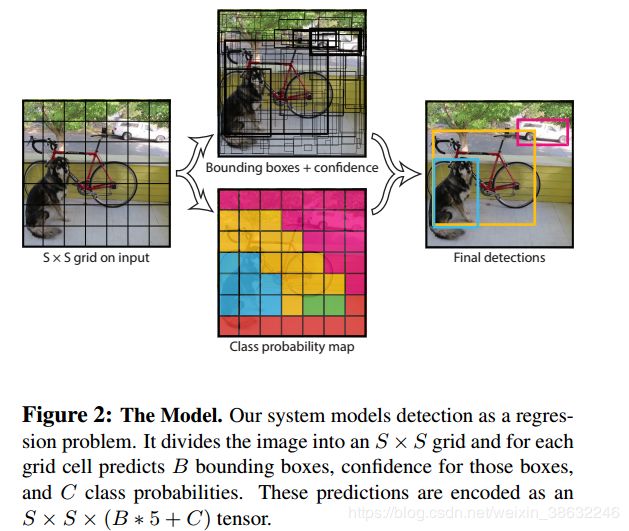
1.将整个图像分成S*S个格子
2.将整张图像送入CNN,预测每一个格子是否存在目标、(预测目标边界框和目标的类别)
3.将预测的边界框做非最大值抑制(NMS),得到最终结果。
5.SSD 论文地址
代码
SSD在YOLO的基础上增加了Faster R-CNN的anchor机制,相当于在回归的基础上增加了区域建议的机制。
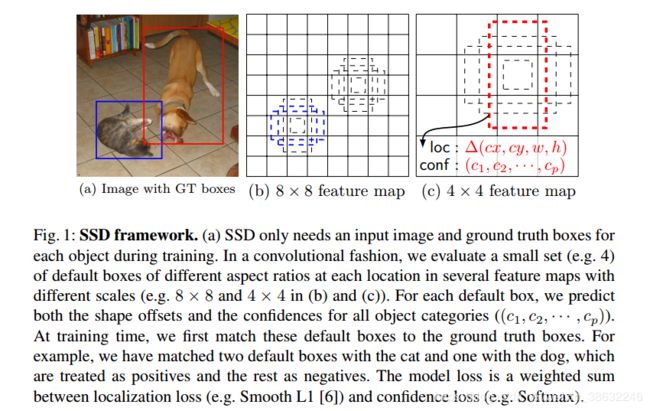
同时SSD从深度神经网络不同层的特征图上提取信息,然后分别用这些特征信息做回归预测目标,相当于引入多尺度操作,能够对一个目标区域做更多的判断。

主要优点:
1.是一种 单次(single shot)检测方法,只需观察一次图像,就可做到多目标检测识别,速度比YOLO快
2.在YOLO的基础上结合了Faster R-CNN的 anchor机制,同时利用不同尺度的特征图预测每个位置上的目标,可以与基于区域建议的方法相比。
3.SSD算法对低分辨率的图像同样能达到较高的检测识别精度
算法流程:
1.通过CNN提取整个图像特征
2.针对不同尺度的深度特征图设计大小不同的特征提取框
3.特征提取框预测目标类别和真实边界
4.NMS筛选最佳预测结果。
6.R-FCN [论文地址]
[代码]


faster R-CNN对卷积层做了共享(RPN和Fast R-CNN),在经过ROI pooling时确没有共享feature map,需要将每一个feature map统一到相同大小,R-FCN建立共享卷积层,只对一个feature map进行卷积,是一个真正的全卷积结构。
算法主要流程:
- 输入一张图到CNN网络
- 经过与预练网络网络后,在最后一个卷积层存在有3个分支,第一个是在feature map上面做RPN网络,得到相应的区域建议框(ROI),第二个分支是在改feature map上得到一个 K 2 ( C + 1 ) K^2(C+1) K2(C+1)维向量做分类,第三个分支在feature map上得到 4 K 2 4K^2 4K2个向量用作Bounding Box回归
- 在 K 2 ( C + 1 ) K^2(C+1) K2(C+1)和 4 K 2 4K^2 4K2两个score map上分别执行position-sensitive pooling 获得最终的类别和位置信息
7.YOLO v2 论文地址
代码
文中提到YOLO V2的改进之处:
- YOLO与Fast R-CNN的误差分析表明,YOLO V1 存在大量的定位误差。此外,与基于区域建议的方法相比,YOLO的召回率相对较低。 YOLO v2 则提出在保持分类精度的同时提高召回率和定位精度。
- 在YOLO V2中对所有卷积层添加批量归一化(Batch Normalization),mAP中得到了2%以上的改进。批处理规范化还有助于对模型进行规范化。
- 原YOLO V1以224×224训练分类器网络,YOLO v2 的分类网络以 448*448 的分辨率先在 ImageNet上进行微调,微调 10 个 epochs,让网络有时间调整滤波器(filters),好让其能更好的运行在新分辨率上,还需要调优用于检测的 Resulting Network。最终通过使用高分辨率,mAP 提升了 4%。
- YOLO V1包含有全连接层,从而能直接预测 Bounding Boxes 的坐标值。 Faster R-CNN 的方法只用卷积层与 Region Proposal Network 来预测 Anchor Box 偏移值与置信度,而不是直接预测坐标值。作者发现通过预测偏移量而不是坐标值能够简化问题. YOLO V2去掉了全连接层,使用 Anchor Boxes 来预测 Bounding Boxes。作者去掉了网络中一个池化层,这让卷积层的输出能有更高的分辨率
- Anchor Box 的尺寸是手动选择的,还有优化的余地。 为了优化,在训练集的 Bounding Boxes 上使用 k-means聚类,来找到一个比较好的值。
- 网络使用一个 Logistic Activation 来对于网络预测结果进行限制,让结果介于 0 到 1 之间。
8.YOLO v3 论文地址
代码

改进之处:
1.多尺度预测
2.更好的基础分类网络(Darknet-53)
3.分类器-类别预测:YOLO v3 不使用 Softmax对每个框进行分类,主要考虑2个因素:a.Softmax使得每个框分配一个类别,而对Open Images这种数据集,目标可能存在重叠上的类别标签
9. M2DNeT: 论文地址
代码

提出了多层次的特征金字塔网络(MLFPN)来构造更有效的特征金字塔来检测不同尺度的目标
未完待续…