JAVA8之Stream并行的基础ForkJoin
java8,首先我们来讲讲ForkJoin的原理,相信很多人都了解这个FrokJoin简单来说就是分而治之的思想,把一个人任务分割成很多小的部分,各个小部分,独立运行,运行在汇总到一块,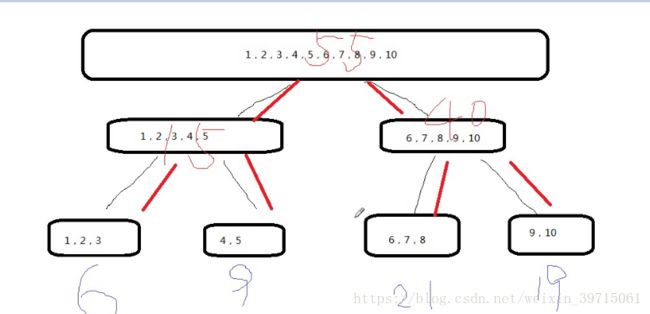
我们看示意图,也就是说吧各个数都拆分开来计算,然后汇总:
FrokJoinTool这个类继承了
ExecutorService
这个类,也就是说跟线程池有点关系,我们在这里学习它的3个API
说一下小需求:要把一组数组对他进行相加:
private static int[] data = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
不废话上代码:
public class AccumulatorRecursiveTask extends RecursiveTask{//继承了RecusiveTask private final int start;//开始 private final int end;//结束 private final int[] data;//传入的值 private final int LIMIT = 3;//把传入的值分每三个运行 //无参构造喽 public AccumulatorRecursiveTask(int start, int end, int[] data) { this.start = start; this.end = end; this.data = data; } //实现接口方法 @Override protected Integer compute() { if ((end - start) <= LIMIT) {//判断如果结束的进去开始的小于规定数的话相加 int result = 0; for (int i = start; i < end; i++) { result += data[i]; } return result; } //ForkJoin的过程 int mid = (start + end) / 2; AccumulatorRecursiveTask left = new AccumulatorRecursiveTask(start, mid, data);//这里的意思是分成两个任务 AccumulatorRecursiveTask right = new AccumulatorRecursiveTask(mid, end, data); left.fork(); Integer rightResult = right.compute(); Integer leftResult = left.join(); //计算出结果 return rightResult + leftResult; } }
测试:
AccumulatorRecursiveTask task = new AccumulatorRecursiveTask(0, data.length, data); ForkJoinPool forkJoinPool = new ForkJoinPool(); Integer result = forkJoinPool.invoke(task); System.out.println("AccumulatorRecursiveTask >>" + result);总结:在数据量大的情况下Forkjoin这种多Cup执行的方式肯定比单CUp执行要快很多
其实stream的很多底层都是拿这种ForkJoin来做的所有的stream的底层都封装了这样的方式,而这样的方式就是Spliterator\
关于Spilter
其实前面说的就是为了介绍这个Spliterator的它是java8里面新加的一个新的接口,就是为了支持Stream的并行工作的
支持stream的切片编程的方式