hadoop部署(单节点)
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
实验环境:
操作系统:redhat6.5 iptables selinux off
hadoop-2.7.3版本,jdk 8版本
Hadoop安装及java环境搭建
解压tar包
[root@server4 ~]# tar xf hadoop-2.7.3.tar.gz -C /usr/local/
[root@server4 ~]# tar xf jdk-8u171-linux-x64.tar.gz -C /usr/local/声明java
[root@server4 ~]# vim /usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_171 独立操作debug
[root@server4 hadoop-2.7.3]# mkdir input
[root@server4 hadoop-2.7.3]# cp etc/hadoop/*.xml input
[root@server4 hadoop-2.7.3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
[root@server4 hadoop-2.7.3]# cat output/*
1 dfsadmin伪分布集群搭建
配置core-site.xml
[root@server4 hadoop-2.7.3]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://172.25.70.4:9000value>
property>
configuration> 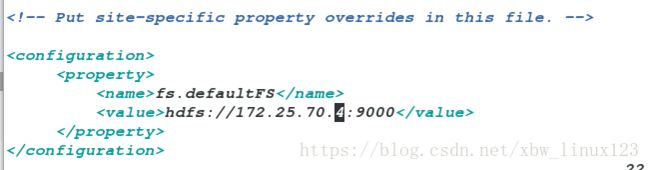
配置hdfs-site.xml
[root@server4 hadoop-2.7.3]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
免密登陆,设置免密
[root@server4 hadoop-2.7.3]# ssh-keygen 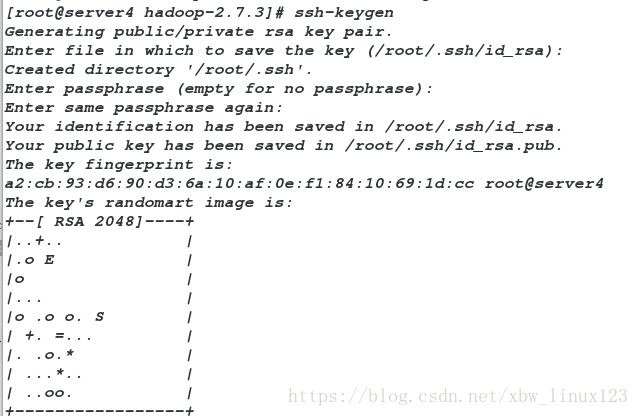
[root@server4 hadoop-2.7.3]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@server4 hadoop-2.7.3]# chmod 600 ~/.ssh/authorized_keys测试
[root@server4 hadoop-2.7.3]# ssh [email protected]
##发现输入yes后可以直接进行ssh连接则成功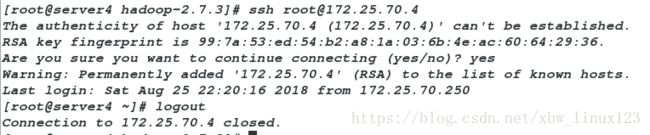
启动hdf
第一次要进行格式化
[root@server4 hadoop-2.7.3]# bin/hdfs namenode -format通过脚本启动
[root@server4 hadoop-2.7.3]# sbin/start-dfs.sh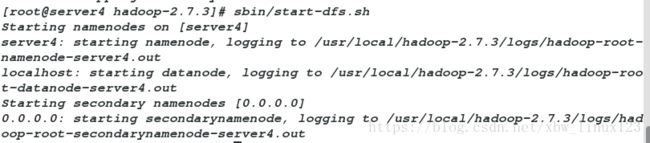
查看端口
[root@server4 hadoop-2.7.3]# netstat -antlp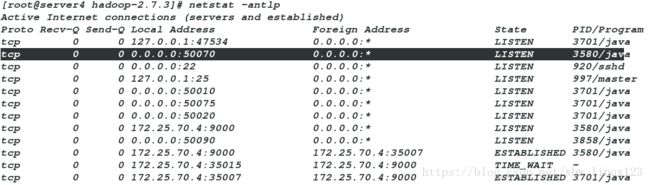
在浏览器测试:
http://172.25.70.4:50070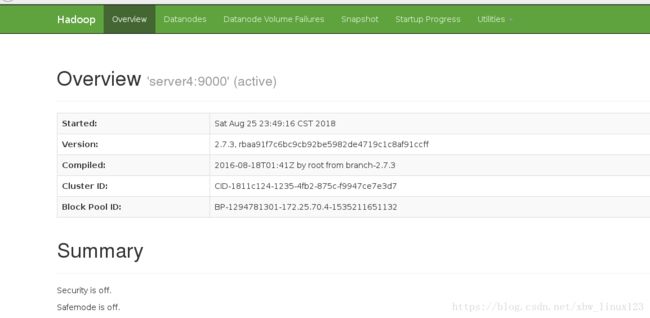
配置java环境
加入环境变量
[root@server4 hadoop-2.7.3]# vim /root/.bash_profile
PATH=$PATH:$HOME/bin:/usr/local/jdk1.8.0_171/bin
[root@server4 hadoop-2.7.3]# source /root/.bash_profile
###刷新一下
通过java命令查看:
如果jps查看不存在,只要进程或者端口开启说明服务也启动成功了
[root@server4 hadoop-2.7.3]# jps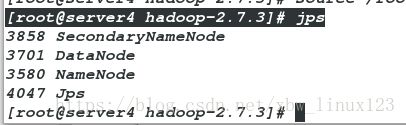
测试:创建目录
[root@server4 hadoop-2.7.3]# bin/hdfs dfs -mkdir /user
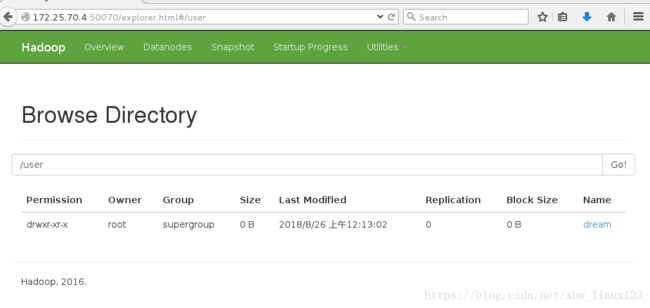
[root@server4 hadoop-2.7.3]# bin/hdfs dfs -mkdir /user/dream在浏览器查看,点击utilities,在点击browse file system:
YARN单节点
配置mapred-site.xml
[root@server4 hadoop-2.7.3]# vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>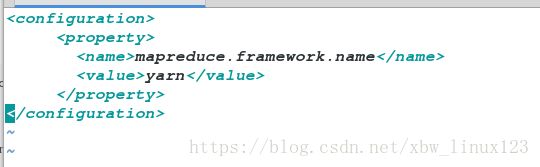
配置yarn-site.xml
[root@server4 hadoop-2.7.3]# vim etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration> 
启动yarn
[root@server4 hadoop-2.7.3]# sbin/start-yarn.sh
###停止的话把start换成stop即可
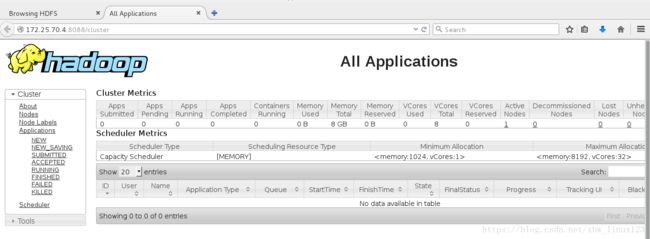
测试:在浏览器访问:
http://172.25.70.4:8088