基于大中台架构的电商业务中台最佳实践之三:交易中台技术要点设计之高性能
接着上篇继续讲,接下来主要介绍交易总体设计的技术要点设计,对于电商中台来说,交易系统是核心中的核心,一开始就需要围绕高性能,高可用,和高扩展三个方面来重点设计。本篇主要介绍高性能设计。
对于高性能的定义,通常可以理解为系统/服务接口响应时间低(rt)且并发量(qps,tps)高. 提高性能的主要策略有:选择合理的分布式事务处理机制,数据库的分库分表,读写分离,异步化,缓存,复杂查询走搜索。
选择合理的分布式事务处理机制
交易业务要求订单,库存,优惠券,红包,支付等数据要强一致,如何保证这些数据之间的一致性是必须要解决的问题,也就是分布式事务的场景。
业界分布式事务的选择方案非常多,每种方案之间的差异性非常大。让我们大概看一下几种常见的方案和其特点:
2PC: 二阶段提交协议,最大几个问题是事务管理器(协调者)和资源管理器(参与者)之间的调用是同步阻塞的,如果在一次事务中只有部分资源管理器进行了commit操作,其他超时或者没有成功,会导致数据的不一致性。
3PC: 三阶段提交协议,是对2PC的改进版本,引入了超时机制,极大的降低了同步阻塞,preCommit 阶段协调者和参与者出现通信问题后,仍然会出现数据不一致性的问题。
TCC: 其实也是2PC的改进版本,TCC将事务参与者从数据库本身提升到了业务服务粒度,让每个业务单元实现try,confirm,cancel三个接口,协调者在调用完try接口会,根据返回接口调用confirm还是cancel,其最大问题是业务侵入性非常强,2PC的单点问题,超时问题也都存在,并且需要业务单元考虑各种异常情况,没法利用数据库的事务机制。
阿里GTS: GTS通过将事务协调器集群化的方式解决了单点问题,但这也带来了另外一个问题,原来本地化的协调者变成了要网络通信的云协调者,如果不是在同一个数据中心,要跨越公网或者专有网络,性能损耗比较大,此外GTS支持的服务框架也是有限的,如果不支持也需要实现类似于TCC的业务接口。
SAGA: 在微服务架构下,关注的人越来越多了,但saga早在1987年就提出来了,基本核心思想Saga是一系列本地交易,每笔事务都会更新单个服务中的数据。第一个事务由系统外部请求启动,然后每个后续步骤由前一个事件完成而触发。其最常见的两种实现方式如下:
1.事件/编排:没有中央协调器,每个服务产生并聆听其他服务的事件,然后采取对应的处理动作。通常会使用消息中间件来实现。
- 命令/协调:中央协调器负责集中处理事件的决策和业务逻辑排序。因引入协调器模式比较重,目前没有好的框架。
对saga要详细理解可以自行google,baidu.
事务消息最终一致性方案:利用消息中间件的事务性消息/两阶段消息来实现,流程如下:
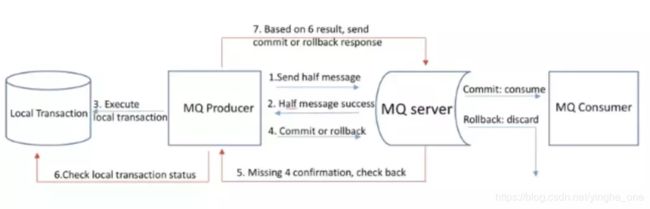
这种模式对业务的侵入性比较比较低,利用消息中间件,性能上有非常好的保障,此外即使遇上网络超时等问题,通过消息中间件的超时回调功能最终都能保证数据的最终一致性。因此我们也选择了这种方案作为我们的实现。以简化的确认下单时序来说明这个场景:
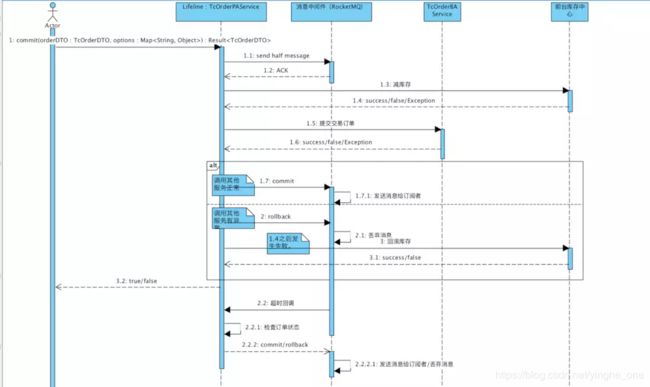
通过时序图可以看出,通过事务消息的2阶段提交和消息的超时回调极大的提升了各个业务数据的一致性,已经是非常不错的方案了,但仔细分析这个图,你还是能发现在极端场景还是有缺点,看个明显的问题:
库存回滚失败:在本地事务回滚的情况下,调用库存系统回滚库存超时或者发生异常,库存数据将会出现不一致情况。对于这种情况需要通过离线或者实时的库存对账系统专门来解决。针对这个问题我们后面可以写一篇文章单独讨论了。
数据库的分库分表
对交易来说,数据量最大的是交易主表和子表,这两个表的数据也是随着业务量增长最快的,需要在一开始,就要考虑分库分表策略,不然等到业务发展到一定量再来调整,会非常痛苦,你会从前到后修改一边,还要迁移数据。对于这块我们总结了一些比较实用的策略,如下:
用商家id取模作为分库分表的字段:这种策略比较适合平台性的公司,如果淘宝,天猫和拼多多。 但对于一些非常大的商家来说,还是会发生数据倾斜的情况。
用买家id取模作为分库分表的字段:这种策略比较试用于自营性的平台,像京东这样的。
自定义分库分表的规则: 大部分的情况,通过上面两种策略就能满足,如果你的业务非常特殊,比如要按照年月日之类的分,那就需要自己写分库分表规则函数来做了。
分库分表的总原则是:利用交易常用的字段作为分库分表的字段,可以联合使用,库和表的数量支持后期修改,对应用代码透明,后期数据库扩容,上层应用无感知,至多调整一下分库分表规则。目前我们利用的是开源mycat来做这块,这块好用的还真不多,很多需要自己做额外工作。
读写分离
读写分离不太适用交易的场景,特别是在并发量非常高的时候,数据库的主备之间通常存在几ms的延迟,搞不好会造成很大的故障。但是为了节省成本,把备库的资源利用起来,对于一些规则确定不会造成问题的查询可以走备库,如:对交易完成数据的查询,对实时性要求不是非常高的运营管理系统和客服系统的查询,都可以切到备库查询。 读写分离也是需要提前考虑,在一开始就需要制定出规范,明确使用不当的后果。现在很多分库分表的框架都可以做到对应用透明的主备读写比例的调整,但业务代码必须要评估哪些场景是不能走备库读的。
异步化
对于核心系统异步化的重要性和带来的好处不用多说,但什么样的场景需要异步化了,就交易来说,像扣减库存,优惠券使用,支付这些核心链路是不能异步化处理,能异步化处理的是在交易时刻就不需要立刻确定的场景。如创建物流订单,佣金计算等。异步化的总体概览图如下:
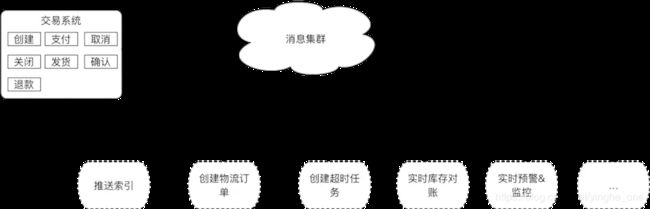
总体原则就是将不在交易核心链路的部分,尽量异步化去处理。
异步化常用的手段就是消息机制和分布式定时任务。
消息机制:首先需要标准化交易事件消息,如交易创建,确认,支付完成等。来看一个样例代码片段:
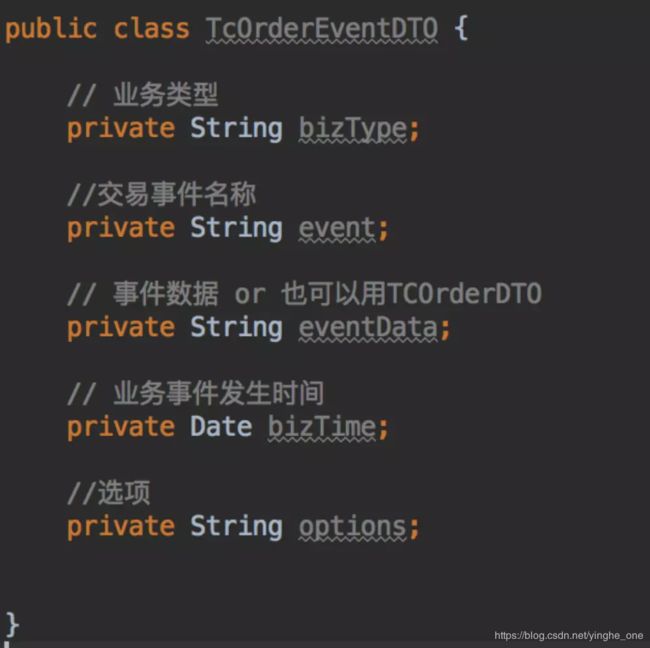
不要每个交易事件,都单独搞个事件对象。发消息到消息中间件时,每个event为一个messageType,同一个topic,为了下游系统只订阅自己感兴趣的少部分数据,可以利用消息中间件的tags之类的机制进行订阅消息过滤。
分布式定时任务:支付超时关闭交易,失败重试,异常交易扫描这些场景适应定时任务,延迟在分钟级别,这块选用开源界比较优秀的框架就可以了,没有必要自己搞。
异步化带来的好处主要是:
将交易系统和非核心系统解耦,从而确保交易的稳定性和响应时间。
帮下游系统削峰,很多下游系统的容量是非常小的,在大促这样的高峰期间,是没有足够的资源跟上交易的处理速度的,消息中间件集群,会起到非常好的缓冲削峰作用,下游系统按照自己的速度消费就可以了,如果下游消费太慢会出现消息堆积,但消息集群本身就是耐堆积的。
缓存
缓存适用于读多写少的场景,但交易是以写为主的场景。所以交易数据本身是没有缓存需求的,但通过前面的核心链路分析可以看出,像交易依赖的商品,优惠,用户这些信息如果直接走DB, 会非常慢,而这些数据是读多写少,是非常适合使用缓存,提高性能的。交易团队需要通过依赖调用关系分析,推动依赖的上下游系统的技术团队,使用缓存技术,做性能提升和可靠性保障。常用的缓存策略有前置缓存和后置缓存。
前置缓存:
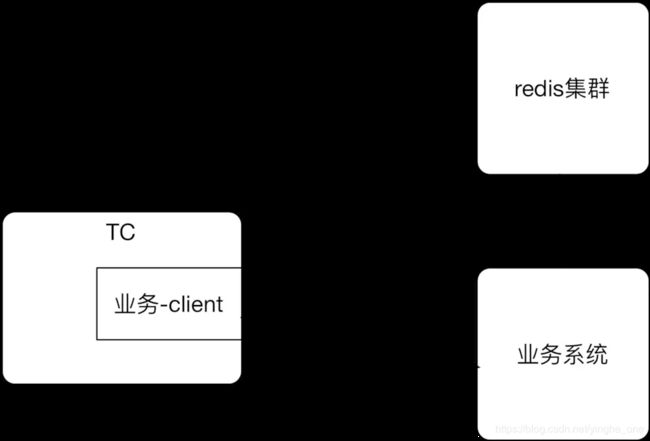
优点:即使业务系统挂了,也没有啥影响,
缺点:后期升级比较麻烦,必须通知依赖client的应用都强制升级。
后者缓存:
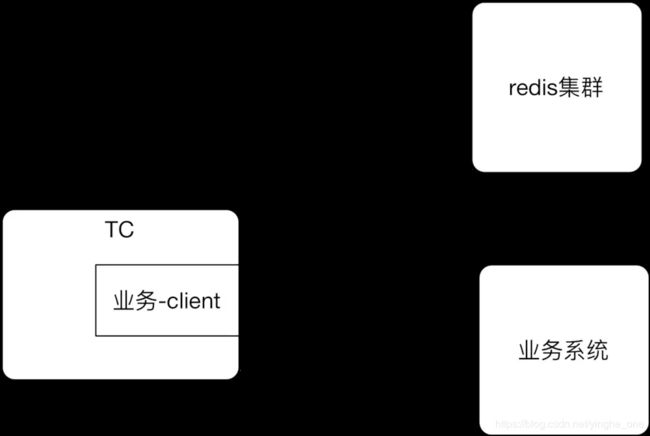
优缺点正好和前置缓存相反。
在实际使用中,如果为了保障非常高的可用性,可以两者结合使用,通过动态配置开关做切换,在client层的代码做一下路由切换处理。
复杂查询走搜索
成熟的电商系统,都有自己单独统一的搜索平台,选择什么样的索引构建方式,完全取决于业务上要多实时的查到最新的数据,目前主流的搜索框架,支持dump DB 和 api 直接推送两种模式。在我们自己的实践中,认为交易数据的实时性非常高,需要在1秒之内完成数据索引的构建。
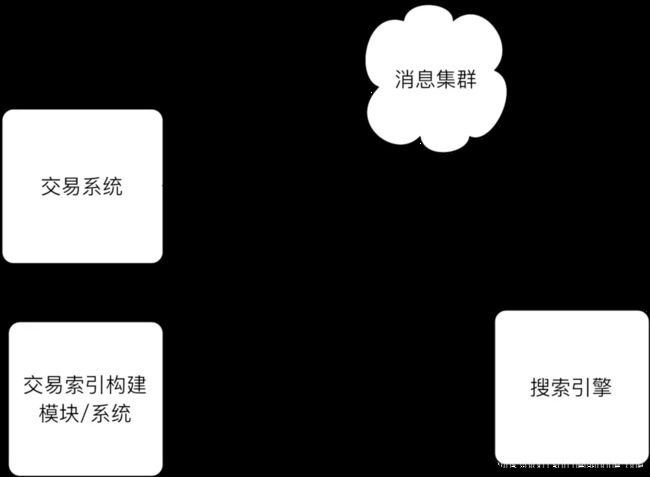
在接受交易事情消息上可以利用批量投递的策略,提升处理能力,。
这块需要特别注意的是消息集群到交易索引的构建系统消息在处理上会出现乱序的问题,必须要通过业务字段做先后次序处理,忽略过期的数据,一般都用业务发生时间bizTime.
在推送索引这块可以利用聚合缓存策略, 减少推送索引的频率,很多搜索框架都对每次推送数据的大小,每秒的推送次数都有限制,需要利用聚合缓存策略来适应选择的搜索框架,总的来说就是不能推的太快,也不来太慢,还要保证所有的索引构建完成在业务允许的范围(1s)之内。
搜索框架的选型非常多:开源的有ElasticSearch,lucene,nutch,solr,solandra. 商业产品的每个云平台都有搜索产品提供,默认推荐 elasticsearch, 如果对搜索结果准确性和智能化程度比较高,使用商业化云产品。
这次就先写这么多,后面接着讲高可用和高扩展的技术要点设计。
对这块有兴趣的欢迎交流技术方案和产品玩法。
更多文章欢迎访问 http://www.apexyun.com/
联系邮箱:[email protected]
(未经同意,请勿转载)