基于模型的推荐算法--基于矩阵分解的协同过滤算法
协同过滤算法在大数据情况下,由于计算量较大,不能做到实时的对用户进行推荐。基于模型的协同过滤算法有效的解决了这一问题,矩阵分解(Matrix Factorization, MF)是基于模型的协同过滤算法中的一种。在基于模型的协同过滤算法中,利用历史数据训练得到模型,并利用该模型实现实时推荐,
![]()
其中,![]() 代表原始的用户-商品矩阵,如下表3,
代表原始的用户-商品矩阵,如下表3,![]() 代表对用户没有评价的商品进行推荐打分后的用户-商品矩阵,如下表4,k是可调参数。更新公式如下:
代表对用户没有评价的商品进行推荐打分后的用户-商品矩阵,如下表4,k是可调参数。更新公式如下:
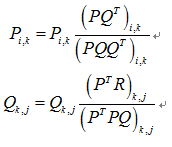
损失函数:
![]()

表3 用户-商品矩阵
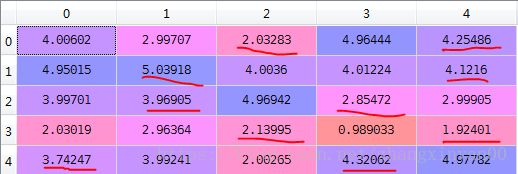
表4 用户-商品矩阵(推荐表)
# coding:UTF-8
'''
@author: zhaozhiyong
Date:20160928
'''
import numpy as np
def load_data(path):
'''导入数据
output: data(mat):用户商品矩阵
input: path(string):用户商品矩阵存储的位置
'''
f = open(path)
lines = line.strip().split("\t")
data = []
for line in f.readlines():
arr = []
arr.append(float(x))
for x in lines:
if x != "-":
else:
return np.mat(data)
arr.append(float(0))
data.append(arr)
input: dataMat(mat):用户商品矩阵
f.close()
def gradAscent(dataMat, k, alpha, beta, maxCycles):
'''利用梯度下降法对矩阵进行分解
k(int):分解矩阵的参数
m, n = np.shape(dataMat)
alpha(float):学习率
beta(float):正则化参数
maxCycles(int):最大迭代次数
output: p,q(mat):分解后的矩阵
for step in range(maxCycles):
'''
# 1、初始化p和q
p = np.mat(np.random.random((m, k)))
q = np.mat(np.random.random((k, n)))
for r in range(k):
# 2、开始训练
for i in range(m):
for j in range(n):
if dataMat[i, j] > 0:
error = dataMat[i, j]
error = error - p[i, r] * q[r, j]
q[r, j] = q[r, j] + alpha * (2 * error * p[i, r] - beta * q[r, j])
for r in range(k):
# 梯度上升
p[i, r] = p[i, r] + alpha * (2 * error * q[r, j] - beta * p[i, r])
loss = 0.0
for i in range(m):
# 3、计算损失函数
for j in range(n):
if dataMat[i, j] > 0:
error = 0.0
for r in range(k):
error = error + p[i, r] * q[r, j]
break
loss = (dataMat[i, j] - error) * (dataMat[i, j] - error)
for r in range(k):
loss = loss + beta * (p[i, r] * p[i, r] + q[r, j] * q[r, j]) / 2
if loss < 0.001:
if step % 1000 == 0:
for i in range(m):
print ("\titer: ", step, " loss: ", loss)
return p, q
def save_file(file_name, source):
source(mat):需要保存的文件
'''保存结果
input: file_name(string):需要保存的文件名
'''
tmp = []
f = open(file_name, "w")
m, n = np.shape(source)
'''
for j in range(n):
tmp.append(str(source[i, j]))
f.write("\t".join(tmp) + "\n")
def prediction(dataMatrix, p, q, user):
f.close()
'''为用户user未互动的项打分
p(mat):分解后的矩阵p
input: dataMatrix(mat):原始用户商品矩阵
q(mat):分解后的矩阵q
k(int):推荐的商品个数
user(int):用户的id
output: predict(list):推荐列表
n = np.shape(dataMatrix)[1]
predict = {}
if dataMatrix[user, j] == 0:
for j in range(n):
predict[j] = (p[user,] * q[:,j])[0,0]
# 按照打分从大到小排序
def top_k(predict, k):
return sorted(predict.items(), key=lambda d:d[1], reverse=True)
'''为用户推荐前k个商品
print ("----------- 1、load data -----------")
input: predict(list):排好序的商品列表
output: top_recom(list):top_k个商品
len_result = len(predict)
'''
top_recom = []
top_recom = predict
if k >= len_result:
else:
top_recom.append(predict[i])
for i in range(k):
return top_recom
dataMatrix = load_data("data.txt")
if __name__ == "__main__":
# 2、利用梯度下降法对矩阵进行分解
# 1、导入用户商品矩阵
print ("----------- 5、top_k recommendation ------------")
print ("----------- 2、training -----------")
p, q = gradAscent(dataMatrix, 10, 0.0002, 0.02, 10000)
# 3、保存分解后的结果
save_file("p", p)
print ("----------- 3、save decompose -----------")
print ("----------- 4、prediction -----------")
save_file("q", q)
# 4、预测
top_recom = top_k(predict, 2)
predict = prediction(dataMatrix, p, q, 0)
# 进行Top-K推荐
print (a)
print (top_recom)
a = p*q
# coding:UTF-8
import numpy as np
from mf import load_data, save_file, prediction, top_k
def train(V, r, maxCycles, e):
m, n = np.shape(V)
H = np.mat(np.random.random((r, n)))
# 1、初始化矩阵
W = np.mat(np.random.random((m, r)))
V_pre = W * H
# 2、非负矩阵分解
for step in range(maxCycles):
E = V - V_pre
for j in range(n):
err = 0.0
for i in range(m):
err += E[i, j] * E[i, j]
print ("\titer: ", step, " loss: " , err)
if err < e:
break
if step % 1000 == 0:
a = W.T * V
if b[i_1, j_1] != 0:
b = W.T * W * H
for i_1 in range(r):
for j_1 in range(n):
d = W * H * H.T
H[i_1, j_1] = H[i_1, j_1] * a[i_1, j_1] / b[i_1, j_1]
c = V * H.T
for i_2 in range(m):
# 1、导入用户商品矩阵
for j_2 in range(r):
if d[i_2, j_2] != 0:
W[i_2, j_2] = W[i_2, j_2] * c[i_2, j_2] / d[i_2, j_2]
return W, H
if __name__ == "__main__":
# 3、保存分解后的结果
print ("----------- 1、load data -----------")
V = load_data("data.txt")
# 2、非负矩阵分解
print ("----------- 2、training -----------")
W, H = train(V, 5, 10000, 1e-5)
# 进行Top-K推荐
print ("----------- 3、save decompose -----------")
save_file("W", W)
save_file("H", H)
predict = prediction(V, W, H, 0)
# 4、预测 print ("----------- 4、prediction -----------")
print (a)
print ("----------- 5、top_k recommendation ------------")
top_recom = top_k(predict, 2)
print (top_recom)
a = W * H