(九) TensorFlow实现VGGNet卷积网络模型
1 模型介绍
VGGNet是2014年 ILSVRC 图像分类竞赛的第二名,其 top-5错误率为 7.3%, 拥有 140M的参数量。相比于该年的第一名 Google的 GoogleNet模型,该模型拥有更强的泛化性,能够适应多种场景应用。
2 模型结构
VGGNet对卷积神经网络的深度与其性能之间的关系进行了探索,网络结构非常简洁。在整个网络中全部使用了大小相同的卷积核(3*3)和最大池化核(2*2)。通过重复堆叠的方式,使用这些卷积层和最大池化层成功地搭建了 11~19 层深的 卷积神经网络。
VGGNet可以分为 A~E 6个级别,如下图所示:
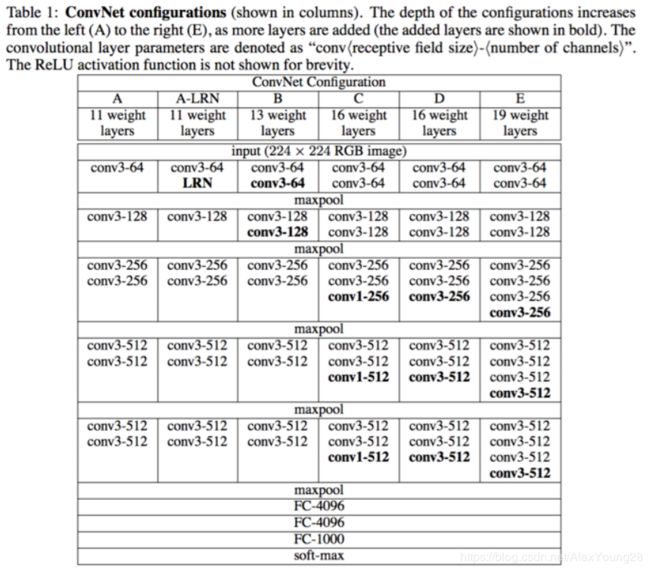
尽管从 A级到 E级对网络逐步进行了加深,但是网络的参数量并没有显著增加,这是因为最后的3个全连接层占据了大量的参数。在6个级别的VGGNet中,全连层都是相同的,卷积层的参数共享和局部连接对降低参数量做出了重大贡献,但是由于卷积操作和池化操作的运算过程比较复杂,所以训练中比较耗时的部分依然是卷积层。
下图战术了每一级别的参数量:
| A | A-LRN | B | C | D | E |
| 133M | 133M | 133M | 134M | 138M | 144M |
从图中可以看出,VGGNet拥有5段卷积,每一段卷积内都有一定数量的卷积层(或1个或4个),所以是5阶段卷积特征提取。每一段卷积之后都有一个max-pool层,这些最大池化层被用来缩小图片的尺寸。
同一段内的卷积层拥有相同的卷积核数,之后每增加一段,该段内卷积层的卷积核数就增长了1倍,接受input的第一段卷积中,每个卷积层拥有最少的64个卷积核,接着第二段卷积中每个卷积层的卷积核数量上升到128个,最后一段卷积拥有最多的卷积层数,每个卷积层拥有最多的512个卷积核。
C级的VGGNet例外,它的第一段和第二段卷积都与B级VGGNet相同,只是在第三段、第四段和第五段卷积中相比B级VGGNet各多了一个1*1大小卷积核的卷积层。这里核1*1的卷积运算主要用于在输入通道数和输出通道数不变的情况下实现线性变换。
将多个3*3卷积核的卷积层堆叠在一起是一种非常有趣也非常有用的设计,这对降低卷积核的参数非常有帮助,同时也会加强CNN对特征的学习能力。
3 TensorFlow 实现
import tensorflow as tf
import math
import time
from datetime import datetime
batch_size = 12
num_batches = 100
#定义卷积操作
def conv_op(input, name, kernel_h, kernel_w, num_out, step_h, step_w, para):
#num_in 是输入的深度,这个参数被用来确定过滤器的输入通道数
num_in = input.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope + "w",shape=[kernel_h,kernel_w,num_in,num_out],dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
conv = tf.nn.conv2d(input, kernel, (1, step_h, step_w, 1),padding="SAME")
biases = tf.Variable(tf.constant(0.0,shape=[num_out],dtype=tf.float32),trainable=True,name="b")
#计算ReLU后的激活值
activation = tf.nn.relu(tf.nn.bias_add(conv, biases),name=scope)
para += [kernel,biases]
return activation
#定义全连操作
def fc_op(input, name, num_out, para):
#num_in为输入单元的数量
num_in = input.get_shape()[-1].value
with tf.name_scope(name) as scope:
weights = tf.get_variable(scope+"w",shape=[num_in,num_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer())
biases = tf.Variable(tf.constant(0.0,shape=[num_out],dtype=tf.float32),trainable=True,name="b")
#tf.nn.relu_layer()函数会同时完成矩阵乘法以加和偏置项并计算ReLU激活值
#这是分步变成的良好替代
activation = tf.nn.relu_layer(input, weights, biases)
para += [weights, biases]
return activation
#定义前向传播的计算过程,Input参数的大小为224*224*3,也即输入的模拟图片数据
def inference_op(input, keep_prob):
parameters = []
#第一段卷积,输出为112*112*64
conv1_1 = conv_op(input, name="conv1_1",kernel_h=3,kernel_w=3,num_out=4,
step_h=1,step_w=1,para=parameters)
conv1_2 = conv_op(conv1_1,name="conv1_2",kernel_w=3,kernel_h=3,num_out=64,
step_h=1,step_w=1,para=parameters)
pool1= tf.nn.max_pool(conv1_1,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool1")
print ("pool1.op.name"," ",pool1.get_shape().as_list())
#第二段卷积
conv2_1 = conv_op(pool1,name="conv2_1",kernel_h=3,kernel_w=3,num_out=128,
step_h=1,step_w=1,para=parameters)
conv2_2 = conv_op(conv2_1,name="conv2_2",kernel_h=3,kernel_w=3,num_out=128,
step_h=1,step_w=1,para=parameters)
pool2 = tf.nn.max_pool(conv2_2,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool2")
print (pool2.op.name," ",pool2.get_shape().as_list())
#第三段卷积
conv3_1 = conv_op(pool2,name="conv3_1",kernel_h=3,kernel_w=3,num_out=256,
step_h=1,step_w=1,para=parameters)
conv3_2 = conv_op(conv3_1,name="conv3_1",kernel_h=3,kernel_w=3,num_out=256,
step_h=1,step_w=1,para=parameters)
conv3_3 = conv_op(conv3_2,name="conv3_3",kernel_h=3,kernel_w=3,num_out=256,
step_h=1,step_w=1,para=parameters)
pool3 = tf.nn.max_pool(conv3_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool3")
print (pool3.op.name," ",pool3.get_shape().as_list())
#第四段卷积,输出大小为14*14*512
conv4_1 = conv_op(pool3,name="conv4_1",kernel_h=3,kernel_w=3,num_out=512,
step_h=1,step_w=1,para=parameters)
conv4_2 = conv_op(conv4_1,name="conv4_2",kernel_h=3,kernel_w=3,num_out=512,
step_h=1,step_w=1,para=parameters)
conv4_3 = conv_op(conv4_2,name="conv4_3",kernel_h=3,kernel_w=3,num_out=512,
step_h=1,step_w=1,para=parameters)
pool4 = tf.nn.max_pool(conv4_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool4")
print (pool4.op.name," ",pool4.get_shape().as_list())
#第五段卷积,输出大小为7*7*512
conv5_1 = conv_op(pool4,name="conv5_1",kernel_h=3,kernel_w=3,num_out=512,
step_h=1,step_w=1,para=parameters)
conv5_2 = conv_op(conv5_1,name="conv5_2",kernel_h=3,kernel_w=3,num_out=512,
step_h=1,step_w=1,para=parameters)
conv5_3 = conv_op(conv5_2,name="conv5_3",kernel_h=3,kernel_w=3,num_out=512,
step_h=1,step_w=1,para=parameters)
pool5 = tf.nn.max_pool(conv5_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME",name="pool5")
print (pool5.op.name," ",pool5.get_shape().as_list())
#pool5的结果汇总为一个向量的形式
pool_shape = pool5.get_shape().as_list()
flattened_shape = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool5, [-1,flattened_shape],name="reshaped")
#第一个全连层
fc_6 = fc_op(reshaped,name="fc_6",num_out=4096,para=parameters)
fc_6_drop = tf.nn.dropout(fc_6, keep_prob, name="fc_6_drop")
#第二个全连层
fc_7 = fc_op(fc_6_drop,name="fc_7",num_out=4096,para=parameters)
fc_7_drop = tf.nn.dropout(fc_7, keep_prob, name="fc_7_drop")
#第三个全连层及softmax层
fc_8 = fc_op(fc_7_drop, name="fc_8", num_out=1000, para=parameters)
softmax = tf.nn.softmax(fc_8)
#prediction模拟了通过argmax()得到预测结果
predictions = tf.argmax(softmax, 1)
return predictions,softmax, fc_8, parameters
with tf.Graph().as_default():
#创建模拟的图片数据
image_size = 224
images = tf.Variable(tf.random_normal([batch_size, image_size,image_size,3],dtype=tf.float32,stddev=1e-1))
#Dropout的keep_prob会根据前向传播或者反向传播而有所不同,在前向传播时,keep_prob=1.0,在反向传播时keep_prob=0.5
keep_prob = tf.placeholder(tf.float32)
#为当前计算图添加前向传播过程
predictions, softmax, fc_8, parameters = inference_op(images, keep_prob)
init_op = tf.global_variables_initializer()
#使用BFC算法确定GPU内存最佳分配策略
config = tf.ConfigProto()
config.gpu_options.allocator_type = "BFC"
with tf.Session(config=config) as sess:
sess.run(init_op)
num_steps_burn_in = 10
total_dura = 0.0
total_dura_squared = 0.0
back_total_dura = 0.0
back_total_dura_squared = 0.0
for i in range(num_batches+num_steps_burn_in):
start_time = time.time()
_ = sess.run(predictions, feed_dict={keep_prob:1.0})
duration = time.time() - start_time
if i >= num_steps_burn_in:
if i % 10 == 0:
print ("%s step %d, duration = %.3f" %
(datetime.now(),i-num_steps_burn_in,duration))
total_dura += duration
total_dura_squared += duration * duration
average_time = total_dura / num_batches
print ("%s: Forward across %d steps, %.3f +/- %.3f sec/batch" %
(datetime.now(),num_batches,average_time,math.sqrt(total_dura_squared/num_batches-average_time*average_time)))
#print (parameters)
#定义求解梯度的操作
grad = tf.gradients(tf.nn.l2_loss(fc_8),parameters)
print (type(grad))
#运行反向传播测试过程
for i in range(num_batches+num_steps_burn_in):
start_time = time.time()
_ = sess.run(grad, feed_dict={keep_prob:0.5})
duration = time.time() - start_time
if i >= num_steps_burn_in:
if i % 10 ==0:
print ("%s step %d, duration = %.3f" %
(datetime.now(), i - num_steps_burn_in, duration))
back_total_dura +=duration
back_total_dura_squared += duration * duration
back_avg_t = back_total_dura / num_batches
#打印反向传播的运算时间
print ("%s: Forward-bakcward across %d steps, %.3f +/- %.3f sec/batch" %
(datetime.now(), num_batches, back_avg_t,
math.sqrt(back_total_dura_squared / num_batches - back_avg_t * back_avg_t)))