模型评估和超参数调整(四)——网格搜索(grid search)
读《python machine learning》chapt 6
Learning Best Practices for Model Evaluation and Hyperparameter Tuning
【主要内容】
(1)获得对模型评估的无偏估计
(2)诊断机器学习算法的常见问题
(3)调整机器学习模型
(4)使用不同的性能指标对评估预测模型
git源码地址 https://github.com/xuman-Amy/Model-evaluation-and-Hypamameter-tuning
【超参数选择——grid search 】
【主要功能】
grid search :用于超参数优化,通过优化超参数之间的最优组合来改善模型性能。
【主要思想】
暴风搜索法,首先为不同的超参数设定一个值列表,然后计算机会遍历每个超参数的组合进行性能评估,选出性能最佳的参数组合。
【sklearn 实现 网格搜索】
# grid search
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
pipe_svc = make_pipeline(StandardScaler(),
SVC(random_state = 1))
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = [{'svc__C' : param_range,
'svc__kernel' : ['linear']},
{'svc__C' : param_range,
'svc__kernel': ['rbf'],
'svc__gamma' : param_range}]
gs = GridSearchCV(estimator = pipe_svc,
param_grid = param_grid,
scoring = 'accuracy',
cv = 10,
n_jobs = 1)
gs.fit(X_train, y_train)
print(gs.best_score_)
print(gs.best_params_)
最后用测试集进行最后的模型评估。
【算法选择——嵌套交叉验证】
在不同的机器学习算法中选择最优算法,较常用的是嵌套交叉验证法。
【nested cross validation】
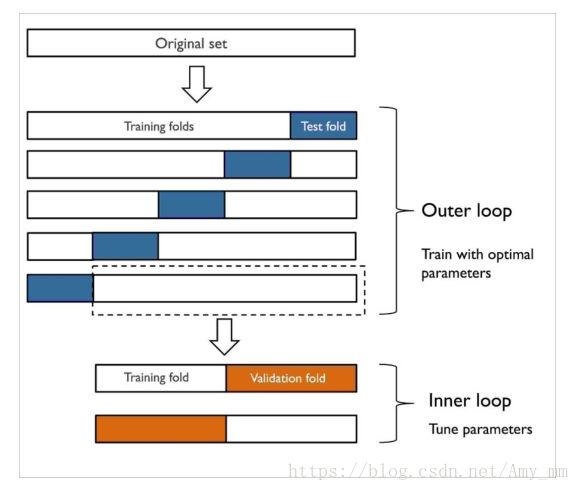
外循环:利用k-foldCV切分训练集和测试集
内循环:利用k-fold,在训练集上进行模型选择
在模型选择完后,利用测试集进行模型评估。
比较常用的是外循环五层,内循环两层。示意图如下:
【sklearn 实现 nested CV】
# nested CV
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))![]()
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}],
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))![]()