CNN进行新闻文本分类代码实战,包含分类文本
依次运行三个文件:
cnews_loader.py
cnn_model.py
run_cnn.py
cnews新闻文件夹下载路径:链接:https://pan.baidu.com/s/1H3K94E7JGJdIrGuTKBXvIg 密码:fmdq
他们放在一个文件夹中,运行细节看每个文件说明。
来源:https://github.com/BTUJACK/text-classification-cnn-rnn
cnews_loader.py
为数据的预处理文件。
# coding: utf-8
#3.7运行OK
'''
cnews_loader.py为数据的预处理文件。
read_file(): 读取文件数据;
build_vocab(): 构建词汇表,使用字符级的表示,这一函数会将词汇表存储下来,避免每一次重复处理;
read_vocab(): 读取上一步存储的词汇表,转换为{词:id}表示;
read_category(): 将分类目录固定,转换为{类别: id}表示;
to_words(): 将一条由id表示的数据重新转换为文字;
process_file(): 将数据集从文字转换为固定长度的id序列表示;
batch_iter(): 为神经网络的训练准备经过shuffle的批次的数据。
经过数据预处理,数据的格式如下:
Data Shape Data Shape
x_train [50000, 600] y_train [50000, 10]
x_val [5000, 600] y_val [5000, 10]
x_test [10000, 600] y_test [10000, 10]
'''
import sys
from collections import Counter
import numpy as np
import tensorflow.contrib.keras as kr
if sys.version_info[0] > 2:
is_py3 = True
else:
reload(sys)
sys.setdefaultencoding("utf-8")
is_py3 = False
def native_word(word, encoding='utf-8'):
"""如果在python2下面使用python3训练的模型,可考虑调用此函数转化一下字符编码"""
if not is_py3:
return word.encode(encoding)
else:
return word
def native_content(content):
if not is_py3:
return content.decode('utf-8')
else:
return content
def open_file(filename, mode='r'):
"""
常用文件操作,可在python2和python3间切换.
mode: 'r' or 'w' for read or write
"""
if is_py3:
return open(filename, mode, encoding='utf-8', errors='ignore')
else:
return open(filename, mode)
def read_file(filename):
"""读取文件数据"""
contents, labels = [], []
with open_file(filename) as f:
for line in f:
try:
label, content = line.strip().split('\t')
if content:
contents.append(list(native_content(content)))
labels.append(native_content(label))
except:
pass
return contents, labels
def build_vocab(train_dir, vocab_dir, vocab_size=5000):
"""根据训练集构建词汇表,存储"""
data_train, _ = read_file(train_dir)
all_data = []
for content in data_train:
all_data.extend(content)
counter = Counter(all_data)
count_pairs = counter.most_common(vocab_size - 1)
words, _ = list(zip(*count_pairs))
# 添加一个 来将所有文本pad为同一长度
words = [''] + list(words)
open_file(vocab_dir, mode='w').write('\n'.join(words) + '\n')
def read_vocab(vocab_dir):
"""读取词汇表"""
# words = open_file(vocab_dir).read().strip().split('\n')
with open_file(vocab_dir) as fp:
# 如果是py2 则每个值都转化为unicode
words = [native_content(_.strip()) for _ in fp.readlines()]
word_to_id = dict(zip(words, range(len(words))))
return words, word_to_id
def read_category():
"""读取分类目录,固定"""
categories = ['体育', '财经', '房产', '家居', '教育', '科技', '时尚', '时政', '游戏', '娱乐']
categories = [native_content(x) for x in categories]
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
def to_words(content, words):
"""将id表示的内容转换为文字"""
return ''.join(words[x] for x in content)
def process_file(filename, word_to_id, cat_to_id, max_length=600):
"""将文件转换为id表示"""
contents, labels = read_file(filename)
data_id, label_id = [], []
for i in range(len(contents)):
data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id])
label_id.append(cat_to_id[labels[i]])
# 使用keras提供的pad_sequences来将文本pad为固定长度
x_pad = kr.preprocessing.sequence.pad_sequences(data_id, max_length)
y_pad = kr.utils.to_categorical(label_id, num_classes=len(cat_to_id)) # 将标签转换为one-hot表示
return x_pad, y_pad
def batch_iter(x, y, batch_size=64):
"""生成批次数据"""
data_len = len(x)
num_batch = int((data_len - 1) / batch_size) + 1
indices = np.random.permutation(np.arange(data_len))
x_shuffle = x[indices]
y_shuffle = y[indices]
for i in range(num_batch):
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len)
yield x_shuffle[start_id:end_id], y_shuffle[start_id:end_id]
cnn_model.py
模型文件
# coding: utf-8
'''
CNN卷积神经网络
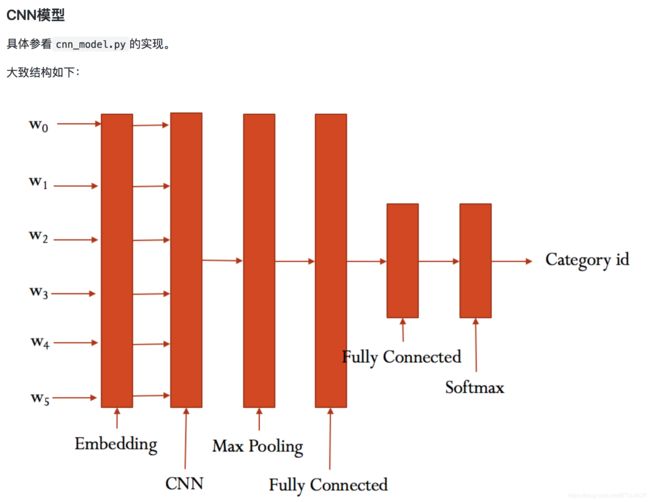
CNN模型
Embedding, CNN, max pooling, fully connected, fully connected, softmax, category id.
具体参看cnn_model.py的实现。
配置项
CNN可配置的参数如下所示,在cnn_model.py中。
class TCNNConfig(object):
"""CNN配置参数"""
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
num_filters = 128 # 卷积核数目
kernel_size = 5 # 卷积核尺寸
vocab_size = 5000 # 词汇表达小
hidden_dim = 128 # 全连接层神经元
dropout_keep_prob = 0.5 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
'''
import tensorflow as tf
class TCNNConfig(object):
"""CNN配置参数"""
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
num_filters = 256 # 卷积核数目
kernel_size = 5 # 卷积核尺寸
vocab_size = 5000 # 词汇表达小
hidden_dim = 128 # 全连接层神经元
dropout_keep_prob = 0.5 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
class TextCNN(object):
"""文本分类,CNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.cnn()
def cnn(self):
"""CNN模型"""
# 词向量映射
with tf.device('/cpu:0'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("cnn"):
# CNN layer
conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv')
# global max pooling layer
gmp = tf.reduce_max(conv, reduction_indices=[1], name='gmp')
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(gmp, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
run_cnn.py
运行文件
训练与验证
终端运行 python3.5 run_cnn.py train,可以开始训练。
若之前进行过训练,请把tensorboard/textcnn删除,避免TensorBoard多次训练结果重叠。
测试
终端运行 python3.5 run_cnn.py test 在测试集上进行测试。
Python3.7运行会报错,说self在定义前就使用了。Python3.5就没有这个报错。
注意修改路径:
base_dir = '/Users/apple/Documents/ST/python/python项目/CNN_RNN_text_classification/cnews'
save_dir = '/Users/apple/Documents/ST/python/python项目/CNN_RNN_text_classification/checkpoints/textcnn'
cnews新闻文件夹下载路径:链接:https://pan.baidu.com/s/1H3K94E7JGJdIrGuTKBXvIg 密码:fmdq
cnews下载好和其他文件放一一起。
以下内容来自:链接:https://pan.baidu.com/s/1PstPh6d-cx5mlMOZF8KMEg 密码:5ikj
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
训练与验证
终端运行 python3.5 run_cnn.py train,可以开始训练。
若之前进行过训练,请把tensorboard/textcnn删除,避免TensorBoard多次训练结果重叠。
测试
终端运行 python3.5 run_cnn.py test 在测试集上进行测试。
Python3.7运行会报错,说self在定义前就使用了。Python3.5就没有这个报错。
注意修改路径:
base_dir = '/Users/apple/Documents/ST/python/python项目/CNN_RNN_text_classification/cnews'
save_dir = '/Users/apple/Documents/ST/python/python项目/CNN_RNN_text_classification/checkpoints/textcnn'
cnews文件夹下载路径:链接:https://pan.baidu.com/s/1H3K94E7JGJdIrGuTKBXvIg 密码:fmdq
'''
from __future__ import print_function
import os
import sys
import time
from datetime import timedelta
import numpy as np
import tensorflow as tf
from sklearn import metrics
from cnn_model import TCNNConfig, TextCNN
from data.cnews_loader import read_vocab, read_category, batch_iter, process_file, build_vocab
#base_dir = 'data/cnews'
base_dir = '/Users/apple/Documents/ST/python/python项目/CNN_RNN_text_classification/cnews'
train_dir = os.path.join(base_dir, 'cnews.train.txt')
test_dir = os.path.join(base_dir, 'cnews.test.txt')
val_dir = os.path.join(base_dir, 'cnews.val.txt')
vocab_dir = os.path.join(base_dir, 'cnews.vocab.txt')
save_dir = '/Users/apple/Documents/ST/python/python项目/CNN_RNN_text_classification/checkpoints/textcnn'
save_path = os.path.join(save_dir, 'best_validation') # 最佳验证结果保存路径
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
def feed_data(x_batch, y_batch, keep_prob):
feed_dict = {
model.input_x: x_batch,
model.input_y: y_batch,
model.keep_prob: keep_prob
}
return feed_dict
def evaluate(sess, x_, y_):
"""评估在某一数据上的准确率和损失"""
data_len = len(x_)
batch_eval = batch_iter(x_, y_, 128)
total_loss = 0.0
total_acc = 0.0
for x_batch, y_batch in batch_eval:
batch_len = len(x_batch)
feed_dict = feed_data(x_batch, y_batch, 1.0)
loss, acc = sess.run([model.loss, model.acc], feed_dict=feed_dict)
total_loss += loss * batch_len
total_acc += acc * batch_len
return total_loss / data_len, total_acc / data_len
def train():
print("Configuring TensorBoard and Saver...")
# 配置 Tensorboard,重新训练时,请将tensorboard文件夹删除,不然图会覆盖
tensorboard_dir = 'tensorboard/textcnn'
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
tf.summary.scalar("loss", model.loss)
tf.summary.scalar("accuracy", model.acc)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
# 配置 Saver
saver = tf.train.Saver()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print("Loading training and validation data...")
# 载入训练集与验证集
start_time = time.time()
x_train, y_train = process_file(train_dir, word_to_id, cat_to_id, config.seq_length)
x_val, y_val = process_file(val_dir, word_to_id, cat_to_id, config.seq_length)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# 创建session
session = tf.Session()
session.run(tf.global_variables_initializer())
writer.add_graph(session.graph)
print('Training and evaluating...')
start_time = time.time()
total_batch = 0 # 总批次
best_acc_val = 0.0 # 最佳验证集准确率
last_improved = 0 # 记录上一次提升批次
require_improvement = 1000 # 如果超过1000轮未提升,提前结束训练
flag = False
for epoch in range(config.num_epochs):
print('Epoch:', epoch + 1)
batch_train = batch_iter(x_train, y_train, config.batch_size)
for x_batch, y_batch in batch_train:
feed_dict = feed_data(x_batch, y_batch, config.dropout_keep_prob)
if total_batch % config.save_per_batch == 0:
# 每多少轮次将训练结果写入tensorboard scalar
s = session.run(merged_summary, feed_dict=feed_dict)
writer.add_summary(s, total_batch)
if total_batch % config.print_per_batch == 0:
# 每多少轮次输出在训练集和验证集上的性能
feed_dict[model.keep_prob] = 1.0
loss_train, acc_train = session.run([model.loss, model.acc], feed_dict=feed_dict)
loss_val, acc_val = evaluate(session, x_val, y_val) # todo
if acc_val > best_acc_val:
# 保存最好结果
best_acc_val = acc_val
last_improved = total_batch
saver.save(sess=session, save_path=save_path)
improved_str = '*'
else:
improved_str = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>6.2}, Train Acc: {2:>7.2%},' \
+ ' Val Loss: {3:>6.2}, Val Acc: {4:>7.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss_train, acc_train, loss_val, acc_val, time_dif, improved_str))
session.run(model.optim, feed_dict=feed_dict) # 运行优化
total_batch += 1
if total_batch - last_improved > require_improvement:
# 验证集正确率长期不提升,提前结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break # 跳出循环
if flag: # 同上
break
def test():
print("Loading test data...")
start_time = time.time()
x_test, y_test = process_file(test_dir, word_to_id, cat_to_id, config.seq_length)
session = tf.Session()
session.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess=session, save_path=save_path) # 读取保存的模型
print('Testing...')
loss_test, acc_test = evaluate(session, x_test, y_test)
msg = 'Test Loss: {0:>6.2}, Test Acc: {1:>7.2%}'
print(msg.format(loss_test, acc_test))
batch_size = 128
data_len = len(x_test)
num_batch = int((data_len - 1) / batch_size) + 1
y_test_cls = np.argmax(y_test, 1)
y_pred_cls = np.zeros(shape=len(x_test), dtype=np.int32) # 保存预测结果
for i in range(num_batch): # 逐批次处理
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len)
feed_dict = {
model.input_x: x_test[start_id:end_id],
model.keep_prob: 1.0
}
y_pred_cls[start_id:end_id] = session.run(model.y_pred_cls, feed_dict=feed_dict)
# 评估
print("Precision, Recall and F1-Score...")
print(metrics.classification_report(y_test_cls, y_pred_cls, target_names=categories))
# 混淆矩阵
print("Confusion Matrix...")
cm = metrics.confusion_matrix(y_test_cls, y_pred_cls)
print(cm)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
if __name__ == '__main__':
if len(sys.argv) != 2 or sys.argv[1] not in ['train', 'test']:
raise ValueError("""usage: python run_cnn.py [train / test]""")
print('Configuring CNN model...')
config = TCNNConfig()
if not os.path.exists(vocab_dir): # 如果不存在词汇表,重建
build_vocab(train_dir, vocab_dir, config.vocab_size)
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_dir)
config.vocab_size = len(words)
model = TextCNN(config)
if sys.argv[1] == 'train':
train()
else:
test()
'''
16G内存和512G硬盘的苹果电脑CPU运行如下:
建议用GPU跑,要不然普通电脑太慢了
appledeMBP:CNN_RNN_text_classification apple$ python3.5 run_cnn.py train
Configuring CNN model...
Configuring TensorBoard and Saver...
Loading training and validation data...
Time usage: 0:00:18
2018-11-25 08:52:08.149886: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2018-11-25 08:52:08.149909: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2018-11-25 08:52:08.149925: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2018-11-25 08:52:08.149930: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 2.3, Train Acc: 7.81%, Val Loss: 2.3, Val Acc: 9.44%, Time: 0:00:08 *
Iter: 100, Train Loss: 0.79, Train Acc: 81.25%, Val Loss: 0.99, Val Acc: 69.72%, Time: 0:01:21 *
Iter: 200, Train Loss: 0.36, Train Acc: 89.06%, Val Loss: 0.65, Val Acc: 81.68%, Time: 0:02:34 *
Iter: 300, Train Loss: 0.34, Train Acc: 90.62%, Val Loss: 0.42, Val Acc: 88.58%, Time: 0:03:44 *
Iter: 400, Train Loss: 0.28, Train Acc: 90.62%, Val Loss: 0.37, Val Acc: 89.48%, Time: 0:04:54 *
Iter: 500, Train Loss: 0.25, Train Acc: 93.75%, Val Loss: 0.3, Val Acc: 92.16%, Time: 0:06:05 *
Iter: 600, Train Loss: 0.33, Train Acc: 89.06%, Val Loss: 0.31, Val Acc: 91.16%, Time: 0:07:17
Iter: 700, Train Loss: 0.087, Train Acc: 96.88%, Val Loss: 0.28, Val Acc: 91.70%, Time: 0:08:30
Epoch: 2
Iter: 800, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.27, Val Acc: 91.68%, Time: 0:09:40
Iter: 900, Train Loss: 0.031, Train Acc: 98.44%, Val Loss: 0.22, Val Acc: 93.68%, Time: 0:10:51 *
Iter: 1000, Train Loss: 0.15, Train Acc: 93.75%, Val Loss: 0.23, Val Acc: 93.64%, Time: 0:12:04
Iter: 1100, Train Loss: 0.2, Train Acc: 95.31%, Val Loss: 0.24, Val Acc: 92.46%, Time: 0:13:15
Iter: 1200, Train Loss: 0.048, Train Acc: 100.00%, Val Loss: 0.19, Val Acc: 95.02%, Time: 0:14:26 *
Iter: 1300, Train Loss: 0.08, Train Acc: 96.88%, Val Loss: 0.2, Val Acc: 94.60%, Time: 0:15:37
Iter: 1400, Train Loss: 0.14, Train Acc: 95.31%, Val Loss: 0.24, Val Acc: 92.78%, Time: 0:16:47
Iter: 1500, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.22, Val Acc: 94.36%, Time: 0:17:57
Epoch: 3
Iter: 1600, Train Loss: 0.049, Train Acc: 98.44%, Val Loss: 0.2, Val Acc: 94.72%, Time: 0:19:07
Iter: 1700, Train Loss: 0.13, Train Acc: 96.88%, Val Loss: 0.23, Val Acc: 92.84%, Time: 0:20:22
Iter: 1800, Train Loss: 0.062, Train Acc: 98.44%, Val Loss: 0.19, Val Acc: 94.98%, Time: 0:21:35
Iter: 1900, Train Loss: 0.031, Train Acc: 100.00%, Val Loss: 0.22, Val Acc: 93.82%, Time: 0:22:48
Iter: 2000, Train Loss: 0.094, Train Acc: 95.31%, Val Loss: 0.24, Val Acc: 93.66%, Time: 0:23:59
Iter: 2100, Train Loss: 0.063, Train Acc: 96.88%, Val Loss: 0.22, Val Acc: 94.10%, Time: 0:25:11
Iter: 2200, Train Loss: 0.049, Train Acc: 98.44%, Val Loss: 0.24, Val Acc: 92.64%, Time: 0:26:21
No optimization for a long time, auto-stopping...
appledeMBP:CNN_RNN_text_classification apple$
'''
测试
运行 python run_cnn.py test 在测试集上进行测试。输出:
在测试集上的准确率达到了96.04%,且各类的precision, recall和f1-score都超过了0.9。
从混淆矩阵也可以看出分类效果非常优秀。
认识你是我们的缘分,同学,等等,学习人工智能,记得关注我。

微信扫一扫
关注该公众号
《湾区人工智能》
回复《人生苦短,我用Python》便可以获取下面的超高清电子书和代码

Configuring CNN model...
Loading test data...
Testing...
Test Loss: 0.14, Test Acc: 96.04%
Precision, Recall and F1-Score...
precision recall f1-score support
体育 0.99 0.99 0.99 1000
财经 0.96 0.99 0.97 1000
房产 1.00 1.00 1.00 1000
家居 0.95 0.91 0.93 1000
教育 0.95 0.89 0.92 1000
科技 0.94 0.97 0.95 1000
时尚 0.95 0.97 0.96 1000
时政 0.94 0.94 0.94 1000
游戏 0.97 0.96 0.97 1000
娱乐 0.95 0.98 0.97 1000
avg / total 0.96 0.96 0.96 10000
Confusion Matrix...
[[991 0 0 0 2 1 0 4 1 1]
[ 0 992 0 0 2 1 0 5 0 0]
[ 0 1 996 0 1 1 0 0 0 1]
[ 0 14 0 912 7 15 9 29 3 11]
[ 2 9 0 12 892 22 18 21 10 14]
[ 0 0 0 10 1 968 4 3 12 2]
[ 1 0 0 9 4 4 971 0 2 9]
[ 1 16 0 4 18 12 1 941 1 6]
[ 2 4 1 5 4 5 10 1 962 6]
[ 1 0 1 6 4 3 5 0 1 979]]
Time usage: 0:00:05