基于深度学习的文本情感分析(Keras VS Pytorch)
实验任务:利用不同的深度学习框架对微博短文本进行情感分析,并将情感分为三类,分别是正、负、中。
所用语言及相应的工具包:Python 3.6, Keras 2.2.4, Torch 1.0.1
数据分布: {'pos': 712, 'neu': 768, 'neg': 521}
技术路线:
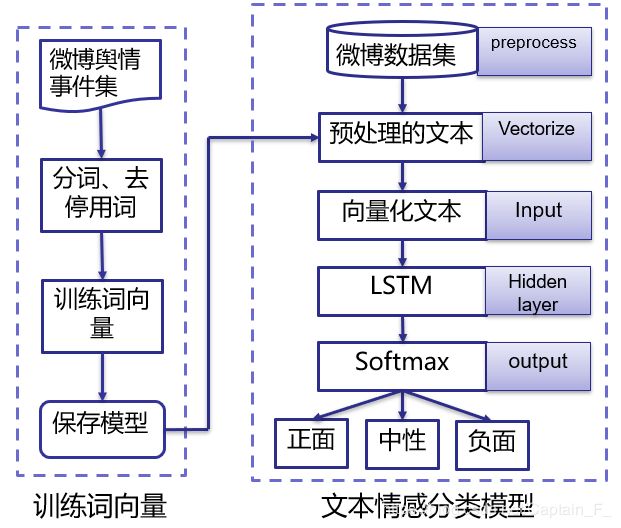
本次实验利用词向量来表示文本,单条文本的形状为[50, 100].
利用Keras对处理好的文本进行情感识别:
import pickle
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Bidirectional, LSTM, GRU
from keras.callbacks import TensorBoard
def load_f(path):
with open(path, 'rb')as f:
data = pickle.load(f)
return data
path_1 = r'G:/Multimodal/nlp/w2v_weibo_data.pickle'
path_2 = r'G:/Multimodal/labels.pickle'
txts = load_f(path_1)
labels = load_f(path_2)
train_X, test_X, train_Y, test_Y = train_test_split(txts, labels, test_size= 0.2, random_state= 46)
#build model;
tensorboard = TensorBoard(log_dir= r'G:\pytorch')
model = Sequential()
model.add(LSTM(128, input_shape = (None, 100)))
#model.add(GRU(128, input_shape = (None, 100)))
model.add(Dense(3, activation= 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(train_X, train_Y, epochs= 50, validation_data = (test_X, test_Y),
batch_size= 128, verbose= 1, callbacks= [tensorboard])
y_pre = model.predict(test_X, batch_size= 128)
print(classification_report(test_Y.argmax(axis= 1), y_pre.argmax(axis= 1), digits= 5))
训练后的结果:

利用Pytorch对处理好的文本进行情感识别:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import pickle
from sklearn.model_selection import train_test_split
import torch.utils.data as U
from tqdm import tqdm
from sklearn.metrics import accuracy_score, classification_report
#define Hyper parameters;
Input_size = 100
Hidden_size = 128
Epochs = 50
batch_size = 128
class lstm(nn.Module):
def __init__(self):
super(lstm, self).__init__()
self.lstm = nn.LSTM(
input_size=Input_size,
hidden_size=Hidden_size,
batch_first=True)
self.fc = nn.Linear(128, 3)
def forward(self, x):
out, (h_0, c_0) = self.lstm(x)
out = out[:, -1, :]
out = self.fc(out)
out = F.softmax(out, dim= 1)
return out, h_0
model = lstm()
optimizer = torch.optim.Adam(model.parameters())
def load_f(path):
with open(path, 'rb')as f:
data = pickle.load(f)
return data
path_1 = r'G:/Multimodal/nlp/w2v_weibo_data.pickle'
path_2 = r'G:/Multimodal/labels.pickle'
txts = load_f(path_1)
labels = load_f(path_2)
train_X, test_X, train_Y, test_Y = train_test_split(txts, labels, test_size= 0.2, random_state= 46)
train_Y = train_Y.argmax(axis=1)
test_Y = test_Y.argmax(axis=1)
train_X = torch.from_numpy(train_X)
train_Y = torch.from_numpy(train_Y)
test_X = torch.from_numpy(test_X)
test_Y = torch.from_numpy(test_Y)
train_data = U.TensorDataset(train_X, train_Y)
test_data = U.TensorDataset(test_X, test_Y)
train_loader = U.DataLoader(train_data, batch_size= batch_size, shuffle=True)
test_loader = U.DataLoader(test_data, batch_size= batch_size, shuffle=False)
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output, h_state = model(data)
labels = output.argmax(dim= 1)
acc = accuracy_score(target, labels)
#梯度清零;反向传播;
optimizer.zero_grad()
loss = F.cross_entropy(output, target)#交叉熵损失函数;
loss.backward()
optimizer.step()
if (batch_idx+1)%2 == 0:
finish_rate = (batch_idx* len(data) / len(train_X))*100
print('Train Epoch: %s'%str(epoch), #Train Epoch: 1
'[%d/%d]--'%((batch_idx* len(data)),len(train_X)), #[1450/60000]
'%.3f%%'%finish_rate, #0.024
'\t', 'acc: %.5f'%acc, #acc: 0.98000
' loss: %s'%loss.item()) #loss: 1.4811499118804932
def valid(model, test_loader):
model.eval()
test_loss = 0
acc = 0
y_true = []
y_pred = []
with torch.no_grad():
for data, target in test_loader:
output, h_state = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # 将一批的损失相加
output = output.argmax(dim = 1)
y_true.extend(target)
y_pred.extend(output)
acc = accuracy_score(y_true, y_pred)
#print(classification_report(y_true, y_pred, digits= 5))
test_loss /= len(test_X)
print('Valid set: Avg Loss:%s'%str(test_loss),
'\t', 'Avg acc:%s'%str(acc))
def test(model, test_loader):
model.eval()
y_true = []
y_pre = []
for data, target in test_loader:
output, h_state = model(data)
output = output.argmax(dim= 1)
y_true.extend(target)
y_pre.extend(output)
print(classification_report(y_true, y_pre, digits= 5))
for epoch in tqdm(range(1, 50)):
train(model, train_loader, optimizer, epoch)
valid(model, test_loader)
print('============================================================================')
print('**********************test set*************************')
test(model, test_loader)训练结果:
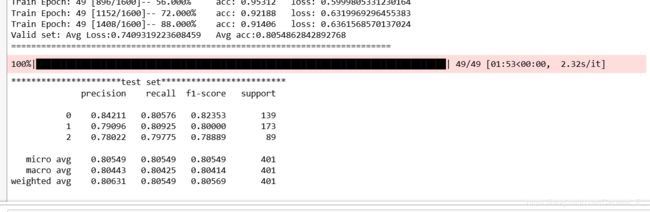
总结:
总的来说,利用两个不同的深度学习框架进行训练,两者结果相差并不是很大(要说明的是,两者训练和测试的数据并不是一样的)。但是利用pytorch,可以更好的了解和体会所用的模型。
在实验过程中,对于pytorch,我有一点很疑惑。同样一个模型,在两个深度学习框架中,所用的配置是完全一样的,在keras中,模型能够快速的拟合,达到一个高精度。但是在pytorch中,确是需要更多的epoch才能拟合。这是我非常困惑的地方,一度认为在模型构建中出了问题,如果有同学知道问题所在,请帮忙解惑,谢谢。