Google Inception Net网络解析和代码实现
Google Inception Net网络解析和代码实现
Google Inception Net采用了特殊的Inception Module构建网络,网络模型比VGG复杂,网络层数更深,但参数量比VGG少,性能也更好,在ILSVRC 2014的比赛中以较大优势获得了第一名,同年提出的VGG Net获得了第二名。从2014年网络被第一次提出到2016年,Inception共经历了四次改进和升级,并分别衍生了Inception V1-V4的版本。在几次改进迭代中,V3版本最能体现Inception网络的核心内容和技术创新,包括module的结构和各种trick,本文主要对Inception V3分别从网络结构、代码实现和技术亮点等几个方面进行解析。
1 Inception Module
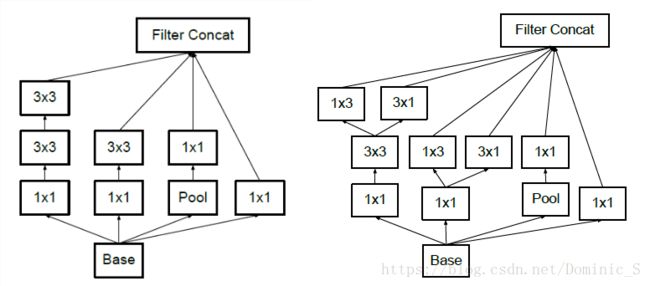
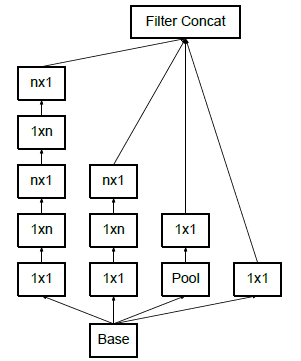
Inception中除了普通的卷积和池化操作外,还包含多个模块组,每个模块组中包含多个Inception Module(结构如图所示),Module在base net的基础上,分为4个分支(branch),通过设定好的卷积核(常用1x1卷积和3x3卷积)和池化,保持feature map的空间尺寸不变,通道数增加,对输入数据进行特征提取,在每个module结尾再将几个branch输出的feature map进行通道维度的拼接。对相同的base net使用不同的卷积和池化操作,增加了网络对不同尺度feature map的适应性,module结构也可以让网络的深度和宽度高效率的扩充,增强模型提取特征的能力,提升准确率。
Inception Module一般有4个分支:
- 分支1:一般是1x1卷积,进行简单特征抽象
- 分支2:一般是1x1卷积后在接分解的1xn和nx1卷积(factorized,后面解释),进行较复杂特征抽象
- 分支3:一般和分支2类似,但深度更深,进行较复杂特征抽象
- 分支4:一般是最大池化或平均池化
通过4种不同程度的特征抽象和变换,选择性保留不同层的高阶特征,最大程度丰富网络的表达能力
2 网络结构
| 操作 | kernel尺寸/步长 | 输出尺寸 |
|---|---|---|
| 卷积 | 3x3 / 2 | 149x149x32 |
| 卷积 | 3x3 / 1 | 147x147x32 |
| 卷积 | 3x3 / 1 | 147x147x64 |
| 最大池化 | 3x3 / 2 | 73x73x64 |
| 卷积 | 3x3 / 1 | 73x73x80 |
| 卷积 | 3x3 / 2 | 71x71x192 |
| 最大池化 | 3x3 / 1 | 35x35x192 |
| Inception模块组 | 3个Inception Module | 35x35x228 |
| Inception模块组 | 5个Inception Module | 17x17x768 |
| Inception模块组 | 3个Inception Module | 8x8x1280 |
| 平均池化 | 8x8 | 8x8x2048 |
| 线性 | logits | 1x1x2048 |
| softmax | 分类输出 | 1x1x1000 |
网络首先使用5个卷积层和2个最大池化层交替的普通结构,然后接上3个Inception模块组,每个模块组包含数量不等的Inception Module,最后再采用平均池化,将feature map的维度浓缩到只剩通道数一维并使用softmax进行最后的分类输出。整个网络通过卷积、池化和模块组对输入数据进行特征提取,图片空间尺寸不断缩小,通道数不断增加,将空间信息转化为高阶抽象的特征信息
3 代码实现
base网络: 进行feature map前期的特征提取,最终输出35x35x192,然后进入Inception block
def inception_v3_base(inputs,scepe=None):
with tf.variable_scope(scope,'InceptionV3',[inputs]):
with slim.arg_scope([slim.conv2d,slim.max_pool2d,slim.avg_pool2d],stride=1,padding='VALID'):
# 149 x 149 x 32
net = slim.conv2d(inputs,32,[3,3],stride=2,scope='Conv2d_1a_3x3')
# 147 x 147 x 32
net = slim.conv2d(net,32),[3,3],scope='Conv2d_2a_3x3')
# 147 x 147 x 64
net = slim.conv2d(net,64,[3,3],padding='SAME',scope='Conv2d_2b_3x3')
# 73 x 73 x 64
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_3a_3x3')
# 73 x 73 x 80
net = slim.conv2d(net, 80, [1, 1], scope= 'Conv2d_3b_1x1')
# 71 x 71 x 192.
net = slim.conv2d(net, 192, [3, 3], scope='Conv2d_4a_3x3',reuse=tf.AUTO_REUSE)
# 35 x 35 x 192
net = slim.max_pool2d(net, [3, 3], stride=2, scope= 'MaxPool_5a_3x3')
Inception block 1——module 1: Block 1中包含3个module,每个module都有4个分支,4个分支分别进行卷积或池化操作,不改变空间尺寸,只改变深度尺寸,然后使用tf.concat在深度维度进行拼接后,送入下一个module。
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
# mixed: 35 x 35 x 256.
end_point = 'Mixed_5b'
with tf.variable_scope(end_point):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, depth(64), [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, depth(48), [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, depth(64), [5, 5],
scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, depth(64), [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, depth(96), [3, 3],
scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, depth(96), [3, 3],
scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, depth(32), [1, 1],
scope='Conv2d_0b_1x1')
net = tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
end_points[end_point] = net
if end_point == final_endpoint: return net, end_points其它block和branch的代码实现与上面类似,每个branch并联,每个module是串联,每个block串联。
Logtis: 最终分类
with tf.variable_scope('Logits'):
kernel_size = _reduced_kernel_size_for_small_input(net, [8, 8])
net = slim.avg_pool2d(net, kernel_size, padding='VALID',scope='AvgPool_1a_{}x{}'.format(*kernel_size))
end_points['AvgPool_1a'] = net
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')
end_points['PreLogits'] = net
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, normalizer_fn=None, scope='Conv2d_1c_1x1')
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
end_points['Predictions'] = slim.softmax(logits, scope='Predictions')
return logits,end_pointsAuxiliary Logits: 辅助分类节点,通过end_points取到Mixed_6e(block2-module5的输出),并进行额外的卷积和池化并做分类,然后将此辅助分类结果以较小权重(0.3)加到最终的分类权重中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化
with slim.arg_scope([slim.conv2d,slim.max_pool2d,slim.avg_pool2d],stride=1,padding='SAME'):
aux_logits = end_points['Mixed_6e']
print(aux_logits.shape)
with tf.variable_scope('AuxLogits'):
aux_logits = slim.avg_pool2d(aux_logits,[5,5],stride=3,padding='VALID',scope='AvgPool_1a_5x5')
aux_logits = slim.conv2d(aux_logits,depth(128),[1,1],scope='Conv2d_1b_1x1') # (17-5)/3+1=5
kernel_size = _reduced_kernel_size_for_small_input(aux_logits, [5, 5])
aux_logits = slim.conv2d(aux_logits, depth(768), kernel_size, weights_initializer=trunc_normal(0.01),
padding='VALID', scope='Conv2d_2a_{}x{}'.format(*kernel_size))
aux_logits = slim.conv2d( aux_logits, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, weights_initializer=trunc_normal(0.001),
scope='Conv2d_2b_1x1')
aux_logits = tf.squeeze(aux_logits, [1, 2], name='SpatialSqueeze')
end_points['AuxLogits'] = aux_logits完整代码实现请参照这里(slim框架)
4 技术亮点和trick
1)参数量降低、性能提升(相对VGG)
参数越多的模型越复杂,训练所需数据越多,也越耗费计算资源。Inception在网络结尾处使用全局平均池化代替全连接层(AlexNet和VGG中将近90%的参数量集中在全连接层),并设计inception module的结构来堆叠组成大网络,通过不同的卷积核丰富特征抽提,不断缩减空间尺寸并增加通道数,提升网络表达能力
2)多处使用1x1卷积
1x1卷积核空间尺寸是1,但深度尺寸取决于上一层的feature map通道数,使用该卷积核的好处:
- 图片数据一般具有局部相关性,大卷积核将图片同一位置的信息提取并散布在不同通道,1x1卷积将这些相关性很高、在同一空间位置但不同通道的特征连接在一起,跨通道组织信息,提升网络的表达能力。
- 可对输出通道进行升维和降维
- 计算量小但能增加特征变换
3)Batch Normalization(BN)
Batch Normalization是在训练时将一个mini batch的数据进行标准化处理,使输出规范到N(0,1)正态分布。
由于网络在训练过程,数据的分布会逐渐发生偏移,逐渐脱离激活函数的敏感区域,在反向传播时梯度也变得不敏感,造成模型收敛速度慢,甚至不收敛。而使用BN可以将数据的分布强行拉回N(0,1)分布,使数据的训练更加有效,训练时学习率也可以增大,加快模型收敛速度,使训练时间大大缩短。
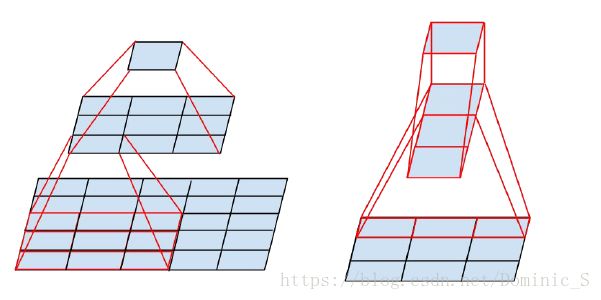
4)Factorization into small convolutions
保证感受野的前提下将一个较大的二维卷积核拆分小卷积核,可以降低参数的数量。图中左侧是Inception V2提出的思想,使用两个3x3的卷积核代替一个5x5的卷积核,得到的感受野和输出是一样的,但空间上,一个5x5卷积核参数是25,两个3x3卷积核参数是18,参数量降低了。既然大卷积核能由一些列小卷积核替代,那能否分解的更小些呢?图中右侧即为Inception V3提出的分解思路,将一个3x3卷积核分解成一个3x1和一个1x3的卷积核,进一步降低了参数量,而且该非对称的卷积结构拆分,结果比对称的拆分成几个相同的小卷积核效果更好,可以处理更多、更丰富的空间特征,增加特征的多样性。
5)Auxiliary Logits辅助分类累加到最终分类
Auxiliary Logits辅助分类节点的作用在上面已经结合代码说明,不在赘述。
参考文献
《Tensorflow实战》
《Rethinking the Inception Architecture for Computer Vision》