大数据开发利器:Hadoop(2)
大数据开发利器:Hadoop(2)
1. 准备工作
本文软件配置:
- VW12.5
- CentOS release 6.8 64位 lsb_release -a
- JDK 1.7.0_25 64位 java -version
- Hadoop 2.7.3 hadoop version
1.1 使用VW安装CentOS
这步骤网络教程较多,不在过多讲解。注意以下几点:
- 如果内存小于或等于4G,推荐双系统安装,内存大于4G,可使用虚拟机安装。
- 虚拟机设置过程中注意内存分配、客户机操作系统选择(本文选择CentOS64位)
- 安装过程中注意Root密码设置、硬盘分区、软件安装等。初次安装建议设置用户名为hadoop,下面就不用再添加hadoop用户了。
顺便吐槽一下,CentOS 6.8默中文字体非常丑,建议安装完成之后选择系统->首选项(Preferences)->外观(Appearance)修改一下。
1.2 修改主机名和用户名
为了统一开发环境,这里需要修改主机名和用户名。
① 添加用户
sudo useradd -m hadoop -s /bin/bash # 添加以hadoop为用户名的用户
sudo passwd hadoop # 设置密码这里需要输入root密码。
② 修改当前主机名
hostname # 查看当前主机名
vim /etc/syconfig/network # 使用Vim修改配置文件,但也可以使用类似windows的记事本gedit,操作简单一些
hostname hadoop第二步中修改HOSTNAME=hadoop
设置完成之后,注销当前用户,使用刚刚创建的hadoop用户登录。
1.3 配置网卡
① 进行配置
sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0修改如下:
DEVICE=eth0 # 默认,物理设备名
HWADDR=00:0C:29:23:83:95 # 默认,MAC地址
TYPE=Ethernet # 默认
UUID=xxxxx # 默认,全局统一标识符
ONBOOT=yes # 修改,[yes|no] 引导时是否激活网卡
NM_CONTROLLED=yes # 默认
BOOTPROTO=dhcp # 默认,[none|static|bootp|dhcp] (引导时不适用协议|静态分配|Bootp协议|DHCP协议)设置BOOTPROTO参数为dhcp是由于虚拟机采用NAT方式。
修改完成之后,重启网络服务,并测试是否能上网。
② 测试连接
service network restart
ping www.baidu.com③ 修改hosts
vim /etc/hosts在下面增加一行: ip地址 主机名
ip地址使用命令 ifconfig查看
例如:127.0.0.1 hadoop
1.4 配置SSH无密码连接
Hadoop并不是通过SSH协议进行数据传输,Hadoop仅仅时在启动和停止的时候需要主节点通过SSH协议将从节点上面的进程启动或停止。即不配置SSH对Hadoop的使用没有任何影响,只需要在启动和停止Hadoop的时候输入每个从节点的用户名的密码就行了,但是一旦集群的规模增大,这种方式不可取同时也不利于学习和调试。
① 在配置SSH无密码连接之前,先关闭防火墙。
service iptables stop
chkconfig iptables off #永久关闭防火墙
vim /etc/selinux/config设置SELINUX=disabled (原来为enforcing)
此步存疑,我使用该版本时未关闭但仍可完成安装并启动。不过大部分教程均提到,所以设置一下也无妨。
② 检查SSH是否安装
CentOS一般附带了SSH,所以首先检查一下是否安装。
sudo service sshd restart
rpm -qa | grep openssh
rpm -qa | grep rsync如果已经安装好SSH和rsync(一个远程数据同步工具,可通过LAN/WAN快速同步多台主机的文件),将会如下图所示。
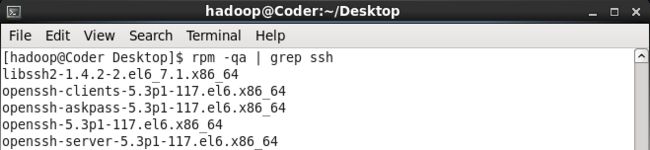
![]()
当然,如果没有安装,使用如下命令进行安装。
sudo yum install openssh-clients
sudo yum install openssh-server安装完成之后使用上面的方法进行验证。
④ 测试ssh是否可用
ssh localhost
首次登录,输入yes 和用户密码。
这样每次都需要输入密码,所以配置相应的SSH无密码登录更方便一些。
exit # 退出刚才的ssh localhost
cd ~/.ssh/ #ssh localhost之后会自动生成
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys #加入授权
chmod 600 ./authorized_keys如下图所示:
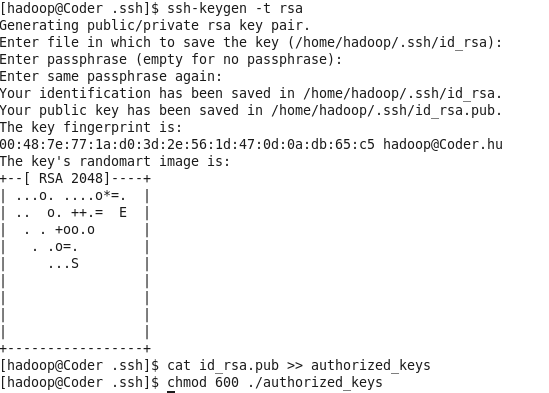
此时,再次输入ssh localhost命令,无需输入密码即可直接登录。如下图:

1.5 JAVA环境安装
CentOS一般预装了OpenJDK,这里我使用Oracle JDK。
① 卸载OpenJDK
rpm -qa | grep jdk # 查看是否安装OpenJDK
sudo yum -y remove xxx # 这里的xxx是上一个命令返回的结果② 安装OracleJDK
下载JDK包
这里在JAVA官网上下载tar包。目前可以下载1.8版本,本文使用1.7版本。解压JDK包
将tar包放置在/usr/local/目录下,并进行解压。(Linux 目录规则)
sudo tar -xvzf jdk-7u25-linux-x64.tar.gz # 解压
rm -f jdk-linux-* #删除压缩包- 配置环境变量
vim ~/.bashrc.bashrc只对单个用户生效,当登录以及每次打开新的shell时,该文件被读取。衍生阅读:设置Linux环境变量的区别
export JAVA_HOME=/usr/local/jdk1.7.0_25
export PATH=$PATH:$JAVA_HOME/bin修改环境变量后,执行命令。让环境变量立即生效。
source ~/.bashrc- 检查一下是否配置成功
java -version若如下图所示,则说明该配置成功。

2 伪分布式安装Hadoop 2.0
2.1 安装和配置
① 下载Hadoop2.0
在Hadoop官网上下载Hadoop binary版本。下载某个版本时有两种类型:source和binary。Source是源代码,而binary是编译好的。
下载时建议也下载hadoop-2.x.y.tar.gz.mds这个文件,用于检查hadoop-2.x.y.tar.gz的完整性。
cat hadoop-2.7.3.tar.gz.mds | grep 'MD5'
md5sum hadoop-2.7.3.tar.gz | tr "a-z" "A-Z" # 计算机MD5值,并转化为大写,方便比较。查看输出的两个值,如果存在差异,重新下载。如下图:

② 解压tar包
将hadoop安装在/usr/local目录下。
tar sudo tar -xvzf hadoop-2.7.3.tar.gz
# 这里可以改名或者做一个软连接,任选一种或不选
sudo mv hadoop-2.7.3 ./hadoop #方式1:改名
ln -s hadoop-2.7.3 hadoop # 方式2:软连接
sudo chown -R hadoop:hadoop hadoop #更改权限③ 设置环境变量
vim ~/.bashrcexport HADOOP_HOME=/usr/local/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binsource ~/.bashrc # 使配置立即生效④ 配置Hadoop配置文件
- hadoop-env.sh
这个文件配置hadoop的环境,比如namenode的大小等,由于属于初学阶段,暂时不必修改。
- core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop-2.7.3/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>hadoop.tmp.dir临时文件目录。
fs.defaultFS网页访问端口号
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop-2.7.3/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop-2.7.3/tmp/dfs/datavalue>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>dfs.replication设置HDFS文件副本数。
dfs.namenode.data.dir设置NameNode的元数据存放的本地文件路径。
dfs.datanode.data.dir设置DameNode的元数据存放的本地文件路径。
如果需要使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,就需要设置dfs.webhdfs.enabled为true,因为这些信息都是由namenode来保存的。
- mapreduce.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop:19888value>
property>
configuration>mapreduce.jobhistory.address配置jobhistory Server地址。
mapredcue.jobhistory.webapp.address配置jobhistory server web UI地址。
- yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>resourcemanager.addressname>
<value>hadoop:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>hadoop:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>hadoop:8031value>
property>
<property>
<name>resourcemanager.admin.addressname>
<value>hadoop:8033value>
property>
<property>
<name>resourcemanager.webapp.adressname>
<value>hadoop:8088value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
configuration>yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
resourcemanager.address:ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等。
yarn.resourcemanager.scheduler.address:ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。
yarn.resourcemanager.resource-tracker.address:ResourceManager对NodeManager暴露的地址.。ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。通过该地址向RM汇报心跳,领取任务等。
resourcemanager.admin.address:ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。
resourcemanager.webapp.adress:ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。
yarn.log-aggregation-enable如果配置错误,会显示 Aggregation is not enabled. Try the nodemanager at IP:HOST。
- slaves
# 默认为一个节点
localhost⑤ 配置完成之后,执行NameNode初始化
hadoop namenode format成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。如下图:
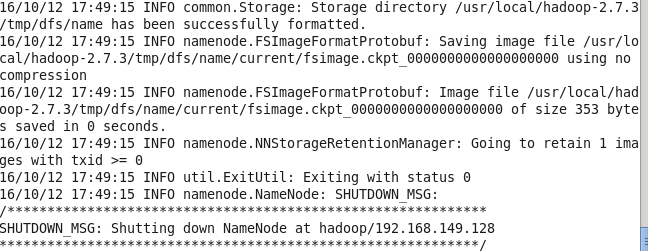
2.2 启动和测试hadoop
① 启动Hadoop
start-all.sh
jps #判断是否启动成功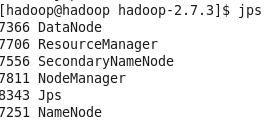
其中,若成功启动会列出如下进程:NameNode、DataNode、SencondarNameNode(以上HDFS进程)、ResourceManager、NodeManager(以上两项为YARN进程)。
若SencondarNameNode未启动,使用stop-dfs.sh关闭进程,然后尝试再次启动。如果没有NameNode或DataNode,则配置不成功,检查之前步骤,或通过启动日志排查原因。(查看logs目录下的log文件)
可能原因之一是多次format,将share/dfs目录下文件删除,重醒format。
stop-all.sh #关闭命令 ② 访问Web页面
可以访问http://localhost:50070查看NameNode和DataNode信息。
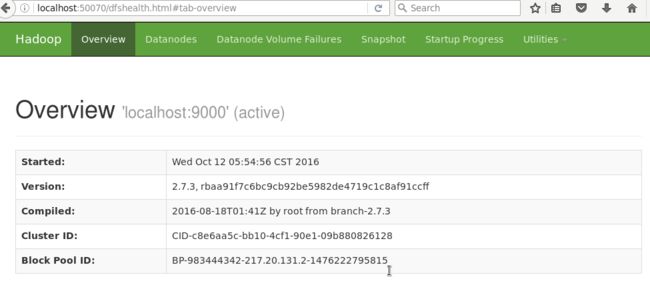
访问http://localhost:8088查看任务的运行情况(需要启动YARN)。
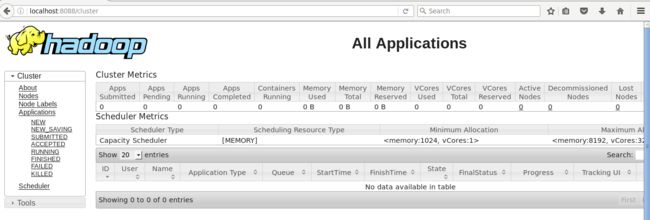
以下命令启动历史服务器,可以在web下查看任务运行。
mr-jobhistory-daemon.sh start historyserver # 启动jobhistory
yarn-damon.sh start historyserver #启动ApplicationHistoryServer访问http://localhost:19888查看jobhistory的运行情况。
2.3 运行Hadoop伪分布式实例
以一个MapReduce作业来实现单词计数的功能。
① 首先,创建相应的文本文件
# start-all.sh
cd ~
touch words
echo "data mining on data warehouse" >> words # 写入相同的两行语句
cat words
那么可以直观的发现,单词统计的结果为:
| 单词 | 词频 |
|---|---|
| data | 4 |
| mining | 2 |
| on | 2 |
| warehouse | 2 |
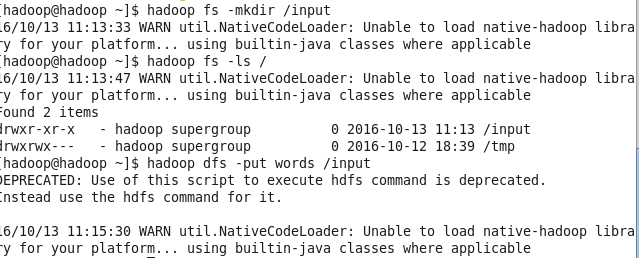
② 将文件上传到HDFS的指定目录下
hadoop fs -mkdir /input #在HDFS根目录下创建/input文件夹
hadoop fs -ls / #查看目录是否创建
hadoop dfs -put words /input #将文本文件上传到该目录下。如下图:
③ 运行MapReduce程序,并查看结果
cd /usr/local/hadoop-2.7.3
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
hdfs dfs -cat /output/part* # 查看结果
可以发现结果与预期相同。
④ 其他一些命令
hdfs dfs -get /output/part* output# 将结果取回本地,并命名为output
hdfs dfs -rm -r /output # Hadoop 运行程序时,输出目录不能存在,因此若要重新运行程序,需要删除结果目录可访问http://localhost:8088查看任务运行情况,如下图:
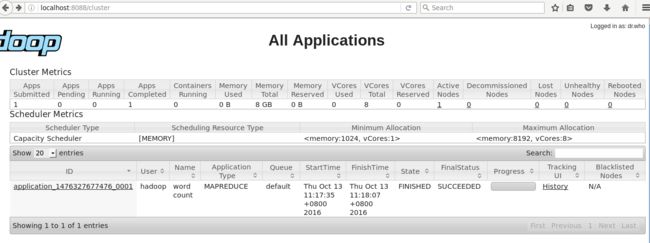
⑤ 备注
start-dfs.sh #仅启动NameNode和DataNode
start-yarn.sh # 启动Yarn启动 YARN 之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用 YARN 时,是 “mapred.LocalJobRunner” 在跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况。
如果不想启动 YARN,务必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用时改回来就行。否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的错误,这也是为何该配置文件初始文件名为 mapred-site.xml.template。
3. 总结
本节主要介绍了如何在CentOS上安装Hadoop2.0。基本完成了操作,但由于使用NAT模式和代理,虚拟机中配置静态IP方式不成功(无法ping通外网)。所以后续操作中直接访问http://IP地址:端口号的方式不成功。原因未知。
参考资料:
- 范东来-Hadoop海量数据处理-技术详解与项目实战。
- 林子雨-大数据技术原理与应用
- 网易云课堂