BERT后时代的应用(一)
2018年是NLP发展中十分重要的一年,ELMO、BERT、GPT等强大的预训练模型的出现,大幅度的提升了诸多NLP任务的效果。同时基于BERT的改进模型也如雨后春笋一般冒了出来,例如百度的ERNIE和清华大学的ERNIE等。那么作为一个没有卡的穷学生如何也赶上这波潮流,充分的借助预训练模型做一些工作呢?下面就针对使用BERT来解决某些NLP任务和IR任务的文章做一个简述,希望在明白如何将BERT和传统的任务相结合的同时,也为未来的研究工作提供一些思路。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Deep contextualized word representations
ERNIE: Enhanced Representation through Knowledge Integration
Improving Language Understanding by Generative Pre-Training
Universal Language Model Fine-tuning for Text Classification
关于BERT等预训练模型的报道大家肯定都看得很多了,下面是我看过的一些相关报道的整理。
预训练模型的一些参考资料
huggingface_pytorch-pretrained-bert_bert.ipynb
Bert时代的创新(应用篇):Bert在NLP各领域的应用进展
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT)
nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
[NLP自然语言处理]谷歌BERT模型深度解析
PyTorch-BERT
干货 | NLP中的十个预训练模型
【NLP】彻底搞懂BERT
当Bert遇上Keras:这可能是Bert最简单的打开姿势
如何评价 BERT 模型?
虽被BERT碾压,但还是有必要谈谈BERT时代与后时代的NLP
Building State-of-the-Art Language Models with BERT
详解BERT阅读理解
bert-github
pytorch-transformers
BERT应用于信息检索的Ad Hoc任务
文档检索任务的基本步骤可以看做如下的三步
- Step 1:使用信息检索工具或是检索算法(如BM25等)从文档集中获得最初候选文档
- Step 2:使用选择的函数对查询和文档的匹配性进行打分,按照得分降序排列
- Step 3:根据用户的设置,选择TOP-K返回
在《Simple Applications of BERT for Ad Hoc Document Retrieval》中作者希望借助BERT的强大的能力优化Step 2的处理,基本思想为:使用BERT来实现查询和文档的相关性判断,由于BERT本身对于输入长度的限制,对于长文档来说,作者所采用的的方式是单独的判断每个句子的得分,然后将所有句子的得分聚合为文档的得分。整个过程可以表述为:

其中在第三步中,根据BERT原始论文中双句分类实验的设置,查询和文档使用 [ [CLS],Q,[SEP],D,[SEP] ] 的方式进行拼接后送到BERT中。作者认为在长文档中最好的(得分最高的)句子或是段落在文档和查询的相关性方面起着重要的作用,因此最后的得分为文档得分和句子得分的线性插值,数学表达式为:

其中参数 a a a和 ω i \omega_{i} ωi通过实验中的交叉验证获得。这里只是粗粒度的考虑了查询与文档整体和其中某些句子的匹配程度,采用了线性插值的方式得到最后的衡量结果,如何设计更好的选择出长文档中最好的段落,以及如何选择出段落中最好的句子,也许会对效果的提升具有一定的帮助。
实验
- 数据集:TREC microblog(2011-2014) TREC、newswire test collections
- 损失函数:交叉熵
- 评估指标:average precision(AP)、precision at rank 30(P30)
- Baseline:QL、RM3、DRMM、DUET、K-NRM、PACRR、MP-HCNN、BiCNN
⾸先是 Microblog (数据集 TREC Microblog Tracks (2011–2014,tuning on 2011–2013 data, testing on 2014 data ) )的句级别检索匹配,⽤Anserini IR toolkit ⼯具先根据 query 召回 1000 条候选,然后候选和 query 拼接喂入 BERT 得到分数,之后取 BERT 分数和 Anserini 分数的线性插值,作为结果分数,重新排序。
然后在 newswire (数据集 TREC 2004 Robust Track 上⻓长⽚片段检索,由于文档⻓度通常会大于 BERT 预训练模型设计时所限制的最大长度(BERT’s maximum limit)512 个 token,本文会进⼀步将句子划分为固定⼤小的块。(newswire语料库包含250个主题,在实验中进行划分后统计发现大约平均文档43个句子,每个句子27个tokens)。其实大体步骤与句级别相同,不过会先在句级别 fine tune,之后,计算⽂档分句后各句分数,取 top n 加权,再插值重新排序。
实验结果如下所示:
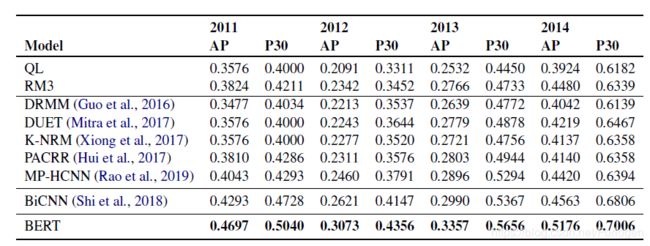
github : https://github.com/castorini/birch
感谢:不一样的雅兰酱对于文章的解读~
BERT应用于开放域的问答问题
基于上篇文章的延伸,作者将思想扩展到了NLP中的Open-Domian Question Answering中,同时在NAACL 2019上发表了《End-to-End Open-Domain Question Answering with BERTserini》。如果可以理解对于上篇文章的分析,那么对于这篇文章也可以轻松的理解。作者所提出的BERTserini 基本结构如下所示:
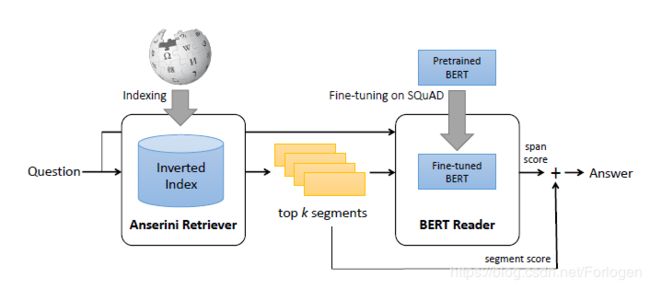
整个模型的架构可以分为Anserini retriever和BERT reader两个部分,前者需根据输入的查询从文章中选择出可能包含答案的片段,后者接收前面的输出判断出答案在片段中的具体范围。
其中在Anserini retriever中作者考虑了Article、Paragraph、Sentence三个粒度下的检索,并且同样使用了BM25作为ranking function。在BERT reader中使用的是BERT-base,所有的输入都被填充到384个tokens。整个评估的方式并没有变化,仍然使用线性插值的方式,数学表达式为: S = ( 1 − μ ) ⋅ S Anserini + μ ⋅ S B E R T S=(1-\mu) \cdot S_{\text { Anserini }}+\mu \cdot S_{\mathrm{BERT}} S=(1−μ)⋅S Anserini +μ⋅SBERT
实验
- 数据集:SQuAD
- 评估指标:exact match score(EM)、F1 score、recall(R)
实验结果如下所示:

从中可以看出使用BERT确实有一定的效果提升。另外作者还针对不同粒度下文档的检索效果做了评估,实验结果如下所示:
篇章检索在很大程度上弱于段落检索,作者认为原因在于文章篇幅长,且包含许多不相关的句子,从而分散了BERT reader的注意力。句子的表现是合理的,但不如段落,因为它们往往缺乏上下文,BERT reader难以准确识别答案的范围。综合来看,段落这个粒度的文本通常可以取得相对较好的效果。