案例分析-爬虫(51job网站的信息)
爬虫案例
- 爬虫介绍
- 技术说明
- jsoup使用介绍
- 代码实现
- 需求
- 数据封装
- 爬取数据
- 番外篇(获取图片)
- 番外篇(url编码和解码)
爬虫介绍
- 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
- 网络爬虫主要应用有两个方面,一方面用于检索,例如百度,谷歌等网站;另一方面用于爬取指定的有用数据(例如今天要使用的)。
技术说明
本次爬取的数据是51job网站的岗位数据,使用的是jsoup工具类
jsoup使用介绍
引入所需要的依赖(httpclient后面有使用到)
<!-- https://mvnrepository.com/artifact/commons-httpclient/commons-httpclient -->
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>
主要介绍了怎么使用jsoup获取对象,怎么定位节点,怎么获取节点数据。
package cn.pengpeng.day04.test;
import java.io.IOException;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* jsoup工具的使用 jsoup 解析html
*
* Document extends Element 父子关系
* Elements = new ArrayList();
* @author pengpeng
*
*/
public class TestJsoup {
public static void main(String[] args) throws Exception {
}
/**
* 获取值
* 1:标签对内的值 value text
* 2:属性值 获取 href .attr
*
*/
public static void getValue() {
// 获取数据
Document dom = getDom();
Elements select = dom.select("#resultList .el a");
for (Element element : select) {
// System.out.println(element.text());
System.out.println(element.attr("title"));
System.out.println("----------");
}
}
/**
* 定位分为三种 id,class,标签
*
* select css选择器 id形式查找--> #id class形式---> .class 标签形式---> a 复合使用 空格分开的是
* 前一个标签查找结果内再查找
*/
public static void findElement() {
// 定位
Document dom = getDom();
Element elementById = dom.getElementById("languagelist");
// System.out.println(elementById);
// 通过标签
Elements elementsByTag = dom.getElementsByTag("a");
/*
* for (Element element : elementsByTag) { System.out.println(element);
* }
*/
Elements elementsByClass = dom.getElementsByClass("checkbox");
/*
* for (Element element : elementsByClass) {
* System.out.println(element); System.out.println("---------"); }
*/
// 混合使用 通过id ---> class ---> tag ---> class
// 使用css选择器
// id形式查找--> #id class形式---> .class 标签形式---> a
// 复合使用 空格分开的是 前一个标签查找结果内再查找
Elements select = dom.select("#languagelist li a");
for (Element element : select) {
System.out.println(element);
System.out.println("------");
}
}
/**
* 获取网站的所有数据
*/
public static Document getDom() {
String uu = "https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=";
// 根据url解析成dom树
try {
URL url = new URL(uu);
Document dom = Jsoup.parse(url, 4000);
return dom;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
代码实现
需求
爬取51job网站的大数据相关的岗位

数据封装
把岗位数据封装到JavaBean里面
package cn.pengpeng.day04.bean;
/**
* 岗位数据的封装
* @author pengpeng
*
*/
public class JobBean {
private String jobName;
private String comName;
private String addr;
private String salary;
private String date;
public void set (String jobName, String comName, String addr, String salary, String date) {
this.jobName = jobName;
this.comName = comName;
this.addr = addr;
this.salary = salary;
this.date = date;
}
public String getJobName() {
return jobName;
}
public void setJobName(String jobName) {
this.jobName = jobName;
}
public String getComName() {
return comName;
}
public void setComName(String comName) {
this.comName = comName;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
public String getSalary() {
return salary;
}
public void setSalary(String salary) {
this.salary = salary;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
@Override
public String toString() {
return "JobBean [jobName=" + jobName + ", comName=" + comName + ", addr=" + addr + ", salary=" + salary
+ ", date=" + date + "]";
}
}
封装页面信息到pagebean里面
package cn.pengpeng.day04.bean;
import org.jsoup.nodes.Document;
/**
* 封装页面信息
* @author pengpeng
*/
public class PageBean {
private Document dom;
private String nextUrl;
private boolean hasNextPage;
public Document getDom() {
return dom;
}
public void setDom(Document dom) {
this.dom = dom;
}
public String getNextUrl() {
return nextUrl;
}
public void setNextUrl(String nextUrl) {
this.nextUrl = nextUrl;
}
public boolean isHasNextPage() {
return hasNextPage;
}
public void setHasNextPage(boolean hasNextPage) {
this.hasNextPage = hasNextPage;
}
@Override
public String toString() {
return "PageBean [dom=" + dom + ", nextUrl=" + nextUrl + ", hasNextPage=" + hasNextPage + "]";
}
}
爬取数据
爬取数据的主类主要有以下 几个方法
- getDom(String url) 通过url获取整个网站的html代码
- getJobs(PageBean pageBean) 通过PageBean(Dom)来获取岗位数据
- getNextUrl(PageBean pageBean) 判断是否有下一页,并且获取下一页的url
- main 提供开始爬取的网址,构造循环的逻辑
package cn.pengpeng.day04;
import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import cn.pengpeng.day04.bean.JobBean;
import cn.pengpeng.day04.bean.PageBean;
/**
* 爬取51job岗位信息
* @author pengpeng
*
*/
public class TestMain {
public static void main(String[] args) {
String startUrl = "https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=";
String endUrl = "https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1070.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=";
String testUrl = "https://search.51job.com/list/220200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=";
Document dom = getDom(testUrl);
PageBean pageBean = new PageBean();
pageBean.setDom(dom);
int count = 0;
while(true){
System.out.println("第"+(++count)+"页:");
List<JobBean> jobs = getJobs(pageBean);
//处理数据
for (JobBean jobBean : jobs) {
System.out.println(jobBean);
}
//获取下一页
getNextUrl(pageBean);
if(pageBean.isHasNextPage()){
String nextUrl = pageBean.getNextUrl();
Document dom2 = getDom(nextUrl);
pageBean.setDom(dom2);
}else{//没有下一页的时候
break;
}
//休息一下
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 获取下一页的的url,判断是否有下一页
* @param pageBean
*/
private static void getNextUrl(PageBean pageBean) {
Document dom = pageBean.getDom();
Elements select = dom.select(".bk");
Element element = select.get(1);
Elements select2 = element.select("a");
if(select2.size()==0){
pageBean.setHasNextPage(false);
}else{//有下一页
String nextUrl = select2.attr("href");
pageBean.setNextUrl(nextUrl);
pageBean.setHasNextPage(true);
}
}
/**
* 获取岗位数据
* @param pageBean
*
*/
private static List<JobBean> getJobs(PageBean pageBean) {
List<JobBean> list = new ArrayList<>();
Document dom = pageBean.getDom();
Elements select = dom.select("#resultList .el");
select.remove(0);//删除第一个数据节点
for (Element element : select) {
String jobName = element.select(".t1 a").attr("title");
String comName = element.select(".t2 a").attr("title");
String addr = element.select(".t3").text();
String salary = element.select(".t4").text();
String date = element.select(".t5").text();
JobBean jobBean = new JobBean();
jobBean.set(jobName, comName, addr, salary, date);
list.add(jobBean);
}
return list;
}
/**
* 获取网页所有数据
* @param url
* @return
*/
public static Document getDom(String url){
try {
Document dom = Jsoup.parse(new URL(url), 4000);
return dom;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
番外篇(获取图片)
jsoup是对html进行解析的工具,如果想获取图片,mp3,mp4等资源,可以使用HttpClient配合着jsoup使用下载图片等资源。
HttpClient下载图片如下使用方式:
package cn.pengpeng.day04.test;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.methods.GetMethod;
/**
* 怎么下载图片
* @author pengpeng
*
*/
public class TestJpg {
public static void main(String[] args) throws Exception {
String uri = "https://img04.51jobcdn.com/im/2016/logo/logo_20jubilee_116x46.png";
//可以类似于浏览器对象
HttpClient httpClient = new HttpClient();
//uri 资源统一定位 url也是uri的一种
HttpMethod method = new GetMethod(uri);
//执行,类似于浏览器访问指定的网址
httpClient.executeMethod(method);
//返回结果
InputStream inputStream = method.getResponseBodyAsStream();
FileOutputStream output = new FileOutputStream("d:/xxx.jpg");
byte[] b = new byte[1024];
int length = 0 ;
while((length = inputStream.read(b))!=-1){
output.write(b, 0, length);
}
output.flush();
output.close();
inputStream.close();
}
}
番外篇(url编码和解码)
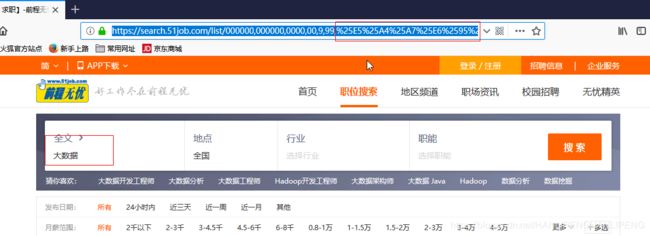
如下图我们搜索的大数据相关的工作,网址栏里面并没有显示与大数据相关的字样,其实是有体现的,只是进行了编码,下面我们来看下java怎么对中文进行编码的。
package cn.pengpeng.day04.test;
import java.net.URLDecoder;
import java.net.URLEncoder;
/**
* url的编码和解码
* 51job网站使用的两次进行对中文编码,所以解码的时候也需要两次解码
* @author pengpeng
*
*/
public class TestEncoding {
public static void main(String[] args) throws Exception {
//将中文进行编码
String firstEncode = URLEncoder.encode("大数据", "utf-8");
String secendaryEncode = URLEncoder.encode(firstEncode, "utf-8");
System.out.println("经过两次编码后的数据为:"+secendaryEncode);
//将编码后的数据进行解码
String firstDecode = URLDecoder.decode("%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE", "utf-8");
String secendaryDecode = URLDecoder.decode(firstDecode, "utf-8");
System.out.println("经过两次解码得到的数据:"+secendaryDecode);
}
}
本文由鹏鹏出品
更多文章请访问韩利鹏的博客