Hadoop安装部署
CDH5.15.0版本文档:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.0/
采用完全分布式的安装方式,使用系统为CentOS 6.10 64bit官方发行版,Hadoop使用hadoop-2.6.0-cdh5.15.1.tar.gz版本(点击即可下载,官网链接请放心使用),使用VMware Workstation搭建虚拟机,集群共配置三台虚拟机,每台虚拟机配置1core、4GB RAM、20GB ROM,请根据自己的物理主机参数更改虚拟机的配置,使用hsj用户安装Hadoop。
1. Linux系统配置
关闭防火墙,查看防火墙状态service iptables status,如果防火墙正在运行,则关闭防火墙service iptables stop,然后禁止防火墙开机启动chkconfig iptables off;如果防火墙没有启动,则直接禁止防火墙开机启动。
关闭selinux,修改配置文件vi /etc/sysconfig/selinux,将SELINUX=enforcing修改为SELINUX=disabled。
配置静态IP,修改配置文件vi etc/sysconfig/network-scripts/ifcfg-eth0,主要修改以下内容:

ONBOOT=yes表示启用网卡,BOOTPROTO=static表示使用静态IP,IPADDR配置IP地址,GATEWAY配置网关,NETMASK配置子网掩码,DNS配置域名解析器,IPADDR、GATEWAY、DNS请自行配置。配置完成后重启网络服务使配置生效service network restart。
配置hosts文件,修改位置文件vi /etc/hosts,添加对应的IP与主机名,格式为:IP hostname,每一个IP hostname占用一行。hostname可以修改文件来配置vi /etc/sysconfig/network,将HOSTNAME变量修改为要设置的主机名,保存并退出即可。
配置SSH免密登录,确认是否安装ssh,rpm -qa | grep openssh,如果没有安装则安装
![]()
安装完成后,需要修改配置文件vi /etc/ssh/sshd_config,去掉以下三项的注释,RSAAuthentication yes表示启用 RSA 认证,PubkeyAuthentication yes表示启用公钥私钥配对认证方式,AuthorizedKeysFile .ssh/authorized_keys表示授权文件路径。

切换到hsj账号,使用命令生成公钥密钥:ssh-keygen -t rsa,默认生成路径为:~/home/hsj/.ssh。生成授权文件cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys,并修改授权文件权限为600:chmod 600 ~/.ssh/authorized_keys。使用scp命令将.ssh文件夹发送到其他主机上确保.ssh文件夹权限为700,授权文件权限为600。当然也可以在每一台主机上都生成一遍公钥密钥对,然后将其它两台机器上的公钥都追加到授权文件里面。
请支持原创:https://blog.csdn.net/HSJ_knight/article/details/88562756
我也是个萌新,如果有什么地方不对请指出
2. HDFS安装部署
zookeeper之前已经安装完毕,所以在此就不再赘述,点击跳转,也可以参考网络上其它zookeeper安装配置教程。
将hadoop-2.6.0-cdh5.15.1.tar.gz解压到合适的地方,这里解压到/home/hsj/bigdata/目录里,并建立软连接到/home/hsj/目录里,ln -s /home/hsj/bigdata/zookeeper-3.4.5-cdh5.15.0 /home/hsj/hadoop,/home/hsj/bigdata_info/用于存放数据、日志等信息。完成之后开始配置Hadoop,使用个人用户hsj进行配置。

配置hadoop-env.sh,vi /home/hsj/hadoop/etc/hadoop/hadoop-env.sh,主要修改export JAVA_HOME、export HADOOP_LOG_DIR、export HADOOP_PID_DIR三条;JAVA_HOME配置jdk的路径,HADOOP_LOG_DIR配置HDFS的日志路径,HADOOP_PID_DIR配置Hadoop进程号存放目录。
配置core-site.xml(点击查看core-site.xml官方文档),vi ~/home/hsj/hadoop/etc/hadoop/core-site.xml,修改以下三项的值:

fs.defaultFS,配置文件系统的名称;ha.zookeeper.quorum,配置用于高可用的zookeeper集群,值的形式为IP:port,以逗号隔开;hadoop.tmp.dir,配置临时文件目录。
配置hdfs-site.xml(点击查看hdfs-site.xml官方文档),vi /home/hsj/hadoop/etc/hadoop/hdfs-site.xml,修改以下内容的值:
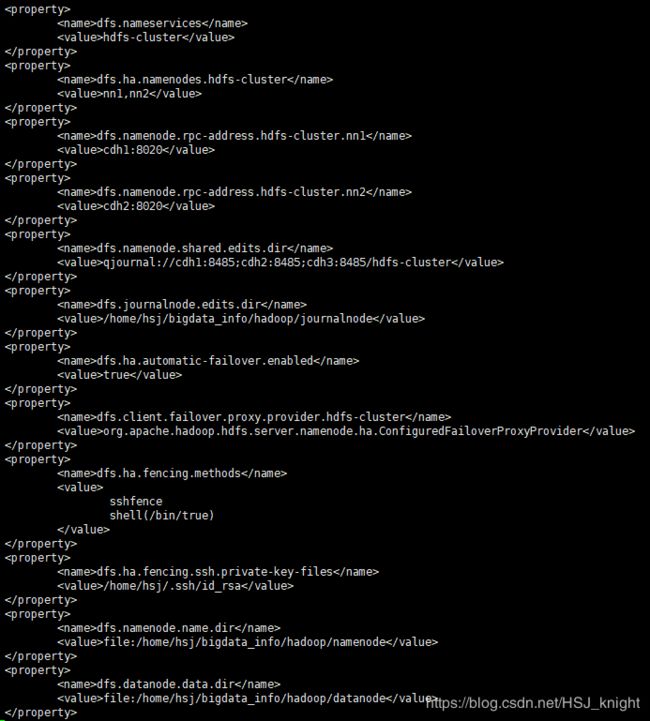
配置slaves,vi /home/hsj/hadoop/etc/hadoop/slaves,添加所有的DataNode机器的IP或者hostname,每个机器占用一行。
配置环境变量,vi /home/hsj/.bash_profile,添加Hadoop环境变量,如下所示:
![]()
添加完成之后使用source /home/hsj/.bash_profile使环境变量生效。
完成以上配置后将修改后的文件发送到其它两台主机上的,确认无误后可以开始启动HDFS。
初始化HDFS,首次启动HDFS时需要初始化,首先在任意一台NameNode机器上执行命令hdfs zkfc -formatZK,在zookeeper中注册HDFS,成功时如下图所示:

然后在每一台JournalNode机器上执行命令hadoop-daemon.sh start journalnode启动JN;在任意NameNode主机上执行命令hdfs namenode -format初始化NN,成功时如下图所示:

然后执行命令hadoop-deamon.sh start namenode启动这个已经初始化好的NN;然后再另一台NameNode机器上执行命令hdfs namenode -bootstrpStandby拷贝初始好的NN的元数据,成功时如下图所示:

执行命令hadoop-deamon.sh start namenode启动该NN;然后在两个NN机器上执行命令hadoop-daemon.sh start zkfc启动ZKFC;最后在每一台DataNode机器上执行命令hadoop-daemon.sh start datanode启动DN,至此,所有进程启动完毕,使用jps命令可以查看相关进程,以下左边为NN机器上的进程,左边为DN机器上的进程:
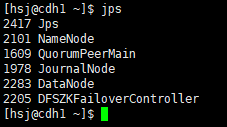
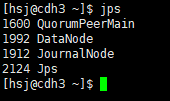
关闭HDFS使用命令stop-dfs.sh,之后再启动HDFS使用命令start-dfs.sh。
请支持原创:https://blog.csdn.net/HSJ_knight/article/details/88562756
我也是个萌新,如果有什么地方不对请指出
3. YARN安装部署
配置yarn-env.sh,vi /home/hsj/hadoop/etc/hadoop/yarn-env.sh,修改的主要内容如下:

配置yarn-site.xml(点击查看yarn-site.xml官方文档),vi /home/hsj/hadoop/etc/hadoop/yarn-site.xml,主要修改内容如下:
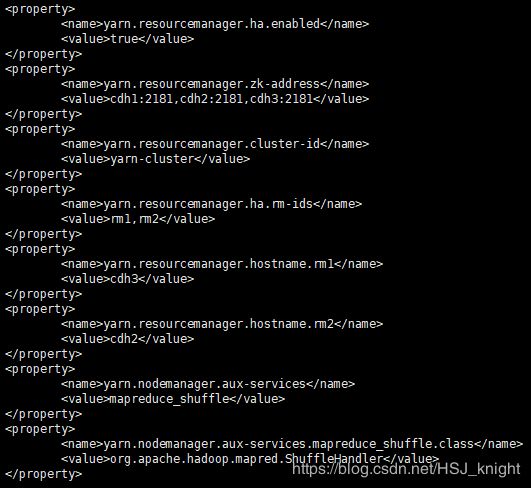
配置mapred-env.sh,vi /home/hsj/hadoop/etc/hadoop/mapred-env.sh,添加以下内容:
![]()
配置mapred-site.xml(点击查看mapred-site.xml官方文档),vi /home/hsj/hadoop/etc/hadoop/mapred-site.xml,添加以下内容:
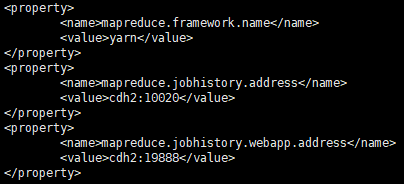
以上配置完成后将修改的文件发送到相应的其它机器上,然后就可以启动YARN了,在任意Resourcemanager机器上执行命令start-yarn.sh;在另一台RM机器上执行命令yarn-deamon.sh start resourcemanager启动另一个RM;在JobHistory机器上执行命令mr-jobhistory-daemon.sh start historyserver启动JobHistoryServer。关闭YARN使用命令stop-yarn.sh。
到此Hadoop基本的配置就完成可以正常使用了,可以运行一个自带的WordCount来测试一下。在HDFS创建一个文件夹用于保存原始数据,hadoop fs -mkdir /wc_input,然后本地创建一个测试用文本文件test.txt,添加一些英文单词进去,然后将其上传到HDFS上,hadoop fs -put ~/test.txt /wc_input。

使用命令运行Hadoop自带的wordcount案例, hadoop jar /home/hsj/hadoop/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.15.0.jar wordcount /wc_input /output,/wc_input和/output均为HDFS上的文件夹,前者里面存放当原始数据,后者必须未创建,成功之后如下所示:

生成的结果文件在HDFS上,可以使用命令查看结果内容hadoop fs -cat /output/part-r-00000

请支持原创:https://blog.csdn.net/HSJ_knight/article/details/88562756
我也是个萌新,如果有什么地方不对请指出